 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial regularisation for improved accuracy and interpretability in keypoint-based registration
Mar 07, 2025Unsupervised registration strategies bypass requirements in ground truth transforms or segmentations by optimising similarity metrics between fixed and moved volumes. Among these methods, a recent subclass of approaches based on unsupervised keypoint detection stand out as very promising for interpretability. Specifically, these methods train a network to predict feature maps for fixed and moving images, from which explainable centres of mass are computed to obtain point clouds, that are then aligned in closed-form. However, the features returned by the network often yield spatially diffuse patterns that are hard to interpret, thus undermining the purpose of keypoint-based registration. Here, we propose a three-fold loss to regularise the spatial distribution of the features. First, we use the KL divergence to model features as point spread functions that we interpret as probabilistic keypoints. Then, we sharpen the spatial distributions of these features to increase the precision of the detected landmarks. Finally, we introduce a new repulsive loss across keypoints to encourage spatial diversity. Overall, our loss considerably improves the interpretability of the features, which now correspond to precise and anatomically meaningful landmarks. We demonstrate our three-fold loss in foetal rigid motion tracking and brain MRI affine registration tasks, where it not only outperforms state-of-the-art unsupervised strategies, but also bridges the gap with state-of-the-art supervised methods. Our code is available at https://github.com/BenBillot/spatial_regularisation.
Generative Medical Image Anonymization Based on Latent Code Projection and Optimization
Jan 15, 2025Medical image anonymization aims to protect patient privacy by removing identifying information, while preserving the data utility to solve downstream tasks. In this paper, we address the medical image anonymization problem with a two-stage solution: latent code projection and optimization. In the projection stage, we design a streamlined encoder to project input images into a latent space and propose a co-training scheme to enhance the projection process. In the optimization stage, we refine the latent code using two deep loss functions designed to address the trade-off between identity protection and data utility dedicated to medical images. Through a comprehensive set of qualitative and quantitative experiments, we showcase the effectiveness of our approach on the MIMIC-CXR chest X-ray dataset by generating anonymized synthetic images that can serve as training set for detecting lung pathologies. Source codes are available at https://github.com/Huiyu-Li/GMIA.
Second Order Kinematic Surface Fitting in Anatomical Structures
Jan 29, 2024Symmetry detection and morphological classification of anatomical structures play pivotal roles in medical image analysis. The application of kinematic surface fitting, a method for characterizing shapes through parametric stationary velocity fields, has shown promising results in computer vision and computer-aided design. However, existing research has predominantly focused on first order rotational velocity fields, which may not adequately capture the intricate curved and twisted nature of anatomical structures. To address this limitation, we propose an innovative approach utilizing a second order velocity field for kinematic surface fitting. This advancement accommodates higher rotational shape complexity and improves the accuracy of symmetry detection in anatomical structures. We introduce a robust fitting technique and validate its performance through testing on synthetic shapes and real anatomical structures. Our method not only enables the detection of curved rotational symmetries (core lines) but also facilitates morphological classification by deriving intrinsic shape parameters related to curvature and torsion. We illustrate the usefulness of our technique by categorizing the shape of human cochleae in terms of the intrinsic velocity field parameters. The results showcase the potential of our method as a valuable tool for medical image analysis, contributing to the assessment of complex anatomical shapes.
Morphologically-Aware Consensus Computation via Heuristics-based IterATive Optimization (MACCHIatO)
Sep 14, 2023The extraction of consensus segmentations from several binary or probabilistic masks is important to solve various tasks such as the analysis of inter-rater variability or the fusion of several neural network outputs. One of the most widely used methods to obtain such a consensus segmentation is the STAPLE algorithm. In this paper, we first demonstrate that the output of that algorithm is heavily impacted by the background size of images and the choice of the prior. We then propose a new method to construct a binary or a probabilistic consensus segmentation based on the Fr\'{e}chet means of carefully chosen distances which makes it totally independent of the image background size. We provide a heuristic approach to optimize this criterion such that a voxel's class is fully determined by its voxel-wise distance to the different masks, the connected component it belongs to and the group of raters who segmented it. We compared extensively our method on several datasets with the STAPLE method and the naive segmentation averaging method, showing that it leads to binary consensus masks of intermediate size between Majority Voting and STAPLE and to different posterior probabilities than Mask Averaging and STAPLE methods. Our code is available at https://gitlab.inria.fr/dhamzaou/jaccardmap .
* Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://melba-journal.org/2023:013
Zero-shot-Learning Cross-Modality Data Translation Through Mutual Information Guided Stochastic Diffusion
Jan 31, 2023
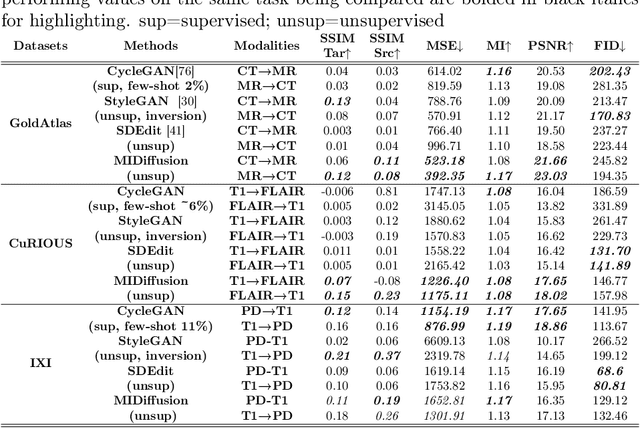

Cross-modality data translation has attracted great interest in image computing. Deep generative models (\textit{e.g.}, GANs) show performance improvement in tackling those problems. Nevertheless, as a fundamental challenge in image translation, the problem of Zero-shot-Learning Cross-Modality Data Translation with fidelity remains unanswered. This paper proposes a new unsupervised zero-shot-learning method named Mutual Information guided Diffusion cross-modality data translation Model (MIDiffusion), which learns to translate the unseen source data to the target domain. The MIDiffusion leverages a score-matching-based generative model, which learns the prior knowledge in the target domain. We propose a differentiable local-wise-MI-Layer ($LMI$) for conditioning the iterative denoising sampling. The $LMI$ captures the identical cross-modality features in the statistical domain for the diffusion guidance; thus, our method does not require retraining when the source domain is changed, as it does not rely on any direct mapping between the source and target domains. This advantage is critical for applying cross-modality data translation methods in practice, as a reasonable amount of source domain dataset is not always available for supervised training. We empirically show the advanced performance of MIDiffusion in comparison with an influential group of generative models, including adversarial-based and other score-matching-based models.
Data Stealing Attack on Medical Images: Is it Safe to Export Networks from Data Lakes?
Jun 07, 2022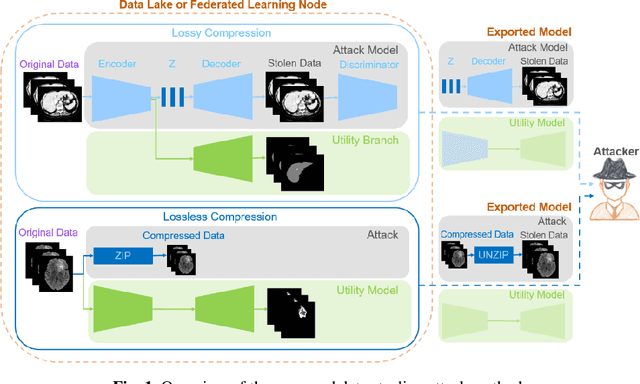
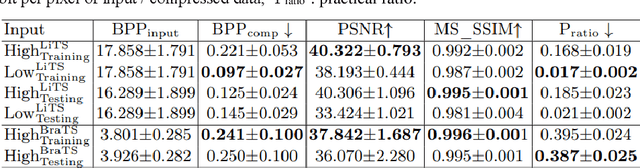
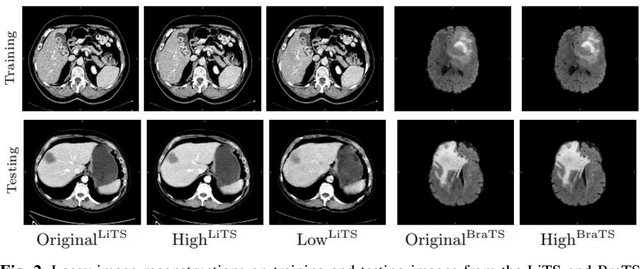

