 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion based Zero-shot Medical Image-to-Image Translation for Cross Modality Segmentation
Apr 09, 2024

Cross-modality image segmentation aims to segment the target modalities using a method designed in the source modality. Deep generative models can translate the target modality images into the source modality, thus enabling cross-modality segmentation. However, a vast body of existing cross-modality image translation methods relies on supervised learning. In this work, we aim to address the challenge of zero-shot learning-based image translation tasks (extreme scenarios in the target modality is unseen in the training phase). To leverage generative learning for zero-shot cross-modality image segmentation, we propose a novel unsupervised image translation method. The framework learns to translate the unseen source image to the target modality for image segmentation by leveraging the inherent statistical consistency between different modalities for diffusion guidance. Our framework captures identical cross-modality features in the statistical domain, offering diffusion guidance without relying on direct mappings between the source and target domains. This advantage allows our method to adapt to changing source domains without the need for retraining, making it highly practical when sufficient labeled source domain data is not available. The proposed framework is validated in zero-shot cross-modality image segmentation tasks through empirical comparisons with influential generative models, including adversarial-based and diffusion-based models.
BiSwift: Bandwidth Orchestrator for Multi-Stream Video Analytics on Edge
Dec 25, 2023


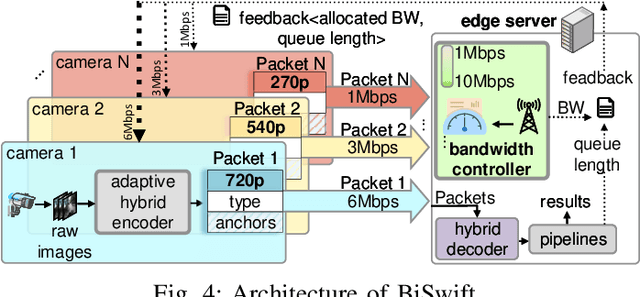
High-definition (HD) cameras for surveillance and road traffic have experienced tremendous growth, demanding intensive computation resources for real-time analytics. Recently, offloading frames from the front-end device to the back-end edge server has shown great promise. In multi-stream competitive environments, efficient bandwidth management and proper scheduling are crucial to ensure both high inference accuracy and high throughput. To achieve this goal, we propose BiSwift, a bi-level framework that scales the concurrent real-time video analytics by a novel adaptive hybrid codec integrated with multi-level pipelines, and a global bandwidth controller for multiple video streams. The lower-level front-back-end collaborative mechanism (called adaptive hybrid codec) locally optimizes the accuracy and accelerates end-to-end video analytics for a single stream. The upper-level scheduler aims to accuracy fairness among multiple streams via the global bandwidth controller. The evaluation of BiSwift shows that BiSwift is able to real-time object detection on 9 streams with an edge device only equipped with an NVIDIA RTX3070 (8G) GPU. BiSwift improves 10%$\sim$21% accuracy and presents 1.2$\sim$9$\times$ throughput compared with the state-of-the-art video analytics pipelines.
AccDecoder: Accelerated Decoding for Neural-enhanced Video Analytics
Jan 24, 2023The quality of the video stream is key to neural network-based video analytics. However, low-quality video is inevitably collected by existing surveillance systems because of poor quality cameras or over-compressed/pruned video streaming protocols, e.g., as a result of upstream bandwidth limit. To address this issue, existing studies use quality enhancers (e.g., neural super-resolution) to improve the quality of videos (e.g., resolution) and eventually ensure inference accuracy. Nevertheless, directly applying quality enhancers does not work in practice because it will introduce unacceptable latency. In this paper, we present AccDecoder, a novel accelerated decoder for real-time and neural-enhanced video analytics. AccDecoder can select a few frames adaptively via Deep Reinforcement Learning (DRL) to enhance the quality by neural super-resolution and then up-scale the unselected frames that reference them, which leads to 6-21% accuracy improvement. AccDecoder provides efficient inference capability via filtering important frames using DRL for DNN-based inference and reusing the results for the other frames via extracting the reference relationship among frames and blocks, which results in a latency reduction of 20-80% than baselines.
DACOM: Learning Delay-Aware Communication for Multi-Agent Reinforcement Learning
Dec 03, 2022Communication is supposed to improve multi-agent collaboration and overall performance in cooperative Multi-agent reinforcement learning (MARL). However, such improvements are prevalently limited in practice since most existing communication schemes ignore communication overheads (e.g., communication delays). In this paper, we demonstrate that ignoring communication delays has detrimental effects on collaborations, especially in delay-sensitive tasks such as autonomous driving. To mitigate this impact, we design a delay-aware multi-agent communication model (DACOM) to adapt communication to delays. Specifically, DACOM introduces a component, TimeNet, that is responsible for adjusting the waiting time of an agent to receive messages from other agents such that the uncertainty associated with delay can be addressed. Our experiments reveal that DACOM has a non-negligible performance improvement over other mechanisms by making a better trade-off between the benefits of communication and the costs of waiting for messages.
PP-MARL: Efficient Privacy-Preserving MARL for Cooperative Intelligence in Communication
Apr 26, 2022

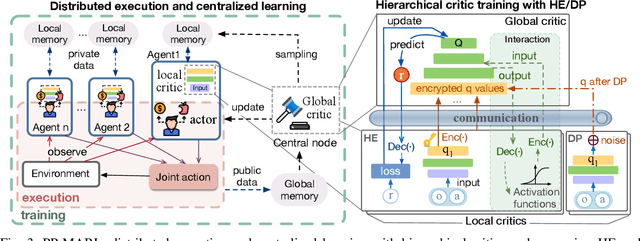
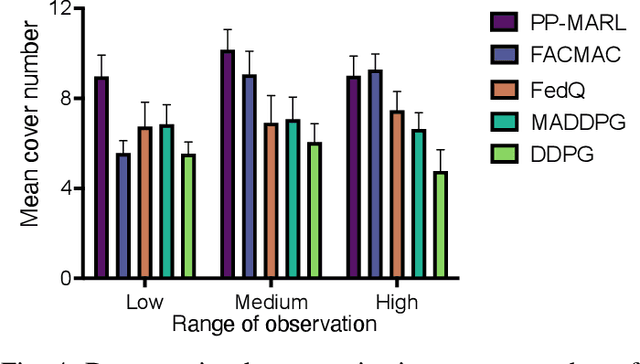
Artificial intelligence (AI) has been introduced in communication networks and services to improve efficiency via self-optimization. Cooperative intelligence (CI), also known as collective intelligence and collaborative intelligence, is expected to become an integral element in next-generation networks because it can aggregate the capabilities and intelligence of multiple devices. However, privacy issues may intimidate, obstruct, and hinder the deployment of CI in practice because collaboration heavily relies on data and information sharing. Additional practical constraints in communication (e.g., limited bandwidth) further limit the performance of CI. To overcome these challenges, we propose PP-MARL, an efficient privacy-preserving learning scheme based on multi-agent reinforcement learning (MARL). We apply and evaluate our scheme in two communication-related use cases: mobility management in drone-assisted communication and network control with edge intelligence. Simulation results reveal that the proposed scheme can achieve efficient and reliable collaboration with 1.1-6 times better privacy protection and lower overheads (e.g., 84-91% reduction in bandwidth) than state-of-the-art approaches.