 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Branch Subpixel-Guided Network for Hyperspectral Image Classification
Dec 05, 2024



Deep learning (DL) has been widely applied into hyperspectral image (HSI) classification owing to its promising feature learning and representation capabilities. However, limited by the spatial resolution of sensors, existing DL-based classification approaches mainly focus on pixel-level spectral and spatial information extraction through complex network architecture design, while ignoring the existence of mixed pixels in actual scenarios. To tackle this difficulty, we propose a novel dual-branch subpixel-guided network for HSI classification, called DSNet, which automatically integrates subpixel information and convolutional class features by introducing a deep autoencoder unmixing architecture to enhance classification performance. DSNet is capable of fully considering physically nonlinear properties within subpixels and adaptively generating diagnostic abundances in an unsupervised manner to achieve more reliable decision boundaries for class label distributions. The subpixel fusion module is designed to ensure high-quality information fusion across pixel and subpixel features, further promoting stable joint classification. Experimental results on three benchmark datasets demonstrate the effectiveness and superiority of DSNet compared with state-of-the-art DL-based HSI classification approaches. The codes will be available at https://github.com/hanzhu97702/DSNet, contributing to the remote sensing community.
Multisource Collaborative Domain Generalization for Cross-Scene Remote Sensing Image Classification
Dec 05, 2024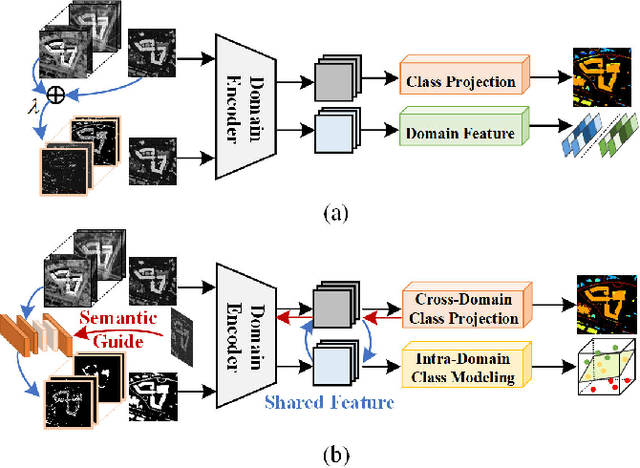

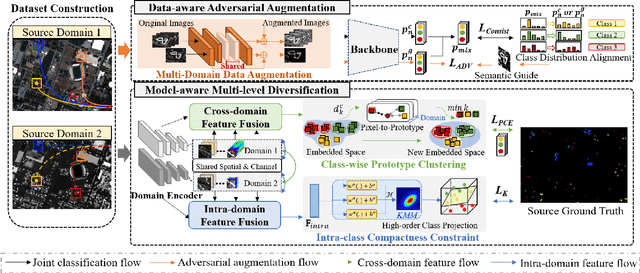
Cross-scene image classification aims to transfer prior knowledge of ground materials to annotate regions with different distributions and reduce hand-crafted cost in the field of remote sensing. However, existing approaches focus on single-source domain generalization to unseen target domains, and are easily confused by large real-world domain shifts due to the limited training information and insufficient diversity modeling capacity. To address this gap, we propose a novel multi-source collaborative domain generalization framework (MS-CDG) based on homogeneity and heterogeneity characteristics of multi-source remote sensing data, which considers data-aware adversarial augmentation and model-aware multi-level diversification simultaneously to enhance cross-scene generalization performance. The data-aware adversarial augmentation adopts an adversary neural network with semantic guide to generate MS samples by adaptively learning realistic channel and distribution changes across domains. In views of cross-domain and intra-domain modeling, the model-aware diversification transforms the shared spatial-channel features of MS data into the class-wise prototype and kernel mixture module, to address domain discrepancies and cluster different classes effectively. Finally, the joint classification of original and augmented MS samples is employed by introducing a distribution consistency alignment to increase model diversity and ensure better domain-invariant representation learning. Extensive experiments on three public MS remote sensing datasets demonstrate the superior performance of the proposed method when benchmarked with the state-of-the-art methods.
