 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Interdisciplinary Outlook on Large Language Models for Scientific Research
Nov 03, 2023
In this paper, we describe the capabilities and constraints of Large Language Models (LLMs) within disparate academic disciplines, aiming to delineate their strengths and limitations with precision. We examine how LLMs augment scientific inquiry, offering concrete examples such as accelerating literature review by summarizing vast numbers of publications, enhancing code development through automated syntax correction, and refining the scientific writing process. Simultaneously, we articulate the challenges LLMs face, including their reliance on extensive and sometimes biased datasets, and the potential ethical dilemmas stemming from their use. Our critical discussion extends to the varying impacts of LLMs across fields, from the natural sciences, where they help model complex biological sequences, to the social sciences, where they can parse large-scale qualitative data. We conclude by offering a nuanced perspective on how LLMs can be both a boon and a boundary to scientific progress.
Local and Global Explainability Metrics for Machine Learning Predictions
Feb 23, 2023

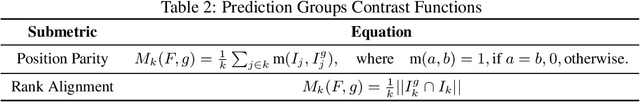

Rapid advancements in artificial intelligence (AI) technology have brought about a plethora of new challenges in terms of governance and regulation. AI systems are being integrated into various industries and sectors, creating a demand from decision-makers to possess a comprehensive and nuanced understanding of the capabilities and limitations of these systems. One critical aspect of this demand is the ability to explain the results of machine learning models, which is crucial to promoting transparency and trust in AI systems, as well as fundamental in helping machine learning models to be trained ethically. In this paper, we present novel quantitative metrics frameworks for interpreting the predictions of classifier and regressor models. The proposed metrics are model agnostic and are defined in order to be able to quantify: i. the interpretability factors based on global and local feature importance distributions; ii. the variability of feature impact on the model output; and iii. the complexity of feature interactions within model decisions. We employ publicly available datasets to apply our proposed metrics to various machine learning models focused on predicting customers' credit risk (classification task) and real estate price valuation (regression task). The results expose how these metrics can provide a more comprehensive understanding of model predictions and facilitate better communication between decision-makers and stakeholders, thereby increasing the overall transparency and accountability of AI systems.