 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Interaction Modelling in Vision Transformer via Super Tokens
Paper and Code
Nov 25, 2021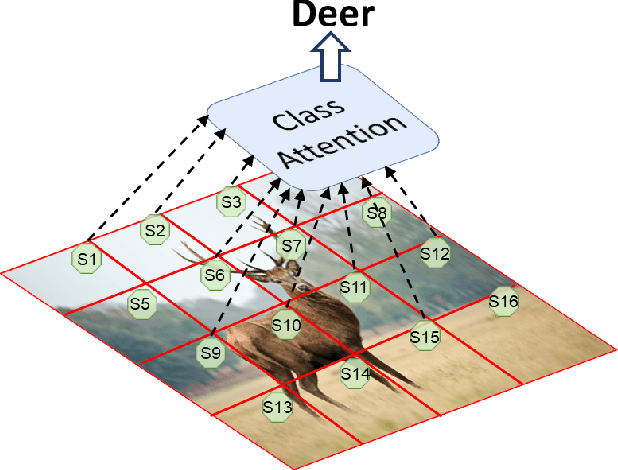
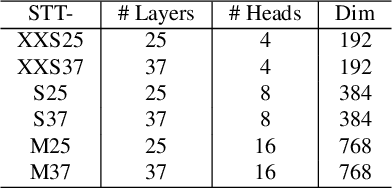
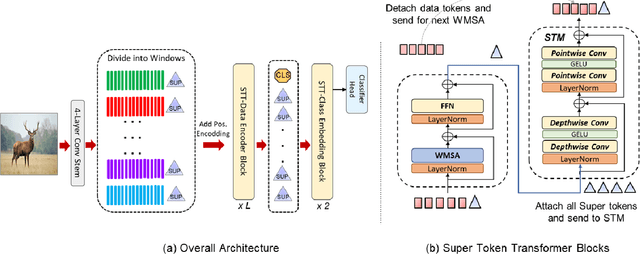
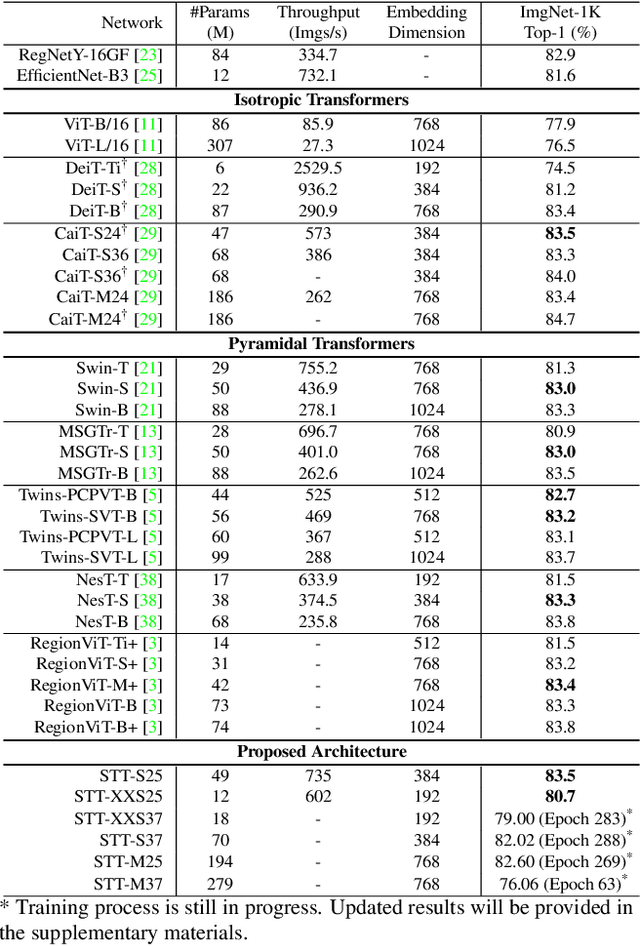
With the popularity of Transformer architectures in computer vision, the research focus has shifted towards developing computationally efficient designs. Window-based local attention is one of the major techniques being adopted in recent works. These methods begin with very small patch size and small embedding dimensions and then perform strided convolution (patch merging) in order to reduce the feature map size and increase embedding dimensions, hence, forming a pyramidal Convolutional Neural Network (CNN) like design. In this work, we investigate local and global information modelling in transformers by presenting a novel isotropic architecture that adopts local windows and special tokens, called Super tokens, for self-attention. Specifically, a single Super token is assigned to each image window which captures the rich local details for that window. These tokens are then employed for cross-window communication and global representation learning. Hence, most of the learning is independent of the image patches $(N)$ in the higher layers, and the class embedding is learned solely based on the Super tokens $(N/M^2)$ where $M^2$ is the window size. In standard image classification on Imagenet-1K, the proposed Super tokens based transformer (STT-S25) achieves 83.5\% accuracy which is equivalent to Swin transformer (Swin-B) with circa half the number of parameters (49M) and double the inference time throughput. The proposed Super token transformer offers a lightweight and promising backbone for visual recognition tasks.