 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Cross-Lingual Transfer in Bilingual Models Human-Like? A Study with Overlapping Word Forms in Dutch and English
Apr 08, 2026Bilingual speakers show cross-lingual activation during reading, especially for words with shared surface form. Cognates (friends) typically lead to facilitation, whereas interlingual homographs (false friends) cause interference or no effect. We examine whether cross-lingual activation in bilingual language models mirrors these patterns. We train Dutch-English causal Transformers under four vocabulary-sharing conditions that manipulate whether (false) friends receive shared or language-specific embeddings. Using psycholinguistic stimuli from bilingual reading studies, we evaluate the models through surprisal and embedding similarity analyses. The models largely maintain language separation, and cross-lingual effects arise primarily when embeddings are shared. In these cases, both friends and false friends show facilitation relative to controls. Regression analyses reveal that these effects are mainly driven by frequency rather than consistency in form-meaning mapping. Only when just friends share embeddings are the qualitative patterns of bilinguals reproduced. Overall, bilingual language models capture some cross-linguistic activation effects. However, their alignment with human processing seems to critically depend on how lexical overlap is encoded, possibly limiting their explanatory adequacy as models of bilingual reading.
Shifting Focus with HCEye: Exploring the Dynamics of Visual Highlighting and Cognitive Load on User Attention and Saliency Prediction
May 02, 2024


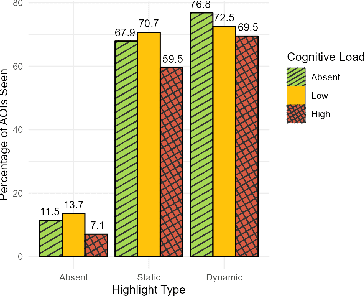
Visual highlighting can guide user attention in complex interfaces. However, its effectiveness under limited attentional capacities is underexplored. This paper examines the joint impact of visual highlighting (permanent and dynamic) and dual-task-induced cognitive load on gaze behaviour. Our analysis, using eye-movement data from 27 participants viewing 150 unique webpages reveals that while participants' ability to attend to UI elements decreases with increasing cognitive load, dynamic adaptations (i.e., highlighting) remain attention-grabbing. The presence of these factors significantly alters what people attend to and thus what is salient. Accordingly, we show that state-of-the-art saliency models increase their performance when accounting for different cognitive loads. Our empirical insights, along with our openly available dataset, enhance our understanding of attentional processes in UIs under varying cognitive (and perceptual) loads and open the door for new models that can predict user attention while multitasking.
* 18 pages, 9 Figures, Conference: ACM Symposium on Eye Tracking Research & Applications (ETRA); Journal: Proc. ACM Hum.-Comput. Interact., Vol. 8, No. ETRA, Article 236. Publication date: May 2024
Improving fit to human reading times via temperature-scaled surprisal
Nov 15, 2023Past studies have provided broad support for that words with lower predictability (i.e., higher surprisal) require more time for comprehension by using large language models (LLMs) to simulate humans' cognitive load. In general, these studies have implicitly assumed that the probability scores from LLMs are accurate, ignoring the discrepancies between human cognition and LLMs from this standpoint. Inspired by the concept of probability calibration, we are the first work to focus on the probability distribution for human reading simulation. We propose to use temperature-scaled surprisal, a surprisal calculated by shaped probability, to be the predictor of human reading times. Our results across three corpora consistently revealed that such a surprisal can drastically improve the prediction of reading times. Setting the temperature to be approximately 2.5 across all models and datasets can yield up to an 89% of increase in delta log-likelihood in our setting. We also propose a calibration metric to quantify the possible human-likeness bias. Further analysis was done and provided insights into this phenomenon.
Tackling Hallucinations in Neural Chart Summarization
Aug 01, 2023Hallucinations in text generation occur when the system produces text that is not grounded in the input. In this work, we tackle the problem of hallucinations in neural chart summarization. Our analysis shows that the target side of chart summarization training datasets often contains additional information, leading to hallucinations. We propose a natural language inference (NLI) based method to preprocess the training data and show through human evaluation that our method significantly reduces hallucinations. We also found that shortening long-distance dependencies in the input sequence and adding chart-related information like title and legends improves the overall performance.