 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHolo360D: A Large-Scale Real-World Dataset with Continuous Trajectories for Advancing Panoramic 3D Reconstruction and Beyond
Apr 24, 2026While feed-forward 3D reconstruction models have advanced rapidly, they still exhibit degraded performance on panoramas due to spherical distortions. Moreover, existing panoramic 3D datasets are predominantly collected with 360 cameras fixed at discrete locations, resulting in discontinuous trajectories. These limitations critically hinder the development of panoramic feed-forward 3D reconstruction, especially for the multi-view setting. In this paper, we present Holo360D, a comprehensive dataset containing 109,495 panoramas paired with registered point clouds, meshes, and aligned camera poses. To our knowledge, Holo360D is the first large-scale dataset that provides continuous panoramic sequences with accurately aligned high-completeness depth maps. The raw data are initially collected using a 3D laser scanner coupled with a 360 camera. Subsequently, the raw data are processed with both online and offline SLAM systems. Furthermore, to enhance the 3D data quality, a post-processing pipeline tailored for the 360 dataset is proposed, including geometry denoising, mesh hole filling, and region-specific remeshing. Finally, we establish a new benchmark by fine-tuning 3D reconstruction models on Holo360D, providing key insights into effective fine-tuning strategies. Our results demonstrate that Holo360D delivers superior training signals and provides a comprehensive benchmark for advancing panoramic 3D reconstruction models. Datasets and Code will be made publicly available.
EventVGGT: Exploring Cross-Modal Distillation for Consistent Event-based Depth Estimation
Mar 10, 2026Event cameras offer superior sensitivity to high-speed motion and extreme lighting, making event-based monocular depth estimation a promising approach for robust 3D perception in challenging conditions. However, progress is severely hindered by the scarcity of dense depth annotations. While recent annotation-free approaches mitigate this by distilling knowledge from Vision Foundation Models (VFMs), a critical limitation persists: they process event streams as independent frames. By neglecting the inherent temporal continuity of event data, these methods fail to leverage the rich temporal priors encoded in VFMs, ultimately yielding temporally inconsistent and less accurate depth predictions. To address this, we introduce EventVGGT, a novel framework that explicitly models the event stream as a coherent video sequence. To the best of our knowledge, we are the first to distill spatio-temporal and multi-view geometric priors from the Visual Geometry Grounded Transformer (VGGT) into the event domain. We achieve this via a comprehensive tri-level distillation strategy: (i) Cross-Modal Feature Mixture (CMFM) bridges the modality gap at the output level by fusing RGB and event features to generate auxiliary depth predictions; (ii) Spatio-Temporal Feature Distillation (STFD) distills VGGT's powerful spatio-temporal representations at the feature level; and (iii) Temporal Consistency Distillation (TCD) enforces cross-frame coherence at the temporal level by aligning inter-frame depth changes. Extensive experiments demonstrate that EventVGGT consistently outperforms existing methods -- reducing the absolute mean depth error at 30m by over 53\% on EventScape (from 2.30 to 1.06) -- while exhibiting robust zero-shot generalization on the unseen DENSE and MVSEC datasets.
Beyond a Single Light: A Large-Scale Aerial Dataset for Urban Scene Reconstruction Under Varying Illumination
Dec 16, 2025Recent advances in Neural Radiance Fields and 3D Gaussian Splatting have demonstrated strong potential for large-scale UAV-based 3D reconstruction tasks by fitting the appearance of images. However, real-world large-scale captures are often based on multi-temporal data capture, where illumination inconsistencies across different times of day can significantly lead to color artifacts, geometric inaccuracies, and inconsistent appearance. Due to the lack of UAV datasets that systematically capture the same areas under varying illumination conditions, this challenge remains largely underexplored. To fill this gap, we introduceSkyLume, a large-scale, real-world UAV dataset specifically designed for studying illumination robust 3D reconstruction in urban scene modeling: (1) We collect data from 10 urban regions data comprising more than 100k high resolution UAV images (four oblique views and nadir), where each region is captured at three periods of the day to systematically isolate illumination changes. (2) To support precise evaluation of geometry and appearance, we provide per-scene LiDAR scans and accurate 3D ground-truth for assessing depth, surface normals, and reconstruction quality under varying illumination. (3) For the inverse rendering task, we introduce the Temporal Consistency Coefficient (TCC), a metric that measuress cross-time albedo stability and directly evaluates the robustness of the disentanglement of light and material. We aim for this resource to serve as a foundation that advances research and real-world evaluation in large-scale inverse rendering, geometry reconstruction, and novel view synthesis.
