 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMNeRV: A Multilayer Neural Representation for Videos
Jul 10, 2024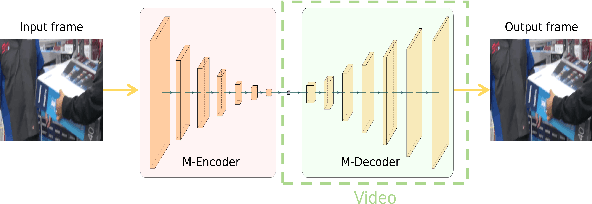
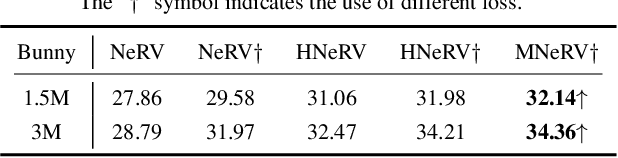
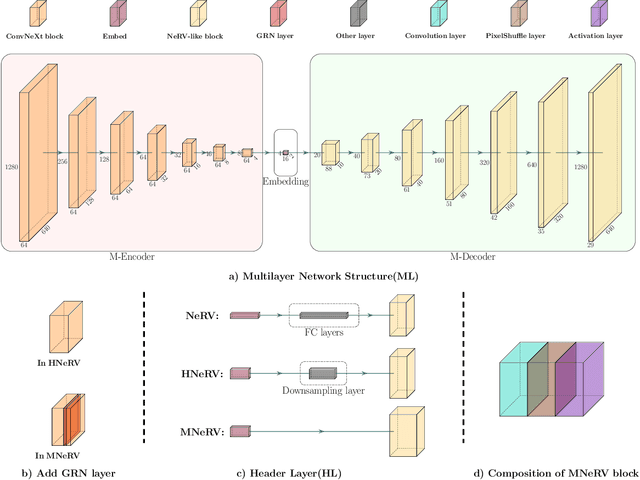
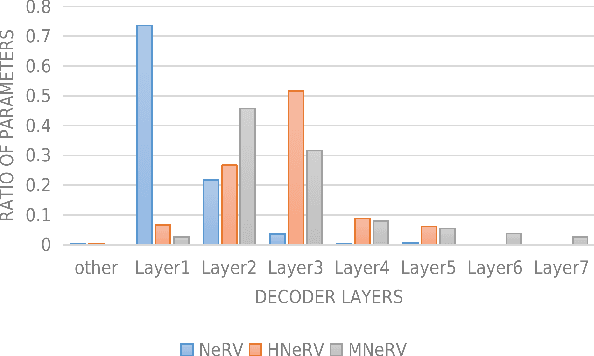
As a novel video representation method, Neural Representations for Videos (NeRV) has shown great potential in the fields of video compression, video restoration, and video interpolation. In the process of representing videos using NeRV, each frame corresponds to an embedding, which is then reconstructed into a video frame sequence after passing through a small number of decoding layers (E-NeRV, HNeRV, etc.). However, this small number of decoding layers can easily lead to the problem of redundant model parameters due to the large proportion of parameters in a single decoding layer, which greatly restricts the video regression ability of neural network models. In this paper, we propose a multilayer neural representation for videos (MNeRV) and design a new decoder M-Decoder and its matching encoder M-Encoder. MNeRV has more encoding and decoding layers, which effectively alleviates the problem of redundant model parameters caused by too few layers. In addition, we design MNeRV blocks to perform more uniform and effective parameter allocation between decoding layers. In the field of video regression reconstruction, we achieve better reconstruction quality (+4.06 PSNR) with fewer parameters. Finally, we showcase MNeRV performance in downstream tasks such as video restoration and video interpolation. The source code of MNeRV is available at https://github.com/Aaronbtb/MNeRV.
Monocular Depth Estimation with Sharp Boundary
Oct 12, 2021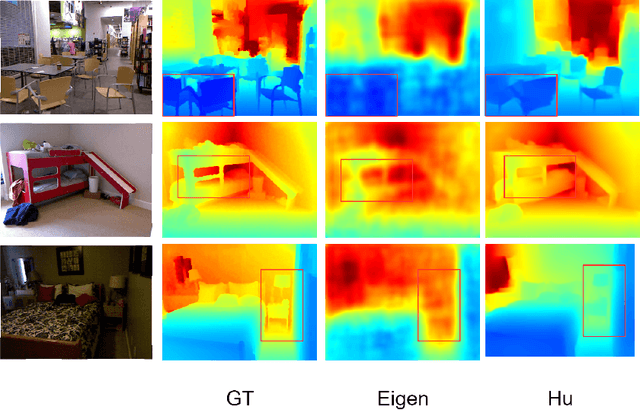
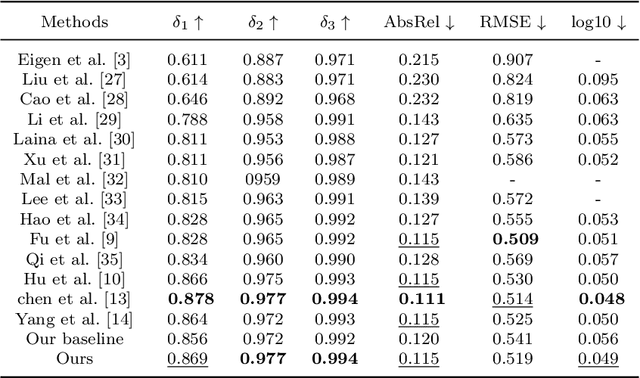

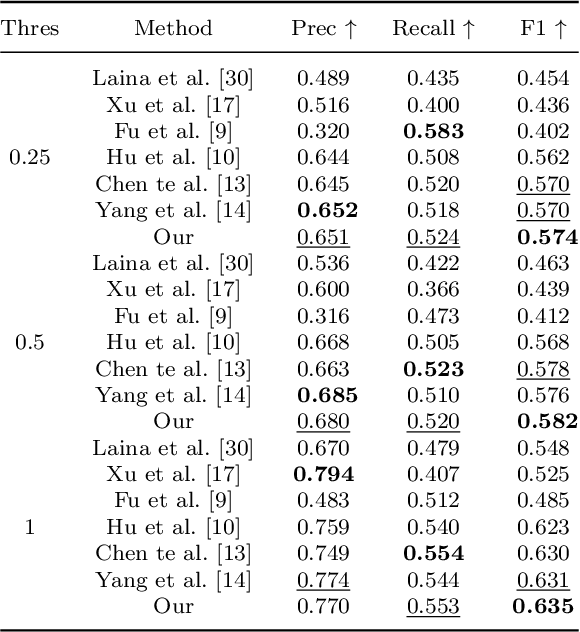
Monocular depth estimation is the base task in computer vision. It has a tremendous development in the decade with the development of deep learning. But the boundary blur of the depth map is still a serious problem. Research finds the boundary blur problem is mainly caused by two factors, first, the low-level features containing boundary and structure information may loss in deeper networks during the convolution process., second, the model ignores the errors introduced by the boundary area due to the few portions of the boundary in the whole areas during the backpropagation. In order to mitigate the boundary blur problem, we focus on the above two impact factors. Firstly, we design a scene understanding module to learn the global information with low- and high-level features, and then to transform the global information to different scales with our proposed scale transform module according to the different phases in the decoder. Secondly, we propose a boundary-aware depth loss function to pay attention to the effects of the boundary's depth value. The extensive experiments show that our method can predict the depth maps with clearer boundaries, and the performance of the depth accuracy base on NYU-depth v2 and SUN RGB-D is competitive.