In privacy-preserving machine learning, it is common that the owner of the learned model does not have any physical access to the data. Instead, only a secured remote access to a data lake is granted to the model owner without any ability to retrieve data from the data lake. Yet, the model owner may want to export the trained model periodically from the remote repository and a question arises whether this may cause is a risk of data leakage. In this paper, we introduce the concept of data stealing attack during the export of neural networks. It consists in hiding some information in the exported network that allows the reconstruction outside the data lake of images initially stored in that data lake. More precisely, we show that it is possible to train a network that can perform lossy image compression and at the same time solve some utility tasks such as image segmentation. The attack then proceeds by exporting the compression decoder network together with some image codes that leads to the image reconstruction outside the data lake. We explore the feasibility of such attacks on databases of CT and MR images, showing that it is possible to obtain perceptually meaningful reconstructions of the target dataset, and that the stolen dataset can be used in turns to solve a broad range of tasks. Comprehensive experiments and analyses show that data stealing attacks should be considered as a threat for sensitive imaging data sources.
Super-Resolved Microbubble Localization in Single-Channel Ultrasound RF Signals Using Deep Learning
Apr 09, 2022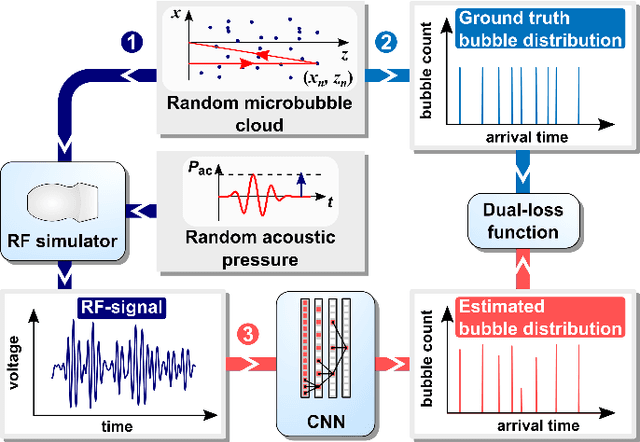
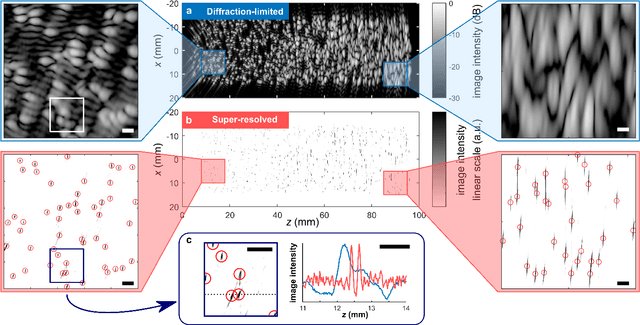
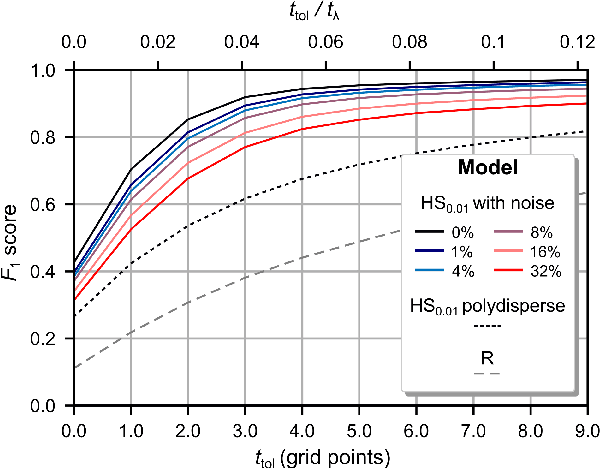
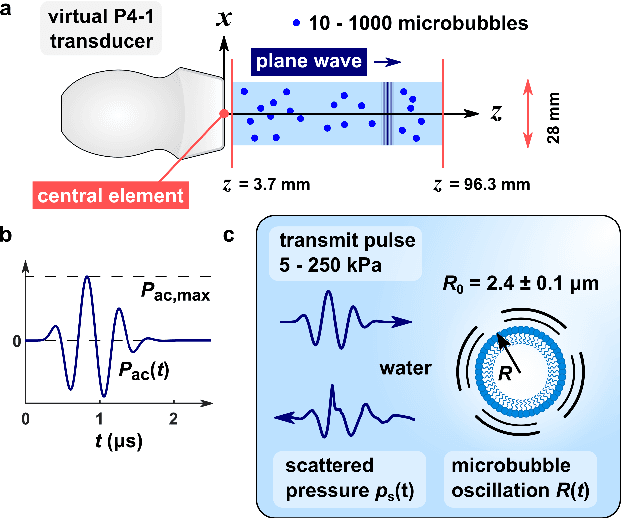
Recently, super-resolution ultrasound imaging with ultrasound localization microscopy (ULM) has received much attention. However, ULM relies on low concentrations of microbubbles in the blood vessels, ultimately resulting in long acquisition times. Here, we present an alternative super-resolution approach, based on direct deconvolution of single-channel ultrasound radio-frequency (RF) signals with a one-dimensional dilated convolutional neural network (CNN). This