 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditing Large Language Models for Enhanced Text-Based Stereotype Detection and Probing-Based Bias Evaluation
Apr 02, 2024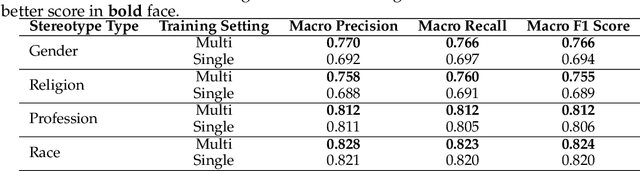

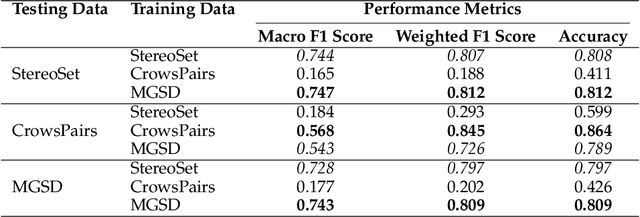

Recent advancements in Large Language Models (LLMs) have significantly increased their presence in human-facing Artificial Intelligence (AI) applications. However, LLMs could reproduce and even exacerbate stereotypical outputs from training data. This work introduces the Multi-Grain Stereotype (MGS) dataset, encompassing 51,867 instances across gender, race, profession, religion, and stereotypical text, collected by fusing multiple previously publicly available stereotype detection datasets. We explore different machine learning approaches aimed at establishing baselines for stereotype detection, and fine-tune several language models of various architectures and model sizes, presenting in this work a series of stereotypes classifier models for English text trained on MGS. To understand whether our stereotype detectors capture relevant features (aligning with human common sense) we utilise a variety of explanainable AI tools, including SHAP, LIME, and BertViz, and analyse a series of example cases discussing the results. Finally, we develop a series of stereotype elicitation prompts and evaluate the presence of stereotypes in text generation tasks with popular LLMs, using one of our best performing previously presented stereotypes detectors. Our experiments yielded several key findings: i) Training stereotype detectors in a multi-dimension setting yields better results than training multiple single-dimension classifiers.ii) The integrated MGS Dataset enhances both the in-dataset and cross-dataset generalisation ability of stereotype detectors compared to using the datasets separately. iii) There is a reduction in stereotypes in the content generated by GPT Family LLMs with newer versions.
Eliciting Personality Traits in Large Language Models
Feb 15, 2024



Large Language Models (LLMs) are increasingly being utilized by both candidates and employers in the recruitment context. However, with this comes numerous ethical concerns, particularly related to the lack of transparency in these "black-box" models. Although previous studies have sought to increase the transparency of these models by investigating the personality traits of LLMs, many of the previous studies have provided them with personality assessments to complete. On the other hand, this study seeks to obtain a better understanding of such models by examining their output variations based on different input prompts. Specifically, we use a novel elicitation approach using prompts derived from common interview questions, as well as prompts designed to elicit particular Big Five personality traits to examine whether the models were susceptible to trait-activation like humans are, to measure their personality based on the language used in their outputs. To do so, we repeatedly prompted multiple LMs with different parameter sizes, including Llama-2, Falcon, Mistral, Bloom, GPT, OPT, and XLNet (base and fine tuned versions) and examined their personality using classifiers trained on the myPersonality dataset. Our results reveal that, generally, all LLMs demonstrate high openness and low extraversion. However, whereas LMs with fewer parameters exhibit similar behaviour in personality traits, newer and LMs with more parameters exhibit a broader range of personality traits, with increased agreeableness, emotional stability, and openness. Furthermore, a greater number of parameters is positively associated with openness and conscientiousness. Moreover, fine-tuned models exhibit minor modulations in their personality traits, contingent on the dataset. Implications and directions for future research are discussed.
Towards Auditing Large Language Models: Improving Text-based Stereotype Detection
Nov 23, 2023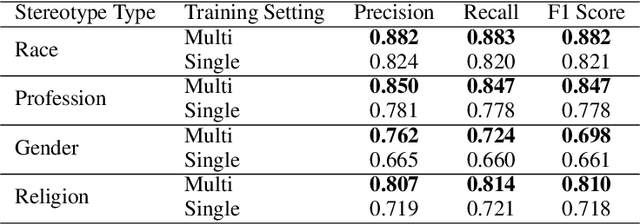
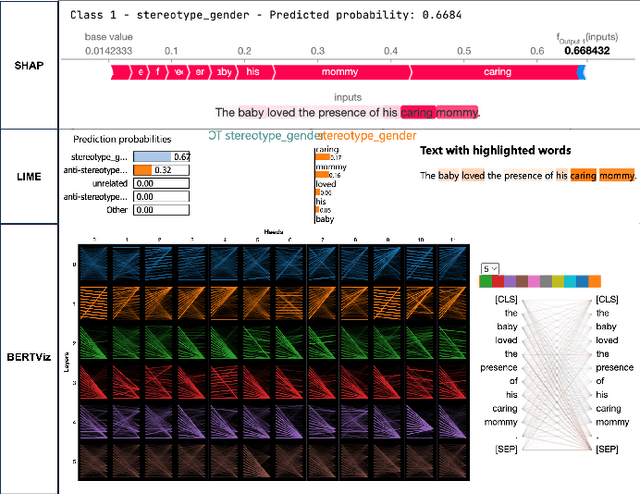

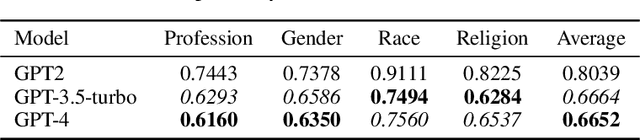
Large Language Models (LLM) have made significant advances in the recent past becoming more mainstream in Artificial Intelligence (AI) enabled human-facing applications. However, LLMs often generate stereotypical output inherited from historical data, amplifying societal biases and raising ethical concerns. This work introduces i) the Multi-Grain Stereotype Dataset, which includes 52,751 instances of gender, race, profession and religion stereotypic text and ii) a novel stereotype classifier for English text. We design several experiments to rigorously test the proposed model trained on the novel dataset. Our experiments show that training the model in a multi-class setting can outperform the one-vs-all binary counterpart. Consistent feature importance signals from different eXplainable AI tools demonstrate that the new model exploits relevant text features. We utilise the newly created model to assess the stereotypic behaviour of the popular GPT family of models and observe the reduction of bias over time. In summary, our work establishes a robust and practical framework for auditing and evaluating the stereotypic bias in LLM.