 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable EEG-to-Image Generation with Semantic Prompts
Jul 09, 2025Decoding visual experience from brain signals offers exciting possibilities for neuroscience and interpretable AI. While EEG is accessible and temporally precise, its limitations in spatial detail hinder image reconstruction. Our model bypasses direct EEG-to-image generation by aligning EEG signals with multilevel semantic captions -- ranging from object-level to abstract themes -- generated by a large language model. A transformer-based EEG encoder maps brain activity to these captions through contrastive learning. During inference, caption embeddings retrieved via projection heads condition a pretrained latent diffusion model for image generation. This text-mediated framework yields state-of-the-art visual decoding on the EEGCVPR dataset, with interpretable alignment to known neurocognitive pathways. Dominant EEG-caption associations reflected the importance of different semantic levels extracted from perceived images. Saliency maps and t-SNE projections reveal semantic topography across the scalp. Our model demonstrates how structured semantic mediation enables cognitively aligned visual decoding from EEG.
Inter-Beat Interval Estimation with Tiramisu Model: A Novel Approach with Reduced Error
Jul 01, 2021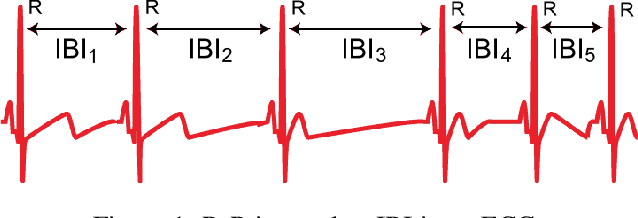
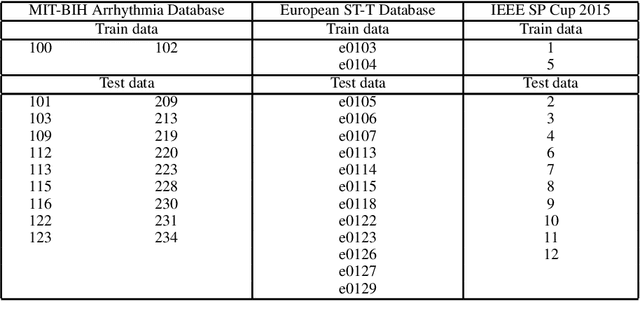
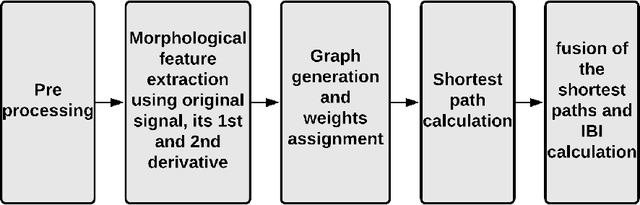
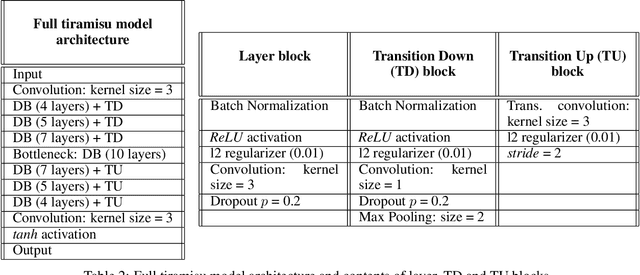
Inter-beat interval (IBI) measurement enables estimation of heart-rate variability (HRV) which, in turns, can provide early indication of potential cardiovascular diseases. However, extracting IBIs from noisy signals is challenging since the morphology of the signal is distorted in the presence of the noise. Electrocardiogram (ECG) of a person in heavy motion is highly corrupted with noise, known as motion-artifact, and IBI extracted from it is inaccurate. As a part of remote health monitoring and wearable system development, denoising ECG signals and estimating IBIs correctly from them have become an emerging topic among signal-processing researchers. Apart from conventional methods, deep-learning techniques have been successfully used in signal denoising recently, and diagnosis process has become easier, leading to accuracy levels that were previously unachievable. We propose a deep-learning approach leveraging tiramisu autoencoder model to suppress motion-artifact noise and make the R-peaks of the ECG signal prominent even in the presence of high-intensity motion. After denoising, IBIs are estimated more accurately expediting diagnosis tasks. Results illustrate that our method enables IBI estimation from noisy ECG signals with SNR up to -30dB with average root mean square error (RMSE) of 13 milliseconds for estimated IBIs. At this noise level, our error percentage remains below 8% and outperforms other state of the art techniques.