work focuses on low-frequency ultrasound (1.7 MHz) for deep imaging (10 cm) of a dense cloud of monodisperse microbubbles (up to 1000 microbubbles in the measurement volume, corresponding to an average echo overlap of 94%). Data are generated with a simulator that uses a large range of acoustic pressures (5-250 kPa) and captures the full, nonlinear response of resonant, lipid-coated microbubbles. The network is trained with a novel dual-loss function, which features elements of both a classification loss and a regression loss and improves the detection-localization characteristics of the output. Whereas imposing a localization tolerance of 0 yields poor detection metrics, imposing a localization tolerance corresponding to 4% of the wavelength yields a precision and recall of both 0.90. Furthermore, the detection improves with increasing acoustic pressure and deteriorates with increasing microbubble density. The potential of the presented approach to super-resolution ultrasound imaging is demonstrated with a delay-and-sum reconstruction with deconvolved element data. The resulting image shows an order-of-magnitude gain in axial resolution compared to a delay-and-sum reconstruction with unprocessed element data.
Geodesic squared exponential kernel for non-rigid shape registration
Dec 22, 2021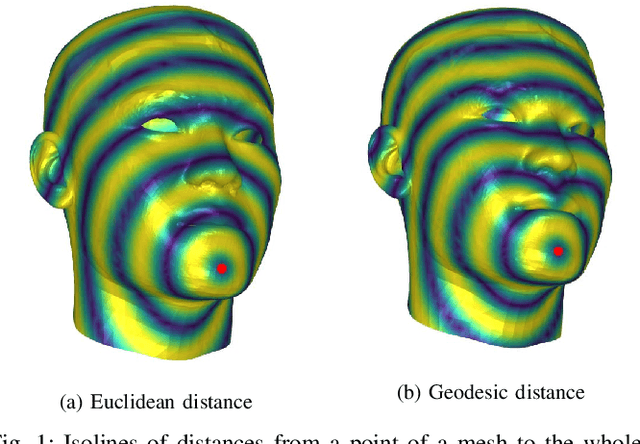

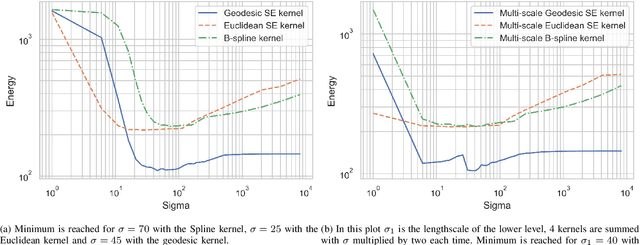
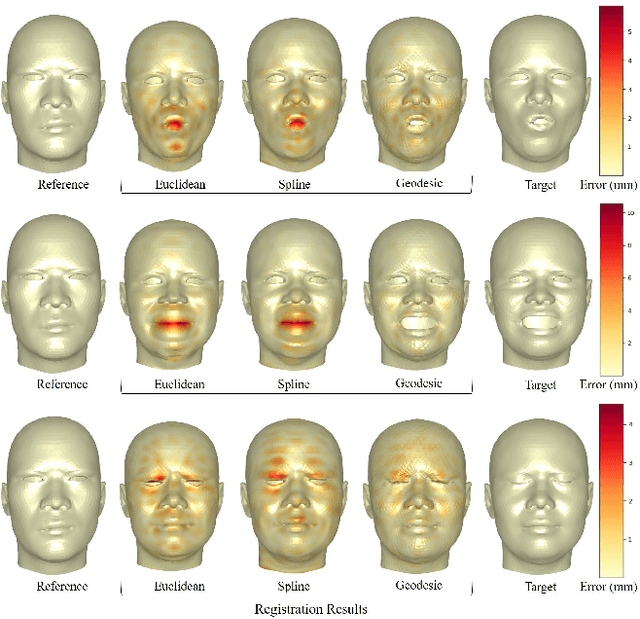
This work addresses the problem of non-rigid registration of 3D scans, which is at the core of shape modeling techniques. Firstly, we propose a new kernel based on geodesic distances for the Gaussian Process Morphable Models (GPMMs) framework. The use of geodesic distances into the kernel makes it more adapted to the topological and geometric characteristics of the surface and leads to more realistic deformations around holes and curved areas. Since the kernel possesses hyperparameters we have optimized them for the task of face registration on the FaceWarehouse dataset. We show that the Geodesic squared exponential