Exploring the Vulnerabilities of Federated Learning: A Deep Dive into Gradient Inversion Attacks
Mar 13, 2025
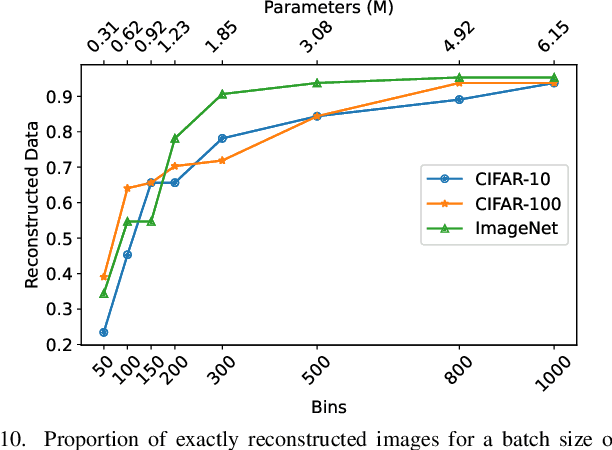
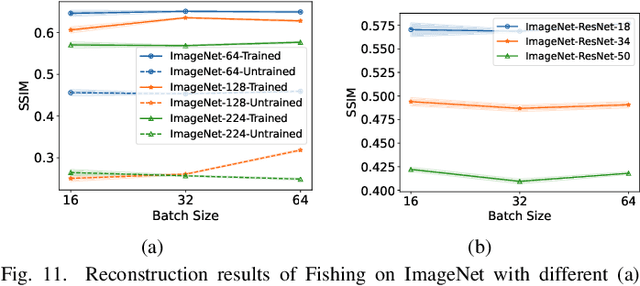
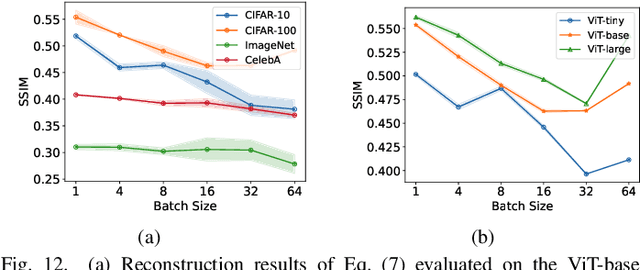
Federated Learning (FL) has emerged as a promising privacy-preserving collaborative model training paradigm without sharing raw data. However, recent studies have revealed that private information can still be leaked through shared gradient information and attacked by Gradient Inversion Attacks (GIA). While many GIA methods have been proposed, a detailed analysis, evaluation, and summary of these methods are still lacking. Although various survey papers summarize existing privacy attacks in FL, few studies have conducted extensive experiments to unveil the effectiveness of GIA and their associated limiting factors in this context. To fill this gap, we first undertake a systematic review of GIA and categorize existing methods into three types, i.e., \textit{optimization-based} GIA (OP-GIA), \textit{generation-based} GIA (GEN-GIA), and \textit{analytics-based} GIA (ANA-GIA). Then, we comprehensively analyze and evaluate the three types of GIA in FL, providing insights into the factors that influence their performance, practicality, and potential threats. Our findings indicate that OP-GIA is the most practical attack setting despite its unsatisfactory performance, while GEN-GIA has many dependencies and ANA-GIA is easily detectable, making them both impractical. Finally, we offer a three-stage defense pipeline to users when designing FL frameworks and protocols for better privacy protection and share some future research directions from the perspectives of attackers and defenders that we believe should be pursued. We hope that our study can help researchers design more robust FL frameworks to defend against these attacks.