NPT-Loss: A Metric Loss with Implicit Mining for Face Recognition
Mar 05, 2021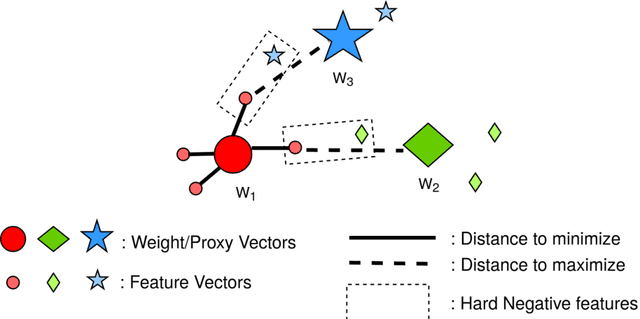

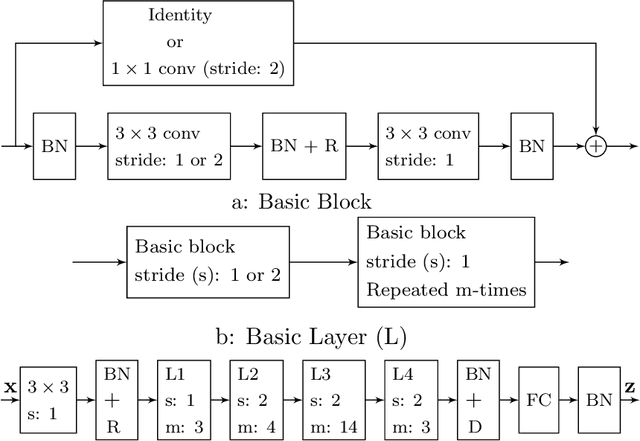
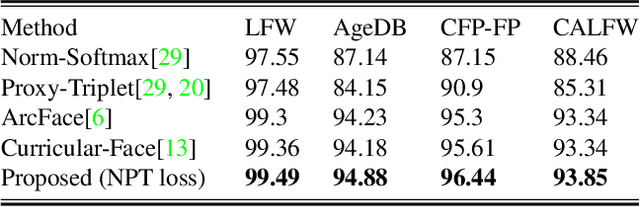
Face recognition (FR) using deep convolutional neural networks (DCNNs) has seen remarkable success in recent years. One key ingredient of DCNN-based FR is the appropriate design of a loss function that ensures discrimination between various identities. The state-of-the-art (SOTA) solutions utilise normalised Softmax loss with additive and/or multiplicative margins. Despite being popular, these Softmax+margin based losses are not theoretically motivated and the effectiveness of a margin is justified only intuitively. In this work, we utilise an alternative framework that offers a more direct mechanism of achieving discrimination among the features of various identities. We propose a novel loss that is equivalent to a triplet loss with proxies and an implicit mechanism of hard-negative mining. We give theoretical justification that minimising the proposed loss ensures a minimum separability between all identities. The proposed loss is simple to implement and does not require heavy hyper-parameter tuning as in the SOTA solutions. We give empirical evidence that despite its simplicity, the proposed loss consistently achieves SOTA performance in various benchmarks for both high-resolution and low-resolution FR tasks.