Hyperspectral Image Cross-Domain Object Detection Method based on Spectral-Spatial Feature Alignment
Nov 25, 2024
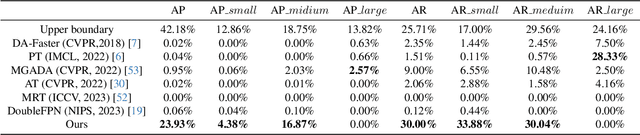

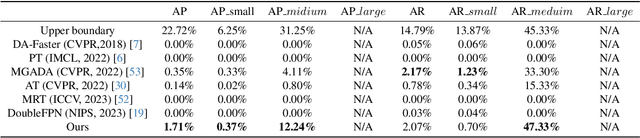
With consecutive bands in a wide range of wavelengths, hyperspectral images (HSI) have provided a unique tool for object detection task. However, existing HSI object detection methods have not been fully utilized in real applications, which is mainly resulted by the difference of spatial and spectral resolution between the unlabeled target domain and a labeled source domain, i.e. the domain shift of HSI. In this work, we aim to explore the unsupervised cross-domain object detection of HSI. Our key observation is that the local spatial-spectral characteristics remain invariant across different domains. For solving the problem of domain-shift, we propose a HSI cross-domain object detection method based on spectral-spatial feature alignment, which is the first attempt in the object detection community to the best of our knowledge. Firstly, we develop a spectral-spatial alignment module to extract domain-invariant local spatial-spectral features. Secondly, the spectral autocorrelation module has been designed to solve the domain shift in the spectral domain specifically, which can effectively align HSIs with different spectral resolutions. Besides, we have collected and annotated an HSI dataset for the cross-domain object detection. Our experimental results have proved the effectiveness of HSI cross-domain object detection, which has firstly demonstrated a significant and promising step towards HSI cross-domain object detection in the object detection community.
SpectralKAN: Kolmogorov-Arnold Network for Hyperspectral Images Change Detection
Jul 01, 2024



It has been verified that deep learning methods, including convolutional neural networks (CNNs), graph neural networks (GNNs), and transformers, can accurately extract features from hyperspectral images (HSIs). These algorithms perform exceptionally well on HSIs change detection (HSIs-CD). However, the downside of these impressive results is the enormous number of parameters, FLOPs, GPU memory, training and test times required. In this paper, we propose an spectral Kolmogorov-Arnold Network for HSIs-CD (SpectralKAN). SpectralKAN represent a multivariate continuous function with a composition of activation functions to extract HSIs feature and classification. These activation functions are b-spline functions with different parameters that can simulate various functions. In SpectralKAN, a KAN encoder is proposed to enhance computational efficiency for HSIs. And a spatial-spectral KAN encoder is introduced, where the spatial KAN encoder extracts spatial features and compresses the spatial dimensions from patch size to one. The spectral KAN encoder then extracts spectral features and classifies them into changed and unchanged categories. We use five HSIs-CD datasets to verify the effectiveness of SpectralKAN. Experimental verification has shown that SpectralKAN maintains high HSIs-CD accuracy while requiring fewer parameters, FLOPs, GPU memory, training and testing times, thereby increasing the efficiency of HSIs-CD. The code will be available at https://github.com/yanhengwang-heu/SpectralKAN.
Tensor Decompositions for Hyperspectral Data Processing in Remote Sensing: A Comprehensive Review
May 13, 2022



Owing to the rapid development of sensor technology, hyperspectral (HS) remote sensing (RS) imaging has provided a significant amount of spatial and spectral information for the observation and analysis of the Earth's surface at a distance of data acquisition devices, such as aircraft, spacecraft, and satellite. The recent advancement and even revolution of the HS RS technique offer opportunities to realize the full potential of various applications, while confronting new challenges for efficiently processing and analyzing the enormous HS acquisition data. Due to the maintenance of the 3-D HS inherent structure, tensor decomposition has aroused widespread concern and research in HS data processing tasks over the past decades. In this article, we aim at presenting a comprehensive overview of tensor decomposition, specifically contextualizing the five broad topics in HS data processing, and they are HS restoration, compressed sensing, anomaly detection, super-resolution, and spectral unmixing. For each topic, we elaborate on the remarkable achievements of tensor decomposition models for HS RS with a pivotal description of the existing methodologies and a representative exhibition on the experimental results. As a result, the remaining challenges of the follow-up research directions are outlined and discussed from the perspective of the real HS RS practices and tensor decomposition merged with advanced priors and even with deep neural networks. This article summarizes different tensor decomposition-based HS data processing methods and categorizes them into different classes from simple adoptions to complex combinations with other priors for the algorithm beginners. We also expect this survey can provide new investigations and development trends for the experienced researchers who understand tensor decomposition and HS RS to some extent.
