 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Clinical-grade Universal Foundation Model for Intraoperative Pathology
Oct 06, 2025Intraoperative pathology is pivotal to precision surgery, yet its clinical impact is constrained by diagnostic complexity and the limited availability of high-quality frozen-section data. While computational pathology has made significant strides, the lack of large-scale, prospective validation has impeded its routine adoption in surgical workflows. Here, we introduce CRISP, a clinical-grade foundation model developed on over 100,000 frozen sections from eight medical centers, specifically designed to provide Clinical-grade Robust Intraoperative Support for Pathology (CRISP). CRISP was comprehensively evaluated on more than 15,000 intraoperative slides across nearly 100 retrospective diagnostic tasks, including benign-malignant discrimination, key intraoperative decision-making, and pan-cancer detection, etc. The model demonstrated robust generalization across diverse institutions, tumor types, and anatomical sites-including previously unseen sites and rare cancers. In a prospective cohort of over 2,000 patients, CRISP sustained high diagnostic accuracy under real-world conditions, directly informing surgical decisions in 92.6% of cases. Human-AI collaboration further reduced diagnostic workload by 35%, avoided 105 ancillary tests and enhanced detection of micrometastases with 87.5% accuracy. Together, these findings position CRISP as a clinical-grade paradigm for AI-driven intraoperative pathology, bridging computational advances with surgical precision and accelerating the translation of artificial intelligence into routine clinical practice.
Deep Learning in Multimodal Remote Sensing Data Fusion: A Comprehensive Review
May 03, 2022

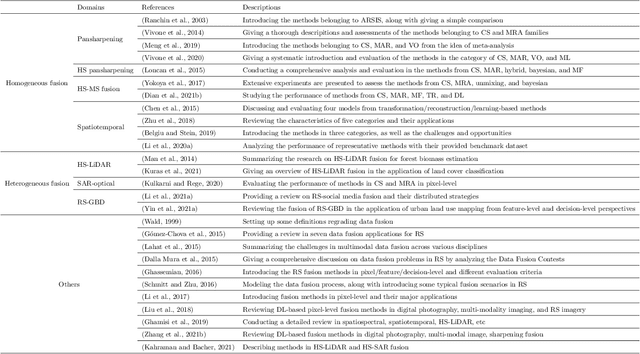
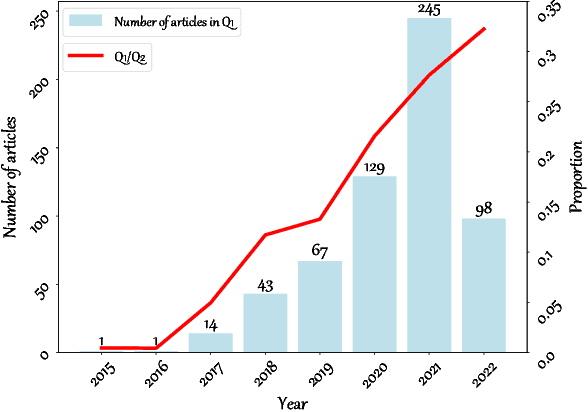
With the extremely rapid advances in remote sensing (RS) technology, a great quantity of Earth observation (EO) data featuring considerable and complicated heterogeneity is readily available nowadays, which renders researchers an opportunity to tackle current geoscience applications in a fresh way. With the joint utilization of EO data, much research on multimodal RS data fusion has made tremendous progress in recent years, yet these developed traditional algorithms inevitably meet the performance bottleneck due to the lack of the ability to comprehensively analyse and interpret these strongly heterogeneous data. Hence, this non-negligible limitation further arouses an intense demand for an alternative tool with powerful processing competence. Deep learning (DL), as a cutting-edge technology, has witnessed remarkable breakthroughs in numerous computer vision tasks owing to its impressive ability in data representation and reconstruction. Naturally, it has been successfully applied to the field of multimodal RS data fusion, yielding great improvement compared with traditional methods. This survey aims to present a systematic overview in DL-based multimodal RS data fusion. More specifically, some essential knowledge about this topic is first given. Subsequently, a literature survey is conducted to analyse the trends of this field. Some prevalent sub-fields in the multimodal RS data fusion are then reviewed in terms of the to-be-fused data modalities, i.e., spatiospectral, spatiotemporal, light detection and ranging-optical, synthetic aperture radar-optical, and RS-Geospatial Big Data fusion. Furthermore, We collect and summarize some valuable resources for the sake of the development in multimodal RS data fusion. Finally, the remaining challenges and potential future directions are highlighted.
Coupled Convolutional Neural Network with Adaptive Response Function Learning for Unsupervised Hyperspectral Super-Resolution
Jul 28, 2020



Due to the limitations of hyperspectral imaging systems, hyperspectral imagery (HSI) often suffers from poor spatial resolution, thus hampering many applications of the imagery. Hyperspectral super-resolution refers to fusing HSI and MSI to generate an image with both high spatial and high spectral resolutions. Recently, several new methods have been proposed to solve this fusion problem, and most of these methods assume that the prior information of the Point Spread Function (PSF) and Spectral Response Function (SRF) are known. However, in practice, this information is often limited or unavailable. In this work, an unsupervised deep learning-based fusion method - HyCoNet - that can solve the problems in HSI-MSI fusion without the prior PSF and SRF information is proposed. HyCoNet consists of three coupled autoencoder nets in which the HSI and MSI are unmixed into endmembers and abundances based on the linear unmixing model. Two special convolutional layers are designed to act as a bridge that coordinates with the three autoencoder nets, and the PSF and SRF parameters are learned adaptively in the two convolution layers during the training process. Furthermore, driven by the joint loss function, the proposed method is straightforward and easily implemented in an end-to-end training manner. The experiments performed in the study demonstrate that the proposed method performs well and produces robust results for different datasets and arbitrary PSFs and SRFs.