kernel performs significantly better than state of the art kernels for the task of face registration on all the 20 expressions of the FaceWarehouse dataset. Secondly, we propose a modification of the loss function used in the non-rigid ICP registration algorithm, that allows to weight the correspondences according to the confidence given to them. As a use case, we show that we can make the registration more robust to outliers in the 3D scans, such as non-skin parts.
Attention for Image Registration (AiR): an unsupervised Transformer approach
May 05, 2021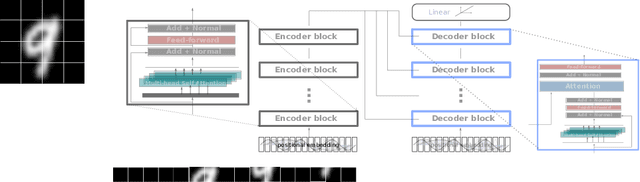

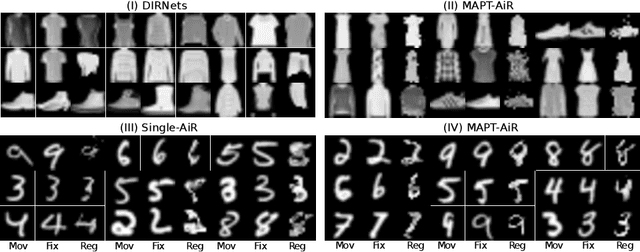
Image registration as an important basis in signal processing task often encounter the problem of stability and efficiency. Non-learning registration approaches rely on the optimization of the similarity metrics between the fix and moving images. Yet, those approaches are usually costly in both time and space complexity. The problem can be worse when the size of the image is large or the deformations between the images are severe. Recently, deep learning, or precisely saying, the convolutional neural network (CNN) based image registration methods have been widely investigated in the research community and show promising effectiveness to overcome the weakness of non-learning based methods. To explore the advanced learning approaches in image registration problem for solving practical issues, we present in this paper a method of introducing attention mechanism in deformable image registration problem. The proposed approach is based on learning the deformation field with a Transformer framework (AiR) that does not rely on the CNN but can be efficiently trained on GPGPU devices also. In a more vivid interpretation: we treat the image registration problem as the same as a language translation task and introducing a Transformer to tackle the problem. Our method learns an unsupervised generated deformation map and is tested on two benchmark datasets. The source code of the AiR will be released at Gitlab.
