 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccLock: Unlocking Identity with Heartbeat Using In-Ear Accelerometers
May 12, 2026The widespread use of earphones has enabled various sensing applications, including activity recognition, health monitoring, and context-aware computing. Among these, earphone-based user authentication has become a key technique by leveraging unique biometric features. However, existing earphone-based authentication systems face key limitations: they either require explicit user interaction or active speaker output, or suffer from poor accessibility and vulnerability to environmental noise, which hinders large-scale deployment. In this paper, we propose a passive authentication system, called AccLock, which leverages distinctive features extracted from in-ear BCG signals to enable secure and unobtrusive user verification. Our system offers several advantages over previous systems, including zero-involvement for both the device and the user, ubiquitous, and resilient to environmental noise. To realize this, we first design a two-stage denoising scheme to suppress both inherent and sporadic interference. To extract user-specific features, we then propose a disentanglement-based deep learning model, HIDNet, which explicitly separates user-specific features from shared nuisance components. Lastly, we develop a scalable authentication framework based on a Siamese network that eliminates the need for per-user classifier training. We conduct extensive experiments with 33 participants, achieving an average FAR of 3.13% and FRR of 2.99%, which demonstrates the practical feasibility of AccLock.
EmbodiSkill: Skill-Aware Reflection for Self-Evolving Embodied Agents
May 11, 2026Embodied agents can benefit from skills that guide object search, action execution, and state changes across diverse environments. Since embodied environments vary across layouts, object states, and other execution factors, these skills must self-evolve from trajectories generated during task execution. However, existing skill self-evolution methods are mainly developed in digital environments and often convert trajectories into coarse skill updates. Directly applying this paradigm to embodied settings is problematic, because a failed task execution may reflect not only incorrect skill content, but also an execution lapse in which the agent fails to follow valid guidance. We propose EmbodiSkill, a training-free framework for embodied skill self-evolution through skill-aware reflection and targeted revision. EmbodiSkill interprets each trajectory with respect to the current skill, uses skill-changing evidence to update the skill body, and uses execution-lapse evidence to preserve and emphasize valid guidance. Experiments on ALFWorld and EmbodiedBench show that EmbodiSkill consistently improves embodied task success. On ALFWorld, EmbodiSkill enables a frozen Qwen3.5-27B executor to reach 93.28% task success, outperforming GPT-5.2 used as a direct agent without skills by 31.58%. These results show that skill-aware self-evolution helps embodied agents accumulate reusable procedural knowledge from their own trajectories.
Enabling MoE on the Edge via Importance-Driven Expert Scheduling
Aug 26, 2025



The Mixture of Experts (MoE) architecture has emerged as a key technique for scaling Large Language Models by activating only a subset of experts per query. Deploying MoE on consumer-grade edge hardware, however, is constrained by limited device memory, making dynamic expert offloading essential. Unlike prior work that treats offloading purely as a scheduling problem, we leverage expert importance to guide decisions, substituting low-importance activated experts with functionally similar ones already cached in GPU memory, thereby preserving accuracy. As a result, this design reduces memory usage and data transfer, while largely eliminating PCIe overhead. In addition, we introduce a scheduling policy that maximizes the reuse ratio of GPU-cached experts, further boosting efficiency. Extensive evaluations show that our approach delivers 48% lower decoding latency with over 60% expert cache hit rate, while maintaining nearly lossless accuracy.
V-LoRA: An Efficient and Flexible System Boosts Vision Applications with LoRA LMM
Nov 01, 2024



Large Multimodal Models (LMMs) have shown significant progress in various complex vision tasks with the solid linguistic and reasoning capacity inherited from large language models (LMMs). Low-rank adaptation (LoRA) offers a promising method to integrate external knowledge into LMMs, compensating for their limitations on domain-specific tasks. However, the existing LoRA model serving is excessively computationally expensive and causes extremely high latency. In this paper, we present an end-to-end solution that empowers diverse vision tasks and enriches vision applications with LoRA LMMs. Our system, VaLoRA, enables accurate and efficient vision tasks by 1) an accuracy-aware LoRA adapter generation approach that generates LoRA adapters rich in domain-specific knowledge to meet application-specific accuracy requirements, 2) an adaptive-tiling LoRA adapters batching operator that efficiently computes concurrent heterogeneous LoRA adapters, and 3) a flexible LoRA adapter orchestration mechanism that manages application requests and LoRA adapters to achieve the lowest average response latency. We prototype VaLoRA on five popular vision tasks on three LMMs. Experiment results reveal that VaLoRA improves 24-62% of the accuracy compared to the original LMMs and reduces 20-89% of the latency compared to the state-of-the-art LoRA model serving systems.