Design, Characterization, and Control of a Size Adaptable In-pipe Robot for Water Distribution Systems
Jan 17, 2021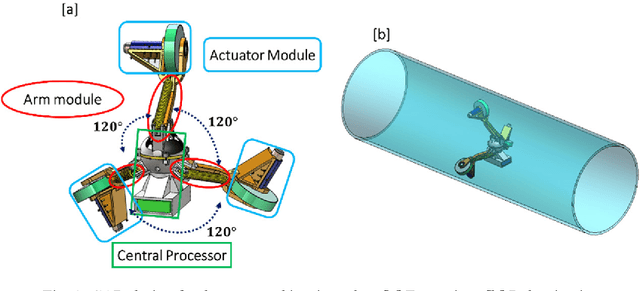
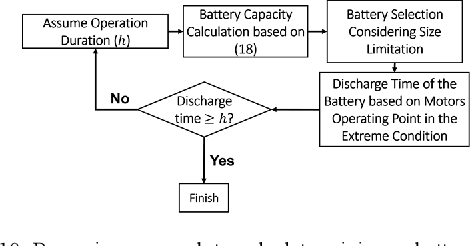
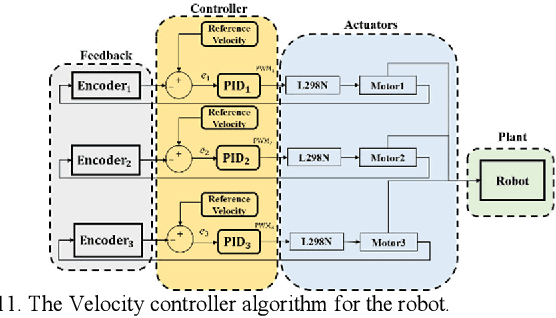
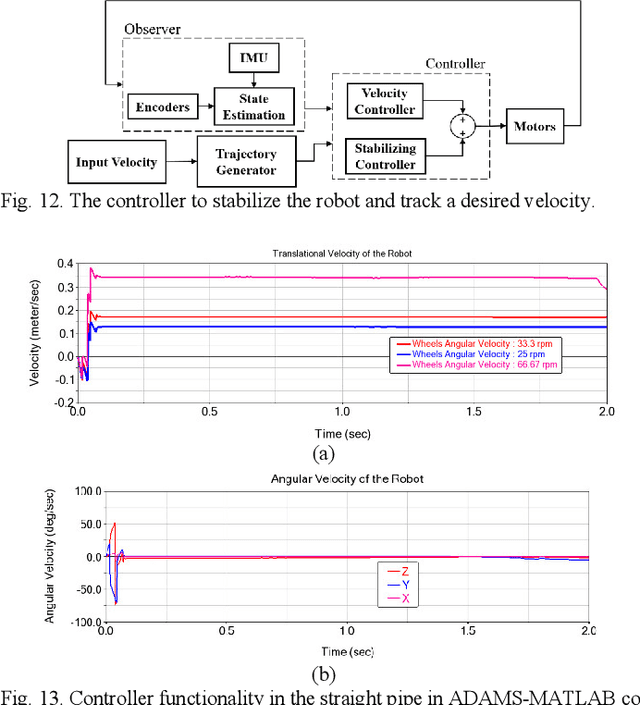
Leak detection and water quality monitoring are requirements and challenging tasks in Water Distribution Systems (WDS). In-line robots are designed for this aim. In our previous work, we designed an in-pipe robot [1]. In this research, we present the design of the central processor, characterize and control the robot based on the condition of operation in a highly pressurized environment of pipelines with the presence of high-speed flow. To this aim, an extreme operation condition is simulated with computational fluid dynamics (CFD) and the spring mechanism is characterized to ensure sufficient stabilizing force during operation based on the extreme operating condition. Also, an end-to-end method is suggested for power considerations for our robot that calculates minimum battery capacity and operation duration in the extreme operating condition. Finally, we design a novel LQR-PID based controller based on the system auxiliary matrices that retain the robot stability inside the pipeline against disturbances and uncertainties during operation. The ADAMS-MATLAB co-simulation of the robot-controller shows the rotational velocity with -4 degree/sec and +3 degree/sec margin around x, y, and z axes while the system tracks different desired velocities in pipelines (i.e. 0.12m/s, 0.17m/s, and 0.35m/s). Also, experimental results for four iterations in a 14-inch diameter PVC pipe show that the controller brings initial values of stabilizing states to zero and oscillate around it with a margin of 2 degrees and the system tracks desired velocities of 0.1m/s, 0.2m/s, 0.3m/s, and 0.35m/s in which makes the robot dexterous in uncertain and highly disturbed the environment of pipelines during operation.
