 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhonetic Posteriorgrams based Many-to-Many Singing Voice Conversion via Adversarial Training
Paper and Code
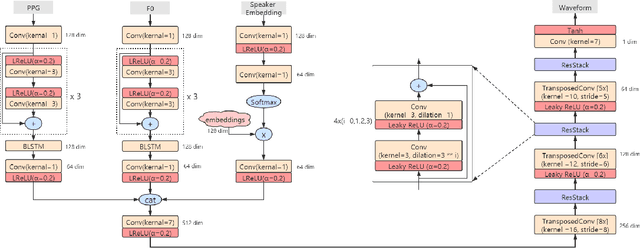

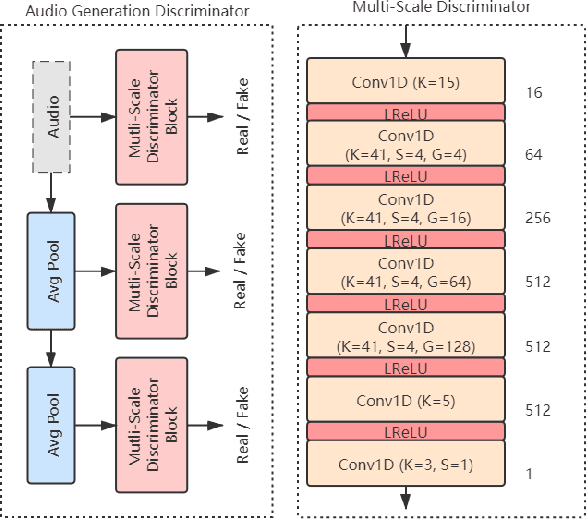

This paper describes an end-to-end adversarial singing voice conversion (EA-SVC) approach. It can directly generate arbitrary singing waveform by given phonetic posteriorgram (PPG) representing content, F0 representing pitch, and speaker embedding representing timbre, respectively. Proposed system is composed of three modules: generator $G$, the audio generation discriminator $D_{A}$, and the feature disentanglement discriminator $D_F$. The generator $G$ encodes the features in parallel and inversely transforms them into the target waveform. In order to make timbre conversion more stable and controllable, speaker embedding is further decomposed to the weighted sum of a group of trainable vectors representing different timbre clusters. Further, to realize more robust and accurate singing conversion, disentanglement discriminator $D_F$ is proposed to remove pitch and timbre related information that remains in the encoded PPG. Finally, a two-stage training is conducted to keep a stable and effective adversarial training process. Subjective evaluation results demonstrate the effectiveness of our proposed methods. Proposed system outperforms conventional cascade approach and the WaveNet based end-to-end approach in terms of both singing quality and singer similarity. Further objective analysis reveals that the model trained with the proposed two-stage training strategy can produce a smoother and sharper formant which leads to higher audio quality.