Deep Learning in Multimodal Remote Sensing Data Fusion: A Comprehensive Review
May 03, 2022

With the extremely rapid advances in remote sensing (RS) technology, a great quantity of Earth observation (EO) data featuring considerable and complicated heterogeneity is readily available nowadays, which renders researchers an opportunity to tackle current geoscience applications in a fresh way. With the joint utilization of EO data, much research on multimodal RS data fusion has made tremendous progress in recent years, yet these developed traditional algorithms inevitably meet the performance bottleneck due to the lack of the ability to comprehensively analyse and interpret these strongly heterogeneous data. Hence, this non-negligible limitation further arouses an intense demand for an alternative tool with powerful processing competence. Deep learning (DL), as a cutting-edge technology, has witnessed remarkable breakthroughs in numerous computer vision tasks owing to its impressive ability in data representation and reconstruction. Naturally, it has been successfully applied to the field of multimodal RS data fusion, yielding great improvement compared with traditional methods. This survey aims to present a systematic overview in DL-based multimodal RS data fusion. More specifically, some essential knowledge about this topic is first given. Subsequently, a literature survey is conducted to analyse the trends of this field. Some prevalent sub-fields in the multimodal RS data fusion are then reviewed in terms of the to-be-fused data modalities, i.e., spatiospectral, spatiotemporal, light detection and ranging-optical, synthetic aperture radar-optical, and RS-Geospatial Big Data fusion. Furthermore, We collect and summarize some valuable resources for the sake of the development in multimodal RS data fusion. Finally, the remaining challenges and potential future directions are highlighted.
SpectralFormer: Rethinking Hyperspectral Image Classification with Transformers
Jul 07, 2021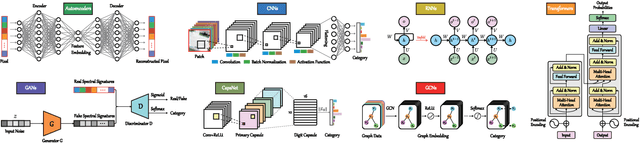

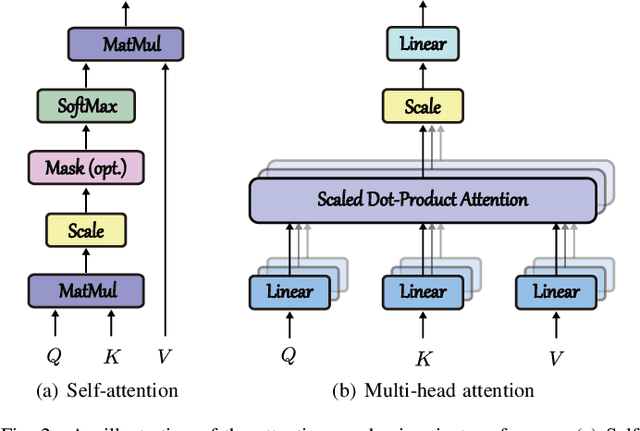
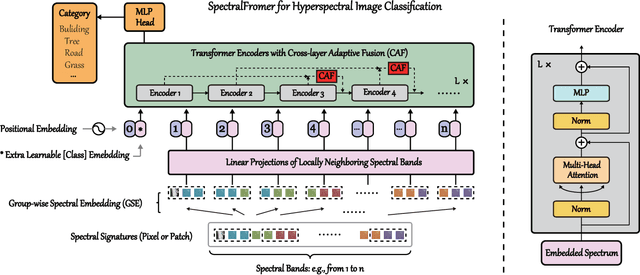
Hyperspectral (HS) images are characterized by approximately contiguous spectral information, enabling the fine identification of materials by capturing subtle spectral discrepancies. Owing to their excellent locally contextual modeling ability, convolutional neural networks (CNNs) have been proven to be a powerful feature extractor in HS image classification. However, CNNs fail to mine and represent the sequence attributes of spectral signatures well due to the limitations of their inherent network backbone. To solve this issue, we rethink HS image classification from a sequential perspective with transformers, and propose a novel backbone network called \ul{SpectralFormer}. Beyond band-wise representations in classic transformers, SpectralFormer is capable of learning spectrally local sequence information from neighboring bands of HS images, yielding group-wise spectral embeddings. More significantly, to reduce the possibility of losing valuable information in the layer-wise propagation process, we devise a cross-layer skip connection to convey memory-like components from shallow to deep layers by adaptively learning to fuse "soft" residuals across layers. It is worth noting that the proposed SpectralFormer is a highly flexible backbone network, which can be applicable to both pixel- and patch-wise inputs. We evaluate the classification performance of the proposed SpectralFormer on three HS datasets by conducting extensive experiments, showing the superiority over classic transformers and achieving a significant improvement in comparison with state-of-the-art backbone networks. The codes of this work will be available at \url{https://sites.google.com/view/danfeng-hong} for the sake of reproducibility.