Rethinking Knowledge in Distillation: An In-context Sample Retrieval Perspective
Jan 13, 2025



Conventional knowledge distillation (KD) approaches are designed for the student model to predict similar output as the teacher model for each sample. Unfortunately, the relationship across samples with same class is often neglected. In this paper, we explore to redefine the knowledge in distillation, capturing the relationship between each sample and its corresponding in-context samples (a group of similar samples with the same or different classes), and perform KD from an in-context sample retrieval perspective. As KD is a type of learned label smoothing regularization (LSR), we first conduct a theoretical analysis showing that the teacher's knowledge from the in-context samples is a crucial contributor to regularize the student training with the corresponding samples. Buttressed by the analysis, we propose a novel in-context knowledge distillation (IC-KD) framework that shows its superiority across diverse KD paradigms (offline, online, and teacher-free KD). Firstly, we construct a feature memory bank from the teacher model and retrieve in-context samples for each corresponding sample through retrieval-based learning. We then introduce Positive In-Context Distillation (PICD) to reduce the discrepancy between a sample from the student and the aggregated in-context samples with the same class from the teacher in the logit space. Moreover, Negative In-Context Distillation (NICD) is introduced to separate a sample from the student and the in-context samples with different classes from the teacher in the logit space. Extensive experiments demonstrate that IC-KD is effective across various types of KD, and consistently achieves state-of-the-art performance on CIFAR-100 and ImageNet datasets.
CLIP the Divergence: Language-guided Unsupervised Domain Adaptation
Jul 01, 2024Unsupervised domain adaption (UDA) has emerged as a popular solution to tackle the divergence between the labeled source and unlabeled target domains. Recently, some research efforts have been made to leverage large vision-language models, such as CLIP, and then fine-tune or learn prompts from them for addressing the challenging UDA task. In this work, we shift the gear to a new direction by directly leveraging CLIP to measure the domain divergence and propose a novel language-guided approach for UDA, dubbed as CLIP-Div. Our key idea is to harness CLIP to 1) measure the domain divergence via the acquired domain-agnostic distribution and 2) calibrate the target pseudo labels with language guidance, to effectively reduce the domain gap and improve the UDA model's generalization capability. Specifically, our major technical contribution lies in the proposed two novel language-guided domain divergence measurement losses: absolute divergence and relative divergence. These loss terms furnish precise guidelines for aligning the distributions of the source and target domains with the domain-agnostic distribution derived from CLIP. Additionally, we propose a language-guided pseudo-labeling strategy for calibrating the target pseudo labels. Buttressed by it, we show that a further implementation for self-training can enhance the UDA model's generalization capability on the target domain. CLIP-Div surpasses state-of-the-art CNN-based methods by a substantial margin, achieving a performance boost of +10.3% on Office-Home, +1.5% on Office-31, +0.2% on VisDA-2017, and +24.3% on DomainNet, respectively.