BiSwift: Bandwidth Orchestrator for Multi-Stream Video Analytics on Edge
Dec 25, 2023


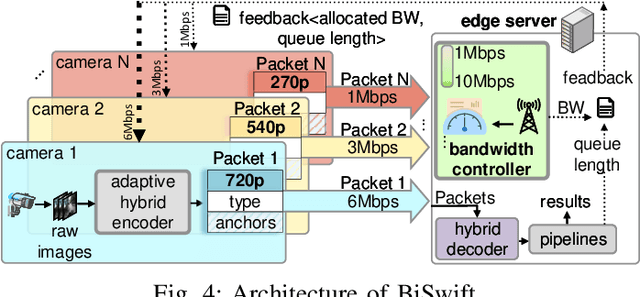
High-definition (HD) cameras for surveillance and road traffic have experienced tremendous growth, demanding intensive computation resources for real-time analytics. Recently, offloading frames from the front-end device to the back-end edge server has shown great promise. In multi-stream competitive environments, efficient bandwidth management and proper scheduling are crucial to ensure both high inference accuracy and high throughput. To achieve this goal, we propose BiSwift, a bi-level framework that scales the concurrent real-time video analytics by a novel adaptive hybrid codec integrated with multi-level pipelines, and a global bandwidth controller for multiple video streams. The lower-level front-back-end collaborative mechanism (called adaptive hybrid codec) locally optimizes the accuracy and accelerates end-to-end video analytics for a single stream. The upper-level scheduler aims to accuracy fairness among multiple streams via the global bandwidth controller. The evaluation of BiSwift shows that BiSwift is able to real-time object detection on 9 streams with an edge device only equipped with an NVIDIA RTX3070 (8G) GPU. BiSwift improves 10%$\sim$21% accuracy and presents 1.2$\sim$9$\times$ throughput compared with the state-of-the-art video analytics pipelines.
AccDecoder: Accelerated Decoding for Neural-enhanced Video Analytics
Jan 24, 2023The quality of the video stream is key to neural network-based video analytics. However, low-quality video is inevitably collected by existing surveillance systems because of poor quality cameras or over-compressed/pruned video streaming protocols, e.g., as a result of upstream bandwidth limit. To address this issue, existing studies use quality enhancers (e.g., neural super-resolution) to improve the quality of videos (e.g., resolution) and eventually ensure inference accuracy. Nevertheless, directly applying quality enhancers does not work in practice because it will introduce unacceptable latency. In this paper, we present AccDecoder, a novel accelerated decoder for real-time and neural-enhanced video analytics. AccDecoder can select a few frames adaptively via Deep Reinforcement Learning (DRL) to enhance the quality by neural super-resolution and then up-scale the unselected frames that reference them, which leads to 6-21% accuracy improvement. AccDecoder provides efficient inference capability via filtering important frames using DRL for DNN-based inference and reusing the results for the other frames via extracting the reference relationship among frames and blocks, which results in a latency reduction of 20-80% than baselines.
Quick and Reliable LoRa Physical-layer Data Aggregation through Multi-Packet Reception
Dec 13, 2022This paper presents a Long Range (LoRa) physical-layer data aggregation system (LoRaPDA) that aggregates data (e.g., sum, average, min, max) directly in the physical layer. In particular, after coordinating a few nodes to transmit their data simultaneously, the gateway leverages a new multi-packet reception (MPR) approach to compute aggregate data from the phase-asynchronous superimposed signal. Different from the analog approach which requires additional power synchronization and phase synchronization, our MRP-based digital approach is compatible with commercial LoRa nodes and is more reliable. Different from traditional MPR approaches that are designed for the collision decoding scenario, our new MPR approach allows simultaneous transmissions with small packet arrival time offsets, and addresses a new co-located peak problem through the following components: 1) an improved channel and offset estimation algorithm that enables accurate phase tracking in each symbol, 2) a new symbol demodulation algorithm that finds the maximum likelihood sequence of nodes' data, and 3) a soft-decision packet decoding algorithm that utilizes the likelihoods of several sequences to improve decoding performance. Trace-driven simulation results show that the symbol demodulation algorithm outperforms the state-of-the-art MPR decoder by 5.3$\times$ in terms of physical-layer throughput, and the soft decoder is more robust to unavoidable adverse phase misalignment and estimation error in practice. Moreover, LoRaPDA outperforms the state-of-the-art MPR scheme by at least 2.1$\times$ for all SNRs in terms of network throughput, demonstrating quick and reliable data aggregation.