Endmember-Guided Unmixing Network (EGU-Net): A General Deep Learning Framework for Self-Supervised Hyperspectral Unmixing
May 21, 2021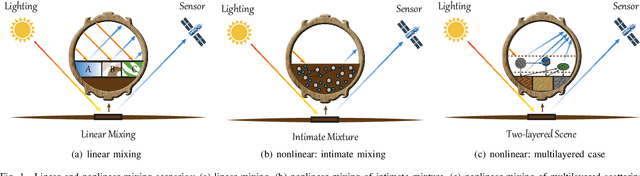
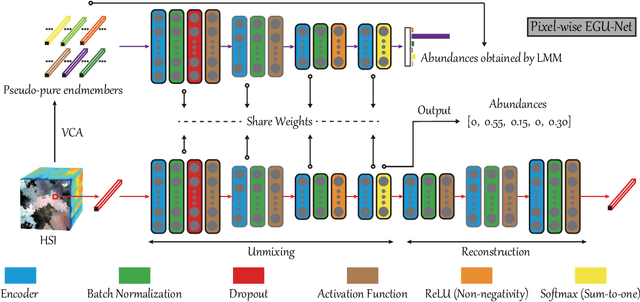
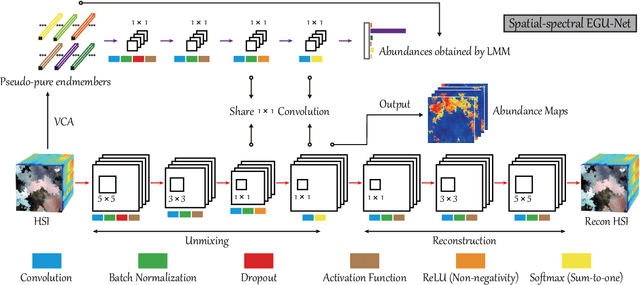

Over the past decades, enormous efforts have been made to improve the performance of linear or nonlinear mixing models for hyperspectral unmixing, yet their ability to simultaneously generalize various spectral variabilities and extract physically meaningful endmembers still remains limited due to the poor ability in data fitting and reconstruction and the sensitivity to various spectral variabilities. Inspired by the powerful learning ability of deep learning, we attempt to develop a general deep learning approach for hyperspectral unmixing, by fully considering the properties of endmembers extracted from the hyperspectral imagery, called endmember-guided unmixing network (EGU-Net). Beyond the alone autoencoder-like architecture, EGU-Net is a two-stream Siamese deep network, which learns an additional network from the pure or nearly-pure endmembers to correct the weights of another unmixing network by sharing network parameters and adding spectrally meaningful constraints (e.g., non-negativity and sum-to-one) towards a more accurate and interpretable unmixing solution. Furthermore, the resulting general framework is not only limited to pixel-wise spectral unmixing but also applicable to spatial information modeling with convolutional operators for spatial-spectral unmixing. Experimental results conducted on three different datasets with the ground-truth of abundance maps corresponding to each material demonstrate the effectiveness and superiority of the EGU-Net over state-of-the-art unmixing algorithms. The codes will be available from the website: https://github.com/danfenghong/IEEE_TNNLS_EGU-Net.