Combining Bayesian and Deep Learning Methods for the Delineation of the Fan in Ultrasound Images
Feb 02, 2021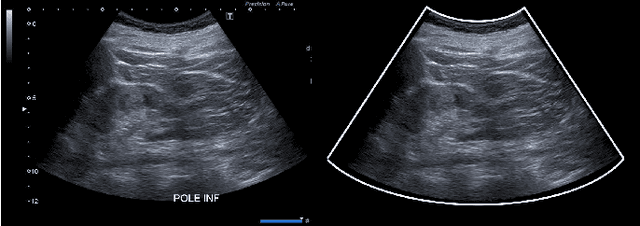
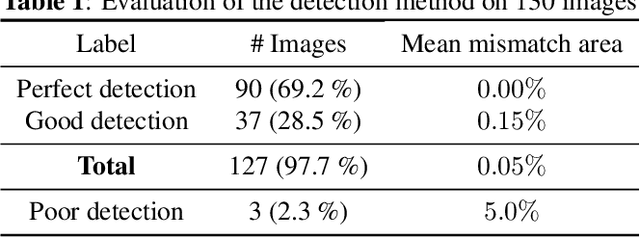
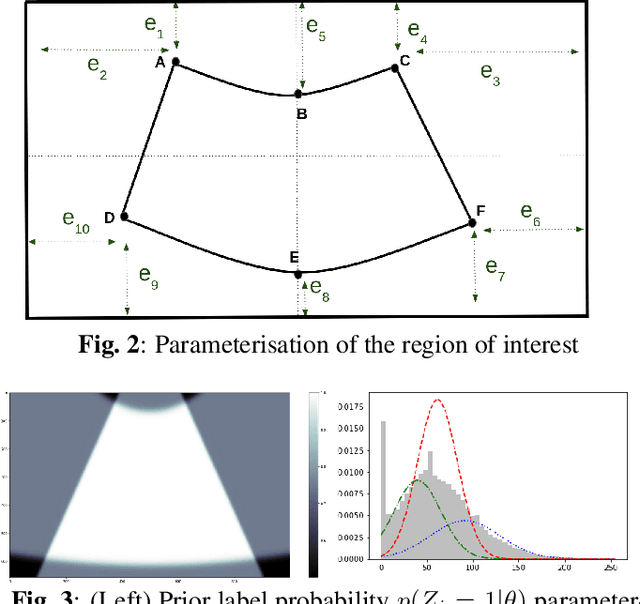
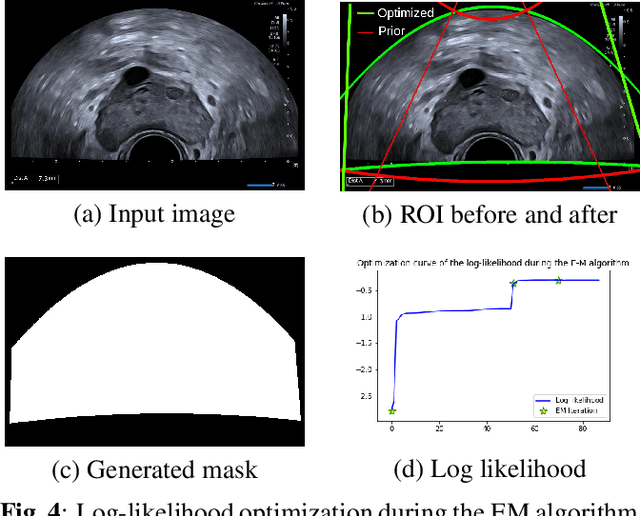
Ultrasound (US) images usually contain identifying information outside the ultrasound fan area and manual annotations placed by the sonographers during exams. For those images to be exploitable in a Deep Learning framework, one needs to first delineate the border of the fan which delimits the ultrasound fan area and then remove other annotations inside. We propose a parametric probabilistic approach for the first task. We make use of this method to generate a training data set with segmentation masks of the region of interest (ROI) and train a U-Net to perform the same task in a supervised way, thus considerably reducing computational time of the method, one hundred and sixty times faster. These images are then processed with existing inpainting methods to remove annotations present inside the fan area. To the best of our knowledge, this is the first parametric approach to quickly detect the fan in an ultrasound image without any other information than the image itself.