 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Collapse-Inspired Multi-Label Federated Learning under Label-Distribution Skew
Sep 16, 2025Federated Learning (FL) enables collaborative model training across distributed clients while preserving data privacy. However, the performance of deep learning often deteriorates in FL due to decentralized and heterogeneous data. This challenge is further amplified in multi-label scenarios, where data exhibit complex characteristics such as label co-occurrence, inter-label dependency, and discrepancies between local and global label relationships. While most existing FL research primarily focuses on single-label classification, many real-world applications, particularly in domains such as medical imaging, often involve multi-label settings. In this paper, we address this important yet underexplored scenario in FL, where clients hold multi-label data with skewed label distributions. Neural Collapse (NC) describes a geometric structure in the latent feature space where features of each class collapse to their class mean with vanishing intra-class variance, and the class means form a maximally separated configuration. Motivated by this theory, we propose a method to align feature distributions across clients and to learn high-quality, well-clustered representations. To make the NC-structure applicable to multi-label settings, where image-level features may contain multiple semantic concepts, we introduce a feature disentanglement module that extracts semantically specific features. The clustering of these disentangled class-wise features is guided by a predefined shared NC structure, which mitigates potential conflicts between client models due to diverse local data distributions. In addition, we design regularisation losses to encourage compact clustering in the latent feature space. Experiments conducted on four benchmark datasets across eight diverse settings demonstrate that our approach outperforms existing methods, validating its effectiveness in this challenging FL scenario.
Diffusion based Zero-shot Medical Image-to-Image Translation for Cross Modality Segmentation
Apr 09, 2024

Cross-modality image segmentation aims to segment the target modalities using a method designed in the source modality. Deep generative models can translate the target modality images into the source modality, thus enabling cross-modality segmentation. However, a vast body of existing cross-modality image translation methods relies on supervised learning. In this work, we aim to address the challenge of zero-shot learning-based image translation tasks (extreme scenarios in the target modality is unseen in the training phase). To leverage generative learning for zero-shot cross-modality image segmentation, we propose a novel unsupervised image translation method. The framework learns to translate the unseen source image to the target modality for image segmentation by leveraging the inherent statistical consistency between different modalities for diffusion guidance. Our framework captures identical cross-modality features in the statistical domain, offering diffusion guidance without relying on direct mappings between the source and target domains. This advantage allows our method to adapt to changing source domains without the need for retraining, making it highly practical when sufficient labeled source domain data is not available. The proposed framework is validated in zero-shot cross-modality image segmentation tasks through empirical comparisons with influential generative models, including adversarial-based and diffusion-based models.
Zero-shot-Learning Cross-Modality Data Translation Through Mutual Information Guided Stochastic Diffusion
Jan 31, 2023
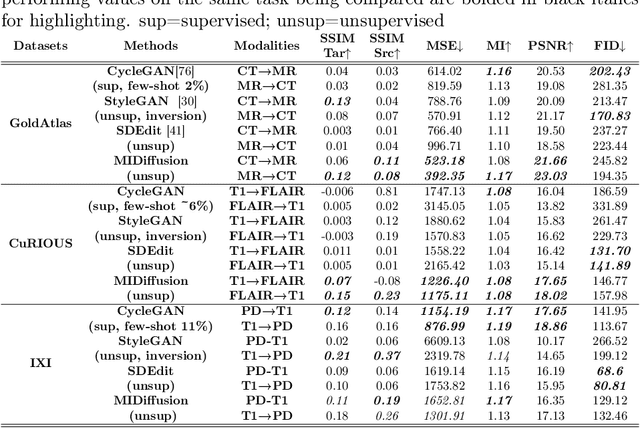
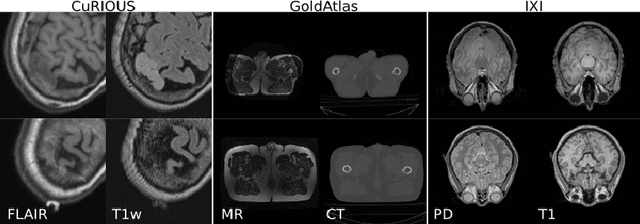

Cross-modality data translation has attracted great interest in image computing. Deep generative models (\textit{e.g.}, GANs) show performance improvement in tackling those problems. Nevertheless, as a fundamental challenge in image translation, the problem of Zero-shot-Learning Cross-Modality Data Translation with fidelity remains unanswered. This paper proposes a new unsupervised zero-shot-learning method named Mutual Information guided Diffusion cross-modality data translation Model (MIDiffusion), which learns to translate the unseen source data to the target domain. The MIDiffusion leverages a score-matching-based generative model, which learns the prior knowledge in the target domain. We propose a differentiable local-wise-MI-Layer ($LMI$) for conditioning the iterative denoising sampling. The $LMI$ captures the identical cross-modality features in the statistical domain for the diffusion guidance; thus, our method does not require retraining when the source domain is changed, as it does not rely on any direct mapping between the source and target domains. This advantage is critical for applying cross-modality data translation methods in practice, as a reasonable amount of source domain dataset is not always available for supervised training. We empirically show the advanced performance of MIDiffusion in comparison with an influential group of generative models, including adversarial-based and other score-matching-based models.
Unsupervised Echocardiography Registration through Patch-based MLPs and Transformers
Nov 21, 2022



Image registration is an essential but challenging task in medical image computing, especially for echocardiography, where the anatomical structures are relatively noisy compared to other imaging modalities. Traditional (non-learning) registration approaches rely on the iterative optimization of a similarity metric which is usually costly in time complexity. In recent years, convolutional neural network (CNN) based image registration methods have shown good effectiveness. In the meantime, recent studies show that the attention-based model (e.g., Transformer) can bring superior performance in pattern recognition tasks. In contrast, whether the superior performance of the Transformer comes from the long-winded architecture or is attributed to the use of patches for dividing the inputs is unclear yet. This work introduces three patch-based frameworks for image registration using MLPs and transformers. We provide experiments on 2D-echocardiography registration to answer the former question partially and provide a benchmark solution. Our results on a large public 2D echocardiography dataset show that the patch-based MLP/Transformer model can be effectively used for unsupervised echocardiography registration. They demonstrate comparable and even better registration performance than a popular CNN registration model. In particular, patch-based models better preserve volume changes in terms of Jacobian determinants, thus generating robust registration fields with less unrealistic deformation. Our results demonstrate that patch-based learning methods, whether with attention or not, can perform high-performance unsupervised registration tasks with adequate time and space complexity. Our codes are available https://gitlab.inria.fr/epione/mlp\_transformer\_registration