Using Low-rank Representation of Abundance Maps and Nonnegative Tensor Factorization for Hyperspectral Nonlinear Unmixing
Mar 30, 2021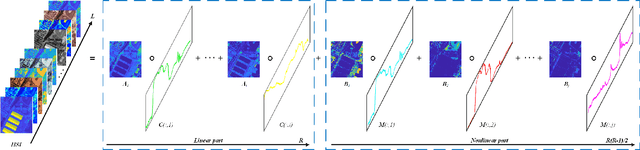

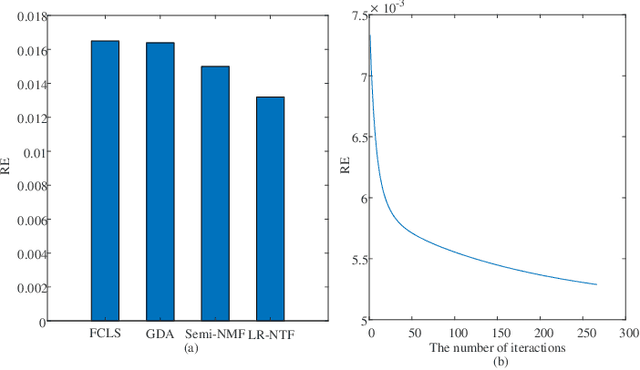
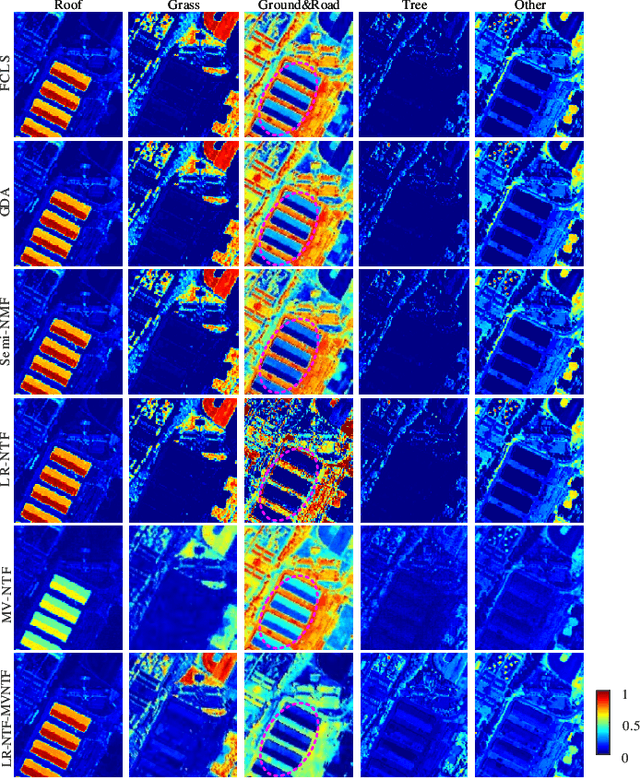
Tensor-based methods have been widely studied to attack inverse problems in hyperspectral imaging since a hyperspectral image (HSI) cube can be naturally represented as a third-order tensor, which can perfectly retain the spatial information in the image. In this article, we extend the linear tensor method to the nonlinear tensor method and propose a nonlinear low-rank tensor unmixing algorithm to solve the generalized bilinear model (GBM). Specifically, the linear and nonlinear parts of the GBM can both be expressed as tensors. Furthermore, the low-rank structures of abundance maps and nonlinear interaction abundance maps are exploited by minimizing their nuclear norm, thus taking full advantage of the high spatial correlation in HSIs. Synthetic and real-data experiments show that the low rank of abundance maps and nonlinear interaction abundance maps exploited in our method can improve the performance of the nonlinear unmixing. A MATLAB demo of this work will be available at https://github.com/LinaZhuang for the sake of reproducibility.
