 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Action Sequences: Discovering Correlated Samples
Paper and Code
Oct 17, 2020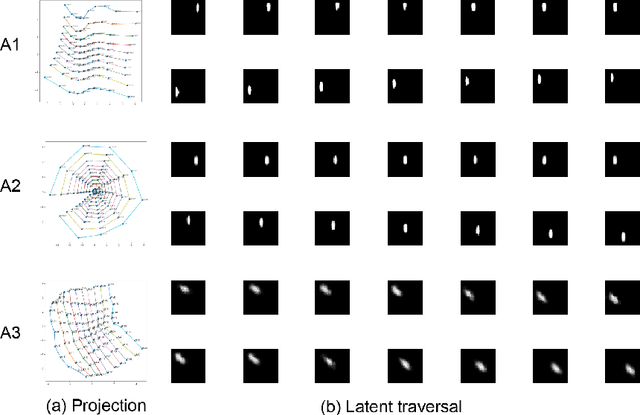



Disentanglement is a highly desirable property of representation due to its similarity with human's understanding and reasoning. This improves interpretability, enables the performance of down-stream tasks, and enables controllable generative models. However, this domain is challenged by the abstract notion and incomplete theories to support unsupervised disentanglement learning. We demonstrate the data itself, such as the orientation of images, plays a crucial role in disentanglement and instead of the factors, and the disentangled representations align the latent variables with the action sequences. We further introduce the concept of disentangling action sequences which facilitates the description of the behaviours of the existing disentangling approaches. An analogy for this process is to discover the commonality between the things and categorizing them. Furthermore, we analyze the inductive biases on the data and find that the latent information thresholds are correlated with the significance of the actions. For the supervised and unsupervised settings, we respectively introduce two methods to measure the thresholds. We further propose a novel framework, fractional variational autoencoder (FVAE), to disentangle the action sequences with different significance step-by-step. Experimental results on dSprites and 3D Chairs show that FVAE improves the stability of disentanglement.