 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Sentence, One Drama: Personalized Short-Form Drama Generation via Multi-Agent Systems
May 21, 2026Existing approaches for digital short-drama production typically rely on one-shot LLM generated scripts and loosely coupled pipelines, which fail to satisfy three key requirements of short-drama generation: (1) narrative pacing, resulting in weak hooks, insufficient escalation, and unattractive endings; (2) spatial consistency, leading to drifting scene layouts and inconsistent character positions across clips; and (3) production-level quality control, requiring extensive manual review and correction across script and visual stages. We present One Sentence, One Drama, a hierarchical multi-agent framework that transforms a user's single-sentence idea into a fully produced short drama through structured intermediate modules and iterative refinement. Our approach is built upon three key components: (1) a multi-agent debate-based story generation module that enforces short-drama pacing and narrative coherence; (2) a 3D-grounded first-frame generation mechanism that establishes a shared spatial reference for consistent character positioning and scene layout across clips; and (3) multi-stage reviewer loops that perform comprehensive error detection and targeted revision across script, visual, and video generation stages. We also introduce scene-level BGM matching and scene transition planning to improve the audience's immersive experience. To systematically evaluate this task, we introduce Short-Drama-Bench, a benchmark that extends standard video quality metrics with short-drama-specific criteria. Experimental results demonstrate that our method significantly outperforms existing pipelines in narrative quality, cross-clip consistency, and overall viewing experience.
Beyond Local vs. External: A Game-Theoretic Framework for Trustworthy Knowledge Acquisition
Apr 25, 2026Cloud-hosted Large Language Models (LLMs) offer unmatched reasoning capabilities and dynamic knowledge, yet submitting raw queries to these external services risks exposing sensitive user intent. Conversely, relying exclusively on trusted local models preserves privacy but often compromises answer quality due to limited parameter scale and knowledge. To resolve this dilemma, we propose Game-theoretic Trustworthy Knowledge Acquisition (GTKA), a framework that formulates the trade-off between knowledge utility and privacy as a strategic game. GTKA consists of three components: (i) a privacy-aware sub-query generator that decomposes sensitive intent into generalized, low-risk fragments; (ii) an adversarial reconstruction attacker that attempts to infer the original query from these fragments, providing adaptive leakage signals; and (iii) a trusted local integrator that synthesizes external responses within a secure boundary. By training the generator and attacker in an alternating adversarial manner, GTKA optimizes the sub-query generation policy to maximize knowledge acquisition accuracy while minimizing the reconstructability of the original sensitive intent. To validate our approach, we construct two sensitive-domain benchmarks in the biomedical and legal fields. Extensive experiments demonstrate that GTKA significantly reduces intent leakage compared to state-of-the-art baselines while maintaining high-fidelity answer quality.
4DPC$^2$hat: Towards Dynamic Point Cloud Understanding with Failure-Aware Bootstrapping
Feb 03, 2026Point clouds provide a compact and expressive representation of 3D objects, and have recently been integrated into multimodal large language models (MLLMs). However, existing methods primarily focus on static objects, while understanding dynamic point cloud sequences remains largely unexplored. This limitation is mainly caused by the lack of large-scale cross-modal datasets and the difficulty of modeling motions in spatio-temporal contexts. To bridge this gap, we present 4DPC$^2$hat, the first MLLM tailored for dynamic point cloud understanding. To this end, we construct a large-scale cross-modal dataset 4DPC$^2$hat-200K via a meticulous two-stage pipeline consisting of topology-consistent 4D point construction and two-level captioning. The dataset contains over 44K dynamic object sequences, 700K point cloud frames, and 200K curated question-answer (QA) pairs, supporting inquiries about counting, temporal relationship, action, spatial relationship, and appearance. At the core of the framework, we introduce a Mamba-enhanced temporal reasoning MLLM to capture long-range dependencies and dynamic patterns among a point cloud sequence. Furthermore, we propose a failure-aware bootstrapping learning strategy that iteratively identifies model deficiencies and generates targeted QA supervision to continuously strengthen corresponding reasoning capabilities. Extensive experiments demonstrate that our 4DPC$^2$hat significantly improves action understanding and temporal reasoning compared with existing models, establishing a strong foundation for 4D dynamic point cloud understanding.
Teaching According to Students' Aptitude: Personalized Mathematics Tutoring via Persona-, Memory-, and Forgetting-Aware LLMs
Nov 19, 2025Large Language Models (LLMs) are increasingly integrated into intelligent tutoring systems to provide human-like and adaptive instruction. However, most existing approaches fail to capture how students' knowledge evolves dynamically across their proficiencies, conceptual gaps, and forgetting patterns. This challenge is particularly acute in mathematics tutoring, where effective instruction requires fine-grained scaffolding precisely calibrated to each student's mastery level and cognitive retention. To address this issue, we propose TASA (Teaching According to Students' Aptitude), a student-aware tutoring framework that integrates persona, memory, and forgetting dynamics for personalized mathematics learning. Specifically, TASA maintains a structured student persona capturing proficiency profiles and an event memory recording prior learning interactions. By incorporating a continuous forgetting curve with knowledge tracing, TASA dynamically updates each student's mastery state and generates contextually appropriate, difficulty-calibrated questions and explanations. Empirical results demonstrate that TASA achieves superior learning outcomes and more adaptive tutoring behavior compared to representative baselines, underscoring the importance of modeling temporal forgetting and learner profiles in LLM-based tutoring systems.