A Flatter Loss for Bias Mitigation in Cross-dataset Facial Age Estimation
Oct 26, 2020
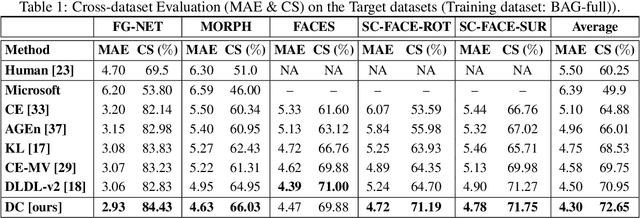
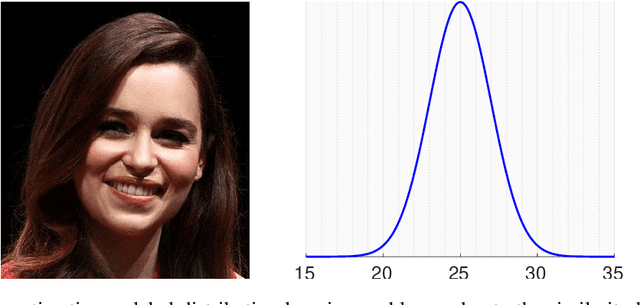
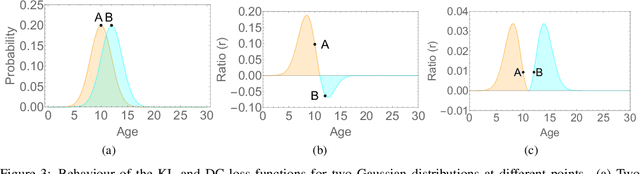
The most existing studies in the facial age estimation assume training and test images are captured under similar shooting conditions. However, this is rarely valid in real-world applications, where training and test sets usually have different characteristics. In this paper, we advocate a cross-dataset protocol for age estimation benchmarking. In order to improve the cross-dataset age estimation performance, we mitigate the inherent bias caused by the learning algorithm itself. To this end, we propose a novel loss function that is more effective for neural network training. The relative smoothness of the proposed loss function is its advantage with regards to the optimisation process performed by stochastic gradient descent (SGD). Compared with existing loss functions, the lower gradient of the proposed loss function leads to the convergence of SGD to a better optimum point, and consequently a better generalisation. The cross-dataset experimental results demonstrate the superiority of the proposed method over the state-of-the-art algorithms in terms of accuracy and generalisation capability.
A Convolutional Baseline for Person Re-Identification Using Vision and Language Descriptions
Feb 20, 2020

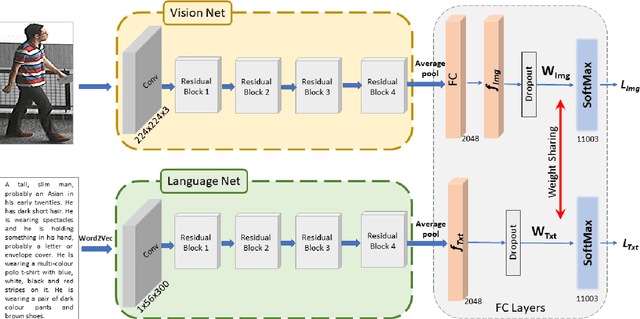

Classical person re-identification approaches assume that a person of interest has appeared across different cameras and can be queried by one of the existing images. However, in real-world surveillance scenarios, frequently no visual information will be available about the queried person. In such scenarios, a natural language description of the person by a witness will provide the only source of information for retrieval. In this work, person re-identification using both vision and language information is addressed under all possible gallery and query scenarios. A two stream deep convolutional neural network framework supervised by cross entropy loss is presented. The weights connecting the second last layer to the last layer with class probabilities, i.e., logits of softmax layer are shared in both networks. Canonical Correlation Analysis is performed to enhance the correlation between the two modalities in a joint latent embedding space. To investigate the benefits of the proposed approach, a new testing protocol under a multi modal ReID setting is proposed for the test split of the CUHK-PEDES and CUHK-SYSU benchmarks. The experimental results verify the merits of the proposed system. The learnt visual representations are more robust and perform 22\% better during retrieval as compared to a single modality system. The retrieval with a multi modal query greatly enhances the re-identification capability of the system quantitatively as well as qualitatively.