 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMC-SSL0.0: Towards Multi-Concept Self-Supervised Learning
Paper and Code
Nov 30, 2021
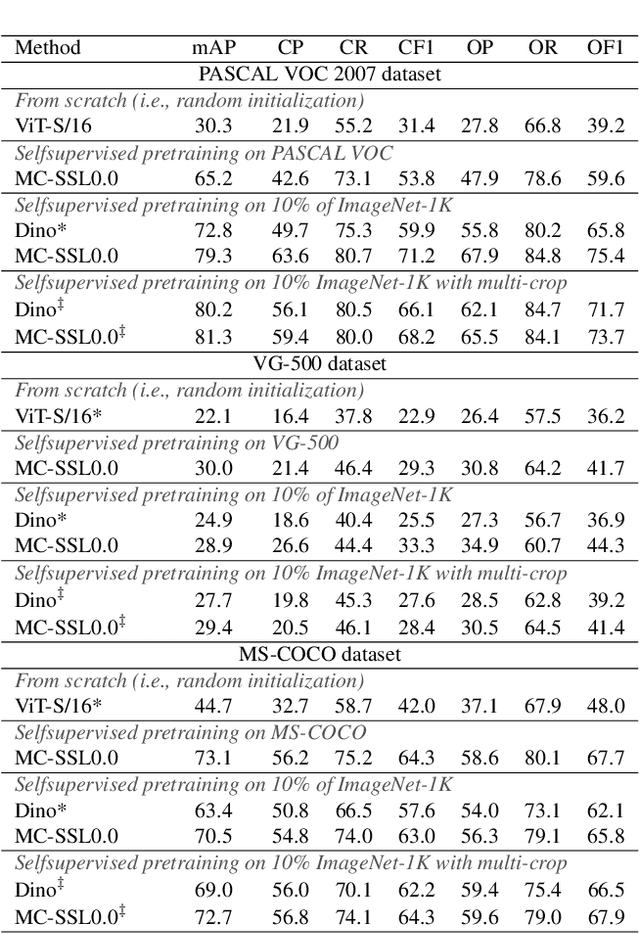
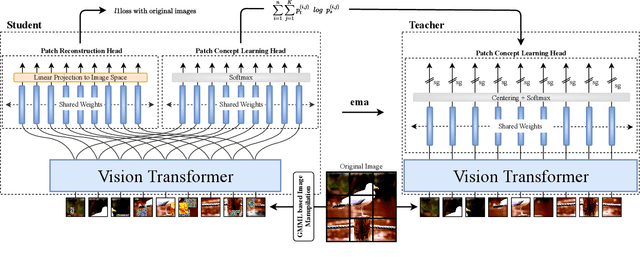
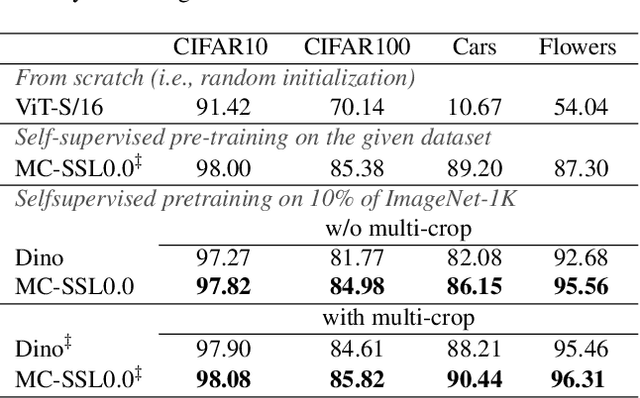
Self-supervised pretraining is the method of choice for natural language processing models and is rapidly gaining popularity in many vision tasks. Recently, self-supervised pretraining has shown to outperform supervised pretraining for many downstream vision applications, marking a milestone in the area. This superiority is attributed to the negative impact of incomplete labelling of the training images, which convey multiple concepts, but are annotated using a single dominant class label. Although Self-Supervised Learning (SSL), in principle, is free of this limitation, the choice of pretext task facilitating SSL is perpetuating this shortcoming by driving the learning process towards a single concept output. This study aims to investigate the possibility of modelling all the concepts present in an image without using labels. In this aspect the proposed SSL frame-work MC-SSL0.0 is a step towards Multi-Concept Self-Supervised Learning (MC-SSL) that goes beyond modelling single dominant label in an image to effectively utilise the information from all the concepts present in it. MC-SSL0.0 consists of two core design concepts, group masked model learning and learning of pseudo-concept for data token using a momentum encoder (teacher-student) framework. The experimental results on multi-label and multi-class image classification downstream tasks demonstrate that MC-SSL0.0 not only surpasses existing SSL methods but also outperforms supervised transfer learning. The source code will be made publicly available for community to train on bigger corpus.