ETSCL: An Evidence Theory-Based Supervised Contrastive Learning Framework for Multi-modal Glaucoma Grading
Jul 19, 2024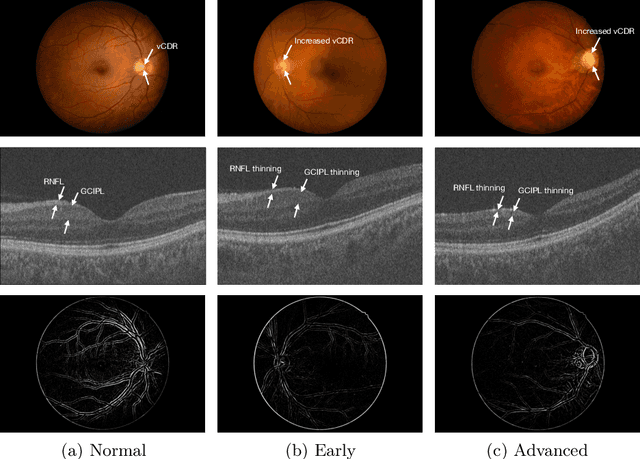

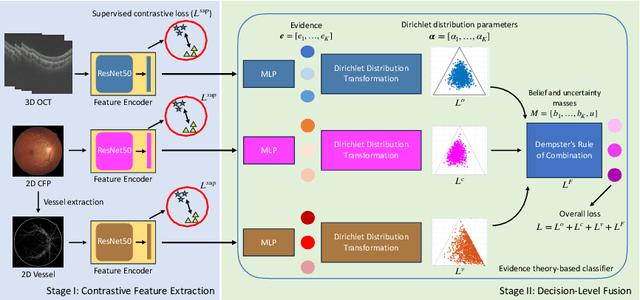
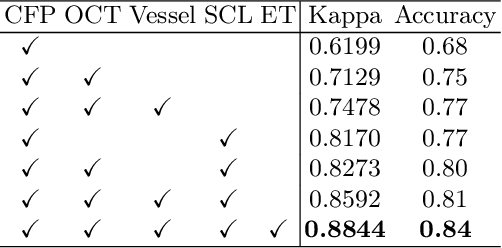
Glaucoma is one of the leading causes of vision impairment. Digital imaging techniques, such as color fundus photography (CFP) and optical coherence tomography (OCT), provide quantitative and noninvasive methods for glaucoma diagnosis. Recently, in the field of computer-aided glaucoma diagnosis, multi-modality methods that integrate the CFP and OCT modalities have achieved greater diagnostic accuracy compared to single-modality methods. However, it remains challenging to extract reliable features due to the high similarity of medical images and the unbalanced multi-modal data distribution. Moreover, existing methods overlook the uncertainty estimation of different modalities, leading to unreliable predictions. To address these challenges, we propose a novel framework, namely ETSCL, which consists of a contrastive feature extraction stage and a decision-level fusion stage. Specifically, the supervised contrastive loss is employed to enhance the discriminative power in the feature extraction process, resulting in more effective features. In addition, we utilize the Frangi vesselness algorithm as a preprocessing step to incorporate vessel information to assist in the prediction. In the decision-level fusion stage, an evidence theory-based multi-modality classifier is employed to combine multi-source information with uncertainty estimation. Extensive experiments demonstrate that our method achieves state-of-the-art performance. The code is available at \url{https://github.com/master-Shix/ETSCL}.
ColonNeRF: Neural Radiance Fields for High-Fidelity Long-Sequence Colonoscopy Reconstruction
Dec 04, 2023Colonoscopy reconstruction is pivotal for diagnosing colorectal cancer. However, accurate long-sequence colonoscopy reconstruction faces three major challenges: (1) dissimilarity among segments of the colon due to its meandering and convoluted shape; (2) co-existence of simple and intricately folded geometry structures; (3) sparse viewpoints due to constrained camera trajectories. To tackle these challenges, we introduce a new reconstruction framework based on neural radiance field (NeRF), named ColonNeRF, which leverages neural rendering for novel view synthesis of long-sequence colonoscopy. Specifically, to reconstruct the entire colon in a piecewise manner, our ColonNeRF introduces a region division and integration module, effectively reducing shape dissimilarity and ensuring geometric consistency in each segment. To learn both the simple and complex geometry in a unified framework, our ColonNeRF incorporates a multi-level fusion module that progressively models the colon regions from easy to hard. Additionally, to overcome the challenges from sparse views, we devise a DensiNet module for densifying camera poses under the guidance of semantic consistency. We conduct extensive experiments on both synthetic and real-world datasets to evaluate our ColonNeRF. Quantitatively, our ColonNeRF outperforms existing methods on two benchmarks over four evaluation metrics. Notably, our LPIPS-ALEX scores exhibit a substantial increase of about 67%-85% on the SimCol-to-3D dataset. Qualitatively, our reconstruction visualizations show much clearer textures and more accurate geometric details. These sufficiently demonstrate our superior performance over the state-of-the-art methods.
Continual Learning via Manifold Expansion Replay
Oct 12, 2023


In continual learning, the learner learns multiple tasks in sequence, with data being acquired only once for each task. Catastrophic forgetting is a major challenge to continual learning. To reduce forgetting, some existing rehearsal-based methods use episodic memory to replay samples of previous tasks. However, in the process of knowledge integration when learning a new task, this strategy also suffers from catastrophic forgetting due to an imbalance between old and new knowledge. To address this problem, we propose a novel replay strategy called Manifold Expansion Replay (MaER). We argue that expanding the implicit manifold of the knowledge representation in the episodic memory helps to improve the robustness and expressiveness of the model. To this end, we propose a greedy strategy to keep increasing the diameter of the implicit manifold represented by the knowledge in the buffer during memory management. In addition, we introduce Wasserstein distance instead of cross entropy as distillation loss to preserve previous knowledge. With extensive experimental validation on MNIST, CIFAR10, CIFAR100, and TinyImageNet, we show that the proposed method significantly improves the accuracy in continual learning setup, outperforming the state of the arts.