Any360D: Towards 360 Depth Anything with Unlabeled 360 Data and Möbius Spatial Augmentation
Jun 19, 2024



Recently, Depth Anything Model (DAM) - a type of depth foundation model - reveals impressive zero-shot capacity for diverse perspective images. Despite its success, it remains an open question regarding DAM's performance on 360 images that enjoy a large field-of-view (180x360) but suffer from spherical distortions. To this end, we establish, to our knowledge, the first benchmark that aims to 1) evaluate the performance of DAM on 360 images and 2) develop a powerful 360 DAM for the benefit of the community. For this, we conduct a large suite of experiments that consider the key properties of 360 images, e.g., different 360 representations, various spatial transformations, and diverse indoor and outdoor scenes. This way, our benchmark unveils some key findings, e.g., DAM is less effective for diverse 360 scenes and sensitive to spatial transformations. To address these challenges, we first collect a large-scale unlabeled dataset including diverse indoor and outdoor scenes. We then propose a semi-supervised learning (SSL) framework to learn a 360 DAM, dubbed Any360D. Under the umbrella of SSL, Any360D first learns a teacher model by fine-tuning DAM via metric depth supervision. Then, we train the student model by uncovering the potential of large-scale unlabeled data with pseudo labels from the teacher model. M\"obius transformation-based spatial augmentation (MTSA) is proposed to impose consistency regularization between the unlabeled data and spatially transformed ones. This subtly improves the student model's robustness to various spatial transformations even under severe distortions. Extensive experiments demonstrate that Any360D outperforms DAM and many prior data-specific models, e.g., PanoFormer, across diverse scenes, showing impressive zero-shot capacity for being a 360 depth foundation model.
Energy-based Domain-Adaptive Segmentation with Depth Guidance
Feb 06, 2024Recent endeavors have been made to leverage self-supervised depth estimation as guidance in unsupervised domain adaptation (UDA) for semantic segmentation. Prior arts, however, overlook the discrepancy between semantic and depth features, as well as the reliability of feature fusion, thus leading to suboptimal segmentation performance. To address this issue, we propose a novel UDA framework called SMART (croSs doMain semAntic segmentation based on eneRgy esTimation) that utilizes Energy-Based Models (EBMs) to obtain task-adaptive features and achieve reliable feature fusion for semantic segmentation with self-supervised depth estimates. Our framework incorporates two novel components: energy-based feature fusion (EB2F) and energy-based reliable fusion Assessment (RFA) modules. The EB2F module produces task-adaptive semantic and depth features by explicitly measuring and reducing their discrepancy using Hopfield energy for better feature fusion. The RFA module evaluates the reliability of the feature fusion using an energy score to improve the effectiveness of depth guidance. Extensive experiments on two datasets demonstrate that our method achieves significant performance gains over prior works, validating the effectiveness of our energy-based learning approach.
Source-Free Cross-Modal Knowledge Transfer by Unleashing the Potential of Task-Irrelevant Data
Jan 10, 2024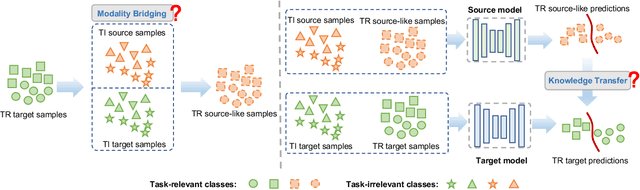
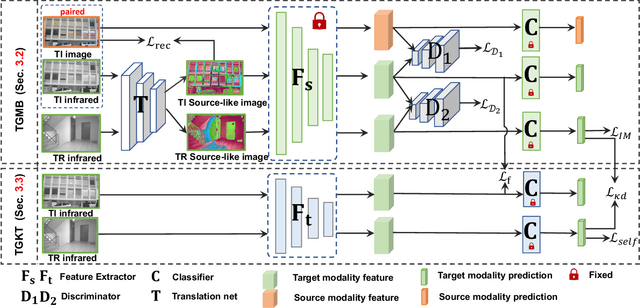

Source-free cross-modal knowledge transfer is a crucial yet challenging task, which aims to transfer knowledge from one source modality (e.g., RGB) to the target modality (e.g., depth or infrared) with no access to the task-relevant (TR) source data due to memory and privacy concerns. A recent attempt leverages the paired task-irrelevant (TI) data and directly matches the features from them to eliminate the modality gap. However, it ignores a pivotal clue that the paired TI data could be utilized to effectively estimate the source data distribution and better facilitate knowledge transfer to the target modality. To this end, we propose a novel yet concise framework to unlock the potential of paired TI data for enhancing source-free cross-modal knowledge transfer. Our work is buttressed by two key technical components. Firstly, to better estimate the source data distribution, we introduce a Task-irrelevant data-Guided Modality Bridging (TGMB) module. It translates the target modality data (e.g., infrared) into the source-like RGB images based on paired TI data and the guidance of the available source model to alleviate two key gaps: 1) inter-modality gap between the paired TI data; 2) intra-modality gap between TI and TR target data. We then propose a Task-irrelevant data-Guided Knowledge Transfer (TGKT) module that transfers knowledge from the source model to the target model by leveraging the paired TI data. Notably, due to the unavailability of labels for the TR target data and its less reliable prediction from the source model, our TGKT model incorporates a self-supervised pseudo-labeling approach to enable the target model to learn from its predictions. Extensive experiments show that our method achieves state-of-the-art performance on three datasets (RGB-to-depth and RGB-to-infrared).
