 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Approach to Scalable and Automatic Topic-Controlled Question Generation in Education
Jan 09, 2025



The development of Automatic Question Generation (QG) models has the potential to significantly improve educational practices by reducing the teacher workload associated with creating educational content. This paper introduces a novel approach to educational question generation that controls the topical focus of questions. The proposed Topic-Controlled Question Generation (T-CQG) method enhances the relevance and effectiveness of the generated content for educational purposes. Our approach uses fine-tuning on a pre-trained T5-small model, employing specially created datasets tailored to educational needs. The research further explores the impacts of pre-training strategies, quantisation, and data augmentation on the model's performance. We specifically address the challenge of generating semantically aligned questions with paragraph-level contexts, thereby improving the topic specificity of the generated questions. In addition, we introduce and explore novel evaluation methods to assess the topical relatedness of the generated questions. Our results, validated through rigorous offline and human-backed evaluations, demonstrate that the proposed models effectively generate high-quality, topic-focused questions. These models have the potential to reduce teacher workload and support personalised tutoring systems by serving as bespoke question generators. With its relatively small number of parameters, the proposals not only advance the capabilities of question generation models for handling specific educational topics but also offer a scalable solution that reduces infrastructure costs. This scalability makes them feasible for widespread use in education without reliance on proprietary large language models like ChatGPT.
MLFEF: Machine Learning Fusion Model with Empirical Formula to Explore the Momentum in Competitive Sports
Feb 19, 2024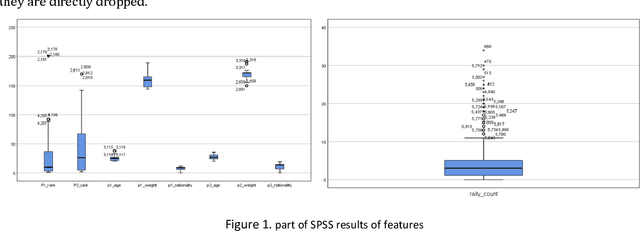

Tennis is so popular that coaches and players are curious about factors other than skill, such as momentum. This article will try to define and quantify momentum, providing a basis for real-time analysis of tennis matches. Based on the tennis Grand Slam men's singles match data in recent years, we built two models, one is to build a model based on data-driven, and the other is to build a model based on empirical formulas. For the data-driven model, we first found a large amount of public data including public data on tennis matches in the past five years and personal information data of players. Then the data is preprocessed, and feature engineered, and a fusion model of SVM, Random Forrest algorithm and XGBoost was established. For the mechanism analysis model, important features were selected based on the suggestions of many tennis players and enthusiasts, the sliding window algorithm was used to calculate the weight, and different methods were used to visualize the momentum. For further analysis of the momentum fluctuation, it is based on the popular CUMSUM algorithm in the industry as well as the RUN Test, and the result shows the momentum is not random and the trend might be random. At last, the robustness of the fusion model is analyzed by Monte Carlo simulation.
Human Health Indicator Prediction from Gait Video
Dec 25, 2022



Body Mass Index (BMI), age, height and weight are important indicators of human health conditions, which can provide useful information for plenty of practical purposes, such as health care, monitoring and re-identification. Most existing methods of health indicator prediction mainly use front-view body or face images. These inputs are hard to be obtained in daily life and often lead to the lack of robustness for the models, considering their strict requirements on view and pose. In this paper, we propose to employ gait videos to predict health indicators, which are more prevalent in surveillance and home monitoring scenarios. However, the study of health indicator prediction from gait videos using deep learning was hindered due to the small amount of open-sourced data. To address this issue, we analyse the similarity and relationship between pose estimation and health indicator prediction tasks, and then propose a paradigm enabling deep learning for small health indicator datasets by pre-training on the pose estimation task. Furthermore, to better suit the health indicator prediction task, we bring forward Global-Local Aware aNd Centrosymmetric Encoder (GLANCE) module. It first extracts local and global features by progressive convolutions and then fuses multi-level features by a centrosymmetric double-path hourglass structure in two different ways. Experiments demonstrate that the proposed paradigm achieves state-of-the-art results for predicting health indicators on MoVi, and that the GLANCE module is also beneficial for pose estimation on 3DPW.
Metric Learning-enhanced Optimal Transport for Biochemical Regression Domain Adaptation
Feb 16, 2022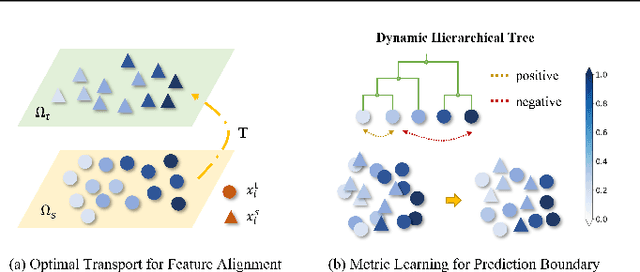
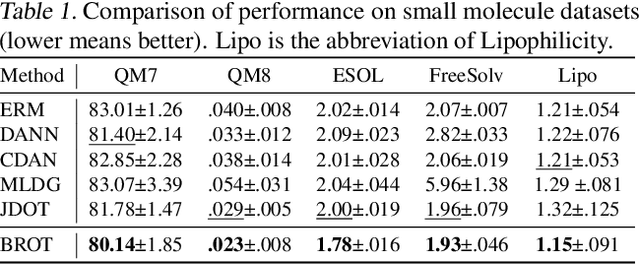
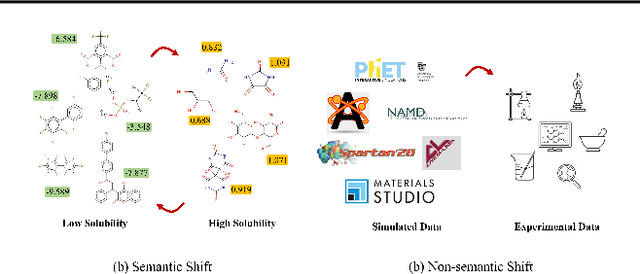
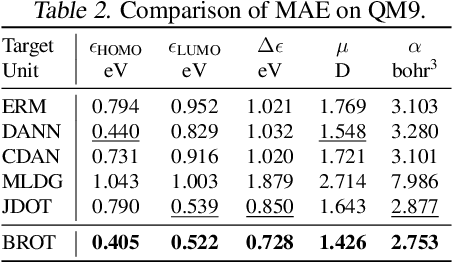
Generalizing knowledge beyond source domains is a crucial prerequisite for many biomedical applications such as drug design and molecular property prediction. To meet this challenge, researchers have used optimal transport (OT) to perform representation alignment between the source and target domains. Yet existing OT algorithms are mainly designed for classification tasks. Accordingly, we consider regression tasks in the unsupervised and semi-supervised settings in this paper. To exploit continuous labels, we propose novel metrics to measure domain distances and introduce a posterior variance regularizer on the transport plan. Further, while computationally appealing, OT suffers from ambiguous decision boundaries and biased local data distributions brought by the mini-batch training. To address those issues, we propose to couple OT with metric learning to yield more robust boundaries and reduce bias. Specifically, we present a dynamic hierarchical triplet loss to describe the global data distribution, where the cluster centroids are progressively adjusted among consecutive iterations. We evaluate our method on both unsupervised and semi-supervised learning tasks in biochemistry. Experiments show the proposed method significantly outperforms state-of-the-art baselines across various benchmark datasets of small molecules and material crystals.