Hyperspectral Image Denoising and Anomaly Detection Based on Low-rank and Sparse Representations
Mar 12, 2021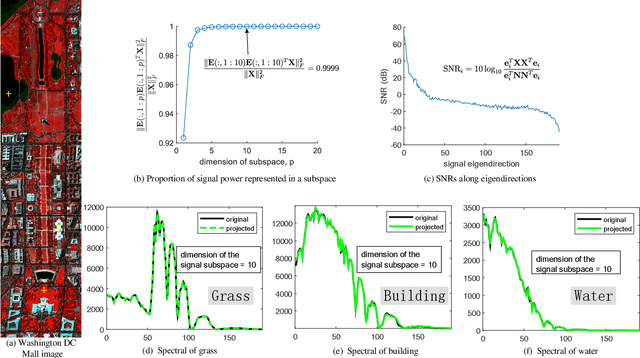
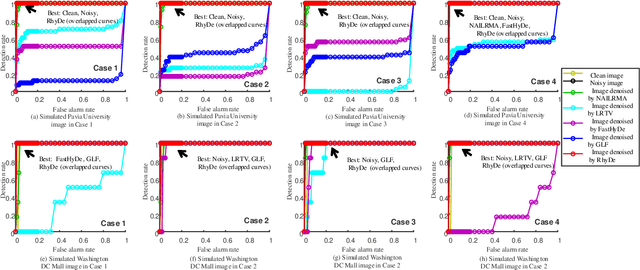
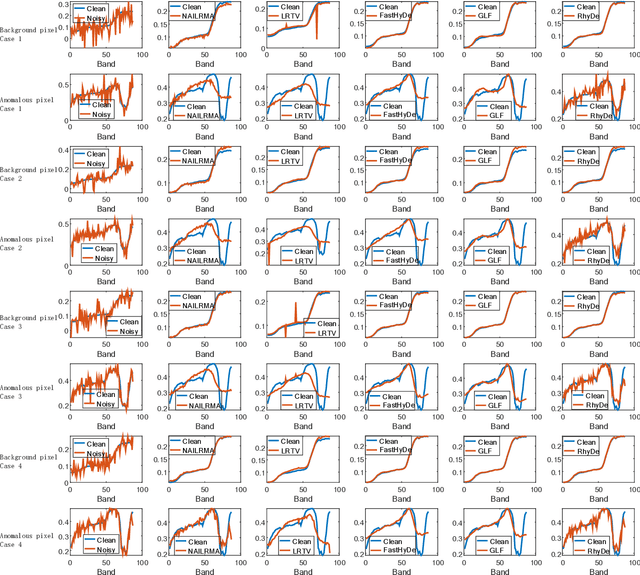
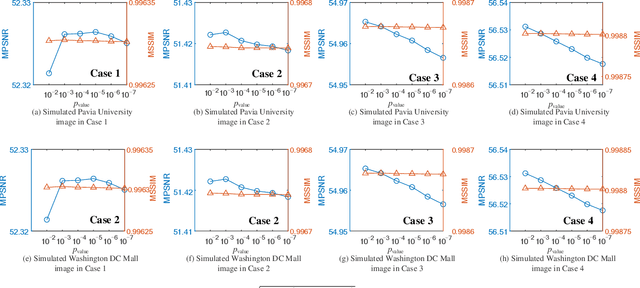
Hyperspectral imaging measures the amount of electromagnetic energy across the instantaneous field of view at a very high resolution in hundreds or thousands of spectral channels. This enables objects to be detected and the identification of materials that have subtle differences between them. However, the increase in spectral resolution often means that there is a decrease in the number of photons received in each channel, which means that the noise linked to the image formation process is greater. This degradation limits the quality of the extracted information and its potential applications. Thus, denoising is a fundamental problem in hyperspectral image (HSI) processing. As images of natural scenes with highly correlated spectral channels, HSIs are characterized by a high level of self-similarity and can be well approximated by low-rank representations. These characteristics underlie the state-of-the-art methods used in HSI denoising. However, where there are rarely occurring pixel types, the denoising performance of these methods is not optimal, and the subsequent detection of these pixels may be compromised. To address these hurdles, in this article, we introduce RhyDe (Robust hyperspectral Denoising), a powerful HSI denoiser, which implements explicit low-rank representation, promotes self-similarity, and, by using a form of collaborative sparsity, preserves rare pixels. The denoising and detection effectiveness of the proposed robust HSI denoiser is illustrated using semireal and real data.