A Unified Framework for Unsupervised Domain Adaptation based on Instance Weighting
Dec 08, 2023
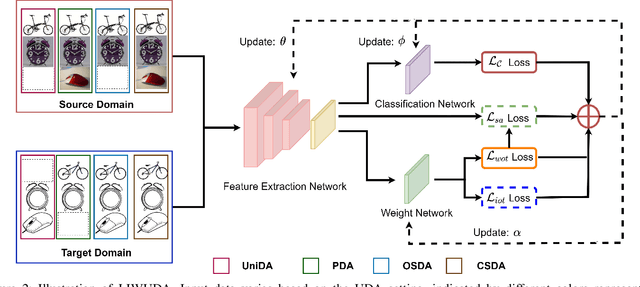
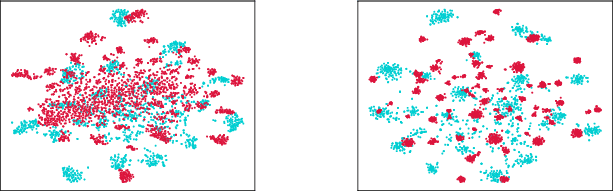
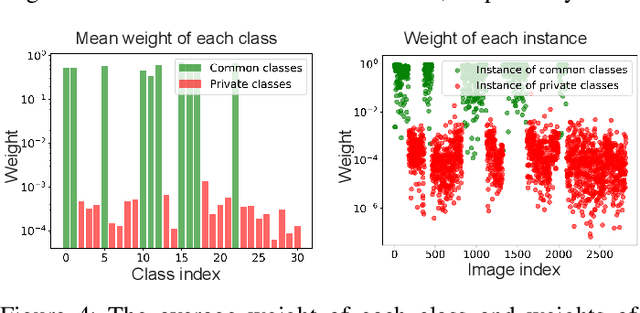
Despite the progress made in domain adaptation, solving Unsupervised Domain Adaptation (UDA) problems with a general method under complex conditions caused by label shifts between domains remains a formidable task. In this work, we comprehensively investigate four distinct UDA settings including closed set domain adaptation, partial domain adaptation, open set domain adaptation, and universal domain adaptation, where shared common classes between source and target domains coexist alongside domain-specific private classes. The prominent challenges inherent in diverse UDA settings center around the discrimination of common/private classes and the precise measurement of domain discrepancy. To surmount these challenges effectively, we propose a novel yet effective method called Learning Instance Weighting for Unsupervised Domain Adaptation (LIWUDA), which caters to various UDA settings. Specifically, the proposed LIWUDA method constructs a weight network to assign weights to each instance based on its probability of belonging to common classes, and designs Weighted Optimal Transport (WOT) for domain alignment by leveraging instance weights. Additionally, the proposed LIWUDA method devises a Separate and Align (SA) loss to separate instances with low similarities and align instances with high similarities. To guide the learning of the weight network, Intra-domain Optimal Transport (IOT) is proposed to enforce the weights of instances in common classes to follow a uniform distribution. Through the integration of those three components, the proposed LIWUDA method demonstrates its capability to address all four UDA settings in a unified manner. Experimental evaluations conducted on three benchmark datasets substantiate the effectiveness of the proposed LIWUDA method.