Serverless Federated Learning for UAV Networks: Architecture, Challenges, and Opportunities
Apr 15, 2021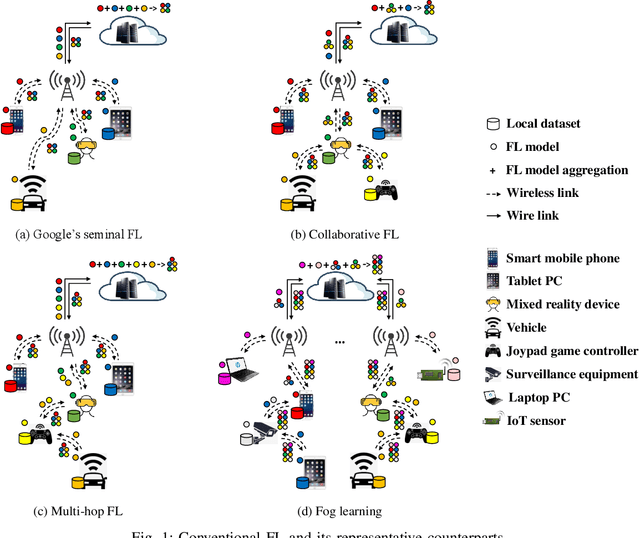
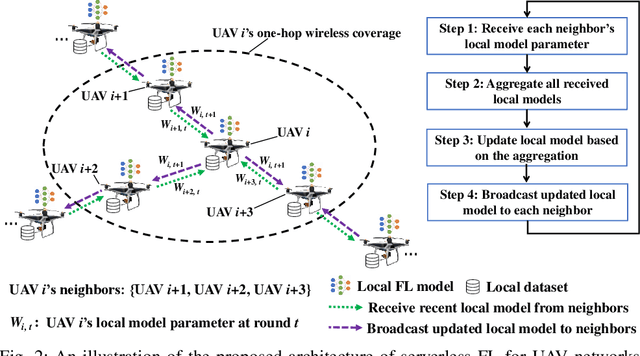
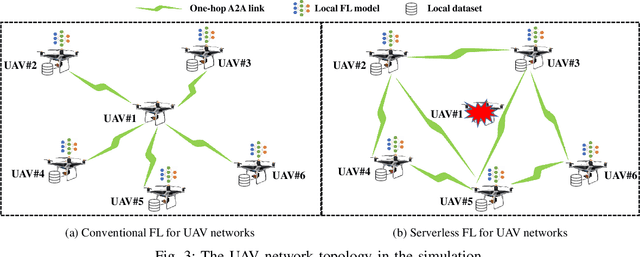
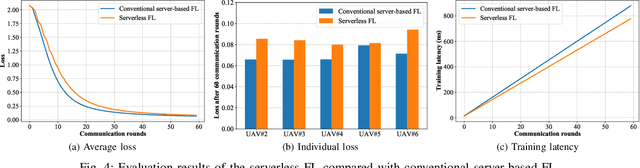
Unmanned aerial vehicles (UAVs), or say drones, are envisioned to support extensive applications in next-generation wireless networks in both civil and military fields. Empowering UAVs networks intelligence by artificial intelligence (AI) especially machine learning (ML) techniques is inevitable and appealing to enable the aforementioned applications. To solve the problems of traditional cloud-centric ML for UAV networks such as privacy concern, unacceptable latency, and resource burden, a distributed ML technique, i.e., federated learning (FL), has been recently proposed to enable multiple UAVs to collaboratively train ML model without letting out raw data. However, almost all existing FL paradigms are server-based, i.e., a central entity is in charge of ML model aggregation and fusion over the whole network, which could result in the issue of a single point of failure and are inappropriate to UAV networks with both unreliable nodes and links. To address the above issue, in this article, we propose a novel architecture called SELF-UN (\underline{SE}rver\underline{L}ess \underline{F}L for \underline{U}AV \underline{N}etworks), which enables FL within UAV networks without a central entity. We also conduct a preliminary simulation study to validate the feasibility and effectiveness of the SELF-UN architecture. Finally, we discuss the main challenges and potential research directions in the SELF-UN.