 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackward Imitation and Forward Reinforcement Learning via Bi-directional Model Rollouts
Paper and Code
Aug 04, 2022
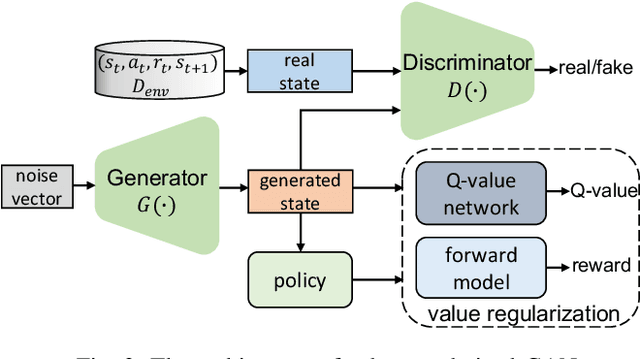

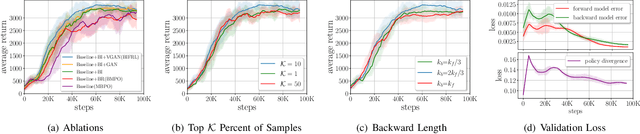
Traditional model-based reinforcement learning (RL) methods generate forward rollout traces using the learnt dynamics model to reduce interactions with the real environment. The recent model-based RL method considers the way to learn a backward model that specifies the conditional probability of the previous state given the previous action and the current state to additionally generate backward rollout trajectories. However, in this type of model-based method, the samples derived from backward rollouts and those from forward rollouts are simply aggregated together to optimize the policy via the model-free RL algorithm, which may decrease both the sample efficiency and the convergence rate. This is because such an approach ignores the fact that backward rollout traces are often generated starting from some high-value states and are certainly more instructive for the agent to improve the behavior. In this paper, we propose the backward imitation and forward reinforcement learning (BIFRL) framework where the agent treats backward rollout traces as expert demonstrations for the imitation of excellent behaviors, and then collects forward rollout transitions for policy reinforcement. Consequently, BIFRL empowers the agent to both reach to and explore from high-value states in a more efficient manner, and further reduces the real interactions, making it potentially more suitable for real-robot learning. Moreover, a value-regularized generative adversarial network is introduced to augment the valuable states which are infrequently received by the agent. Theoretically, we provide the condition where BIFRL is superior to the baseline methods. Experimentally, we demonstrate that BIFRL acquires the better sample efficiency and produces the competitive asymptotic performance on various MuJoCo locomotion tasks compared against state-of-the-art model-based methods.