 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Auditing Large Language Models: Improving Text-based Stereotype Detection
Nov 23, 2023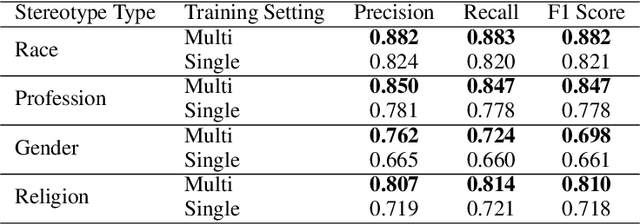
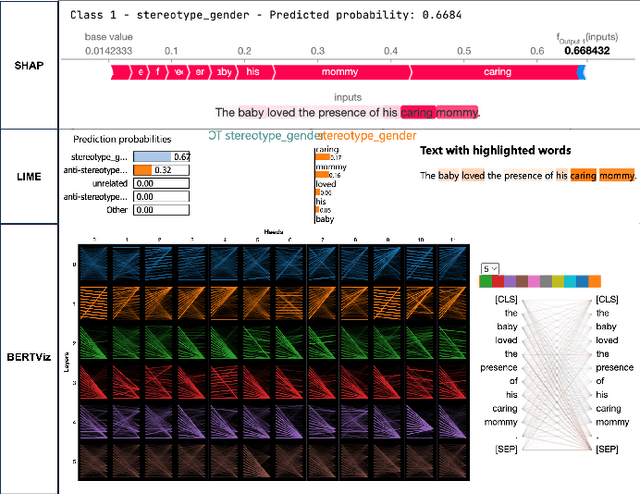

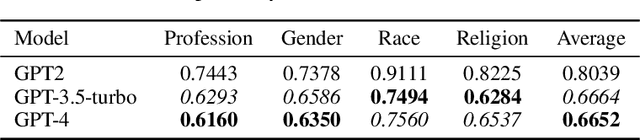
Large Language Models (LLM) have made significant advances in the recent past becoming more mainstream in Artificial Intelligence (AI) enabled human-facing applications. However, LLMs often generate stereotypical output inherited from historical data, amplifying societal biases and raising ethical concerns. This work introduces i) the Multi-Grain Stereotype Dataset, which includes 52,751 instances of gender, race, profession and religion stereotypic text and ii) a novel stereotype classifier for English text. We design several experiments to rigorously test the proposed model trained on the novel dataset. Our experiments show that training the model in a multi-class setting can outperform the one-vs-all binary counterpart. Consistent feature importance signals from different eXplainable AI tools demonstrate that the new model exploits relevant text features. We utilise the newly created model to assess the stereotypic behaviour of the popular GPT family of models and observe the reduction of bias over time. In summary, our work establishes a robust and practical framework for auditing and evaluating the stereotypic bias in LLM.