 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Context-aware Conversational Speech Synthesis
Paper and Code
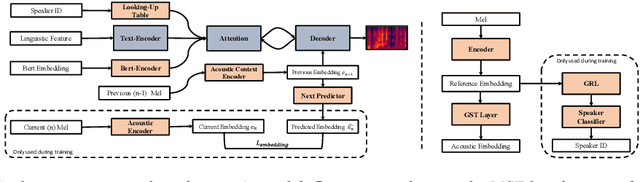
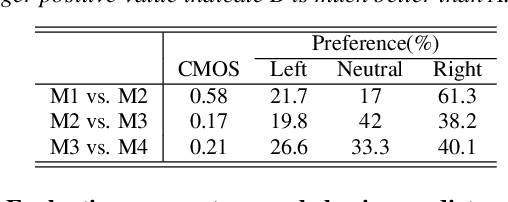

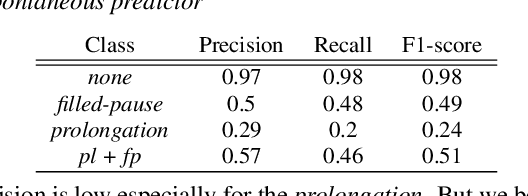
In spoken conversations, spontaneous behaviors like filled pause and prolongations always happen. Conversational partner tends to align features of their speech with their interlocutor which is known as entrainment. To produce human-like conversations, we propose a unified controllable spontaneous conversational speech synthesis framework to model the above two phenomena. Specifically, we use explicit labels to represent two typical spontaneous behaviors filled-pause and prolongation in the acoustic model and develop a neural network based predictor to predict the occurrences of the two behaviors from text. We subsequently develop an algorithm based on the predictor to control the occurrence frequency of the behaviors, making the synthesized speech vary from less disfluent to more disfluent. To model the speech entrainment at acoustic level, we utilize a context acoustic encoder to extract a global style embedding from the previous speech conditioning on the synthesizing of current speech. Furthermore, since the current and previous utterances belong to the different speakers in a conversation, we add a domain adversarial training module to eliminate the speaker-related information in the acoustic encoder while maintaining the style-related information. Experiments show that our proposed approach can synthesize realistic conversations and control the occurrences of the spontaneous behaviors naturally.