 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximizing Mutual Information for Tacotron
Paper and Code
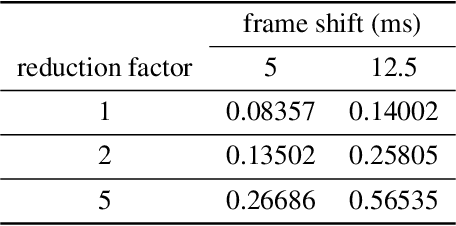
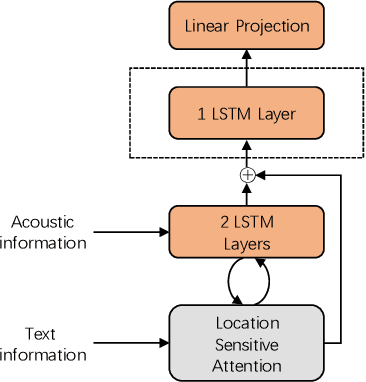
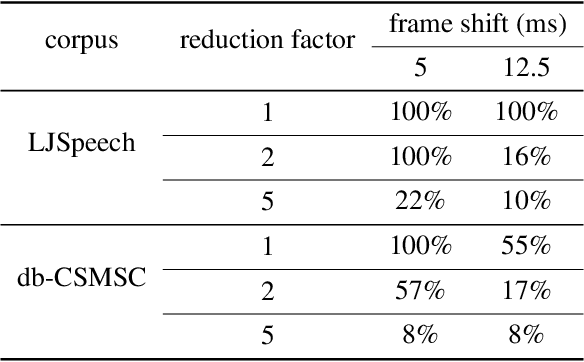
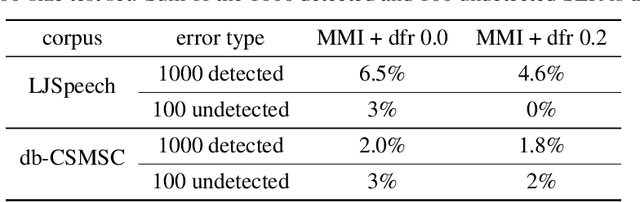
End-to-end speech synthesis method such as Tacotron, Tacotron2 and Transformer-TTS already achieves close to human quality performance. However compared to HMM-based method or NN-based frame-to-frame regression method, it is prone to some bad cases, such as missing words, repeating words and incomplete synthesis. More seriously, we cannot know whether such errors exist in a synthesized waveform or not unless we listen to it. We attribute the comparatively high sentence error rate to the local information preference of conditional autoregressive models. Inspired by the success of InfoGAN in learning interpretable representation by a mutual information regularization, in this paper, we propose to maximize the mutual information between the predicted acoustic features and the input text for end-to-end speech synthesis methods to address the local information preference problem and avoid such bad cases. What is more, we provide an indicator to detect errors in the predicted acoustic features as a byproduct. Experiment results show that our method can reduce the rate of bad cases and provide a reliable indicator to detect bad cases automatically.