 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Permission Manipulation: Can We Trust Large Multimodal Model Powered GUI Agents?
Jan 18, 2026Large multimodal model powered GUI agents are emerging as high-privilege operators on mobile platforms, entrusted with perceiving screen content and injecting inputs. However, their design operates under the implicit assumption of Visual Atomicity: that the UI state remains invariant between observation and action. We demonstrate that this assumption is fundamentally invalid in Android, creating a critical attack surface. We present Action Rebinding, a novel attack that allows a seemingly-benign app with zero dangerous permissions to rebind an agent's execution. By exploiting the inevitable observation-to-action gap inherent in the agent's reasoning pipeline, the attacker triggers foreground transitions to rebind the agent's planned action toward the target app. We weaponize the agent's task-recovery logic and Android's UI state preservation to orchestrate programmable, multi-step attack chains. Furthermore, we introduce an Intent Alignment Strategy (IAS) that manipulates the agent's reasoning process to rationalize UI states, enabling it to bypass verification gates (e.g., confirmation dialogs) that would otherwise be rejected. We evaluate Action Rebinding Attacks on six widely-used Android GUI agents across 15 tasks. Our results demonstrate a 100% success rate for atomic action rebinding and the ability to reliably orchestrate multi-step attack chains. With IAS, the success rate in bypassing verification gates increases (from 0% to up to 100%). Notably, the attacker application requires no sensitive permissions and contains no privileged API calls, achieving a 0% detection rate across malware scanners (e.g., VirusTotal). Our findings reveal a fundamental architectural flaw in current agent-OS integration and provide critical insights for the secure design of future agent systems. To access experimental logs and demonstration videos, please contact yi_qian@smail.nju.edu.cn.
Enabling MoE on the Edge via Importance-Driven Expert Scheduling
Aug 26, 2025The Mixture of Experts (MoE) architecture has emerged as a key technique for scaling Large Language Models by activating only a subset of experts per query. Deploying MoE on consumer-grade edge hardware, however, is constrained by limited device memory, making dynamic expert offloading essential. Unlike prior work that treats offloading purely as a scheduling problem, we leverage expert importance to guide decisions, substituting low-importance activated experts with functionally similar ones already cached in GPU memory, thereby preserving accuracy. As a result, this design reduces memory usage and data transfer, while largely eliminating PCIe overhead. In addition, we introduce a scheduling policy that maximizes the reuse ratio of GPU-cached experts, further boosting efficiency. Extensive evaluations show that our approach delivers 48% lower decoding latency with over 60% expert cache hit rate, while maintaining nearly lossless accuracy.
MacFormer: Semantic Segmentation with Fine Object Boundaries
Aug 11, 2024



Semantic segmentation involves assigning a specific category to each pixel in an image. While Vision Transformer-based models have made significant progress, current semantic segmentation methods often struggle with precise predictions in localized areas like object boundaries. To tackle this challenge, we introduce a new semantic segmentation architecture, ``MacFormer'', which features two key components. Firstly, using learnable agent tokens, a Mutual Agent Cross-Attention (MACA) mechanism effectively facilitates the bidirectional integration of features across encoder and decoder layers. This enables better preservation of low-level features, such as elementary edges, during decoding. Secondly, a Frequency Enhancement Module (FEM) in the decoder leverages high-frequency and low-frequency components to boost features in the frequency domain, benefiting object boundaries with minimal computational complexity increase. MacFormer is demonstrated to be compatible with various network architectures and outperforms existing methods in both accuracy and efficiency on benchmark datasets ADE20K and Cityscapes under different computational constraints.
HAFormer: Unleashing the Power of Hierarchy-Aware Features for Lightweight Semantic Segmentation
Jul 11, 2024

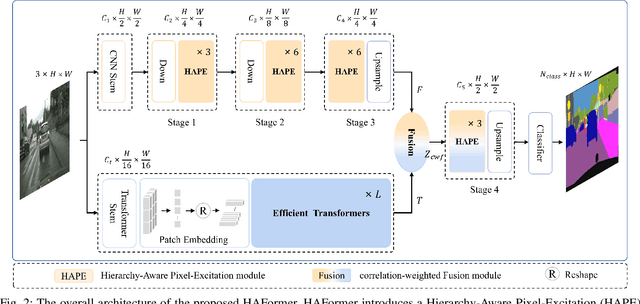
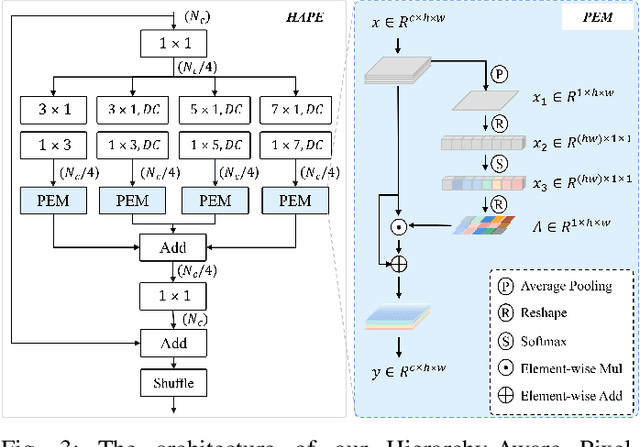
Both Convolutional Neural Networks (CNNs) and Transformers have shown great success in semantic segmentation tasks. Efforts have been made to integrate CNNs with Transformer models to capture both local and global context interactions. However, there is still room for enhancement, particularly when considering constraints on computational resources. In this paper, we introduce HAFormer, a model that combines the hierarchical features extraction ability of CNNs with the global dependency modeling capability of Transformers to tackle lightweight semantic segmentation challenges. Specifically, we design a Hierarchy-Aware Pixel-Excitation (HAPE) module for adaptive multi-scale local feature extraction. During the global perception modeling, we devise an Efficient Transformer (ET) module streamlining the quadratic calculations associated with traditional Transformers. Moreover, a correlation-weighted Fusion (cwF) module selectively merges diverse feature representations, significantly enhancing predictive accuracy. HAFormer achieves high performance with minimal computational overhead and compact model size, achieving 74.2% mIoU on Cityscapes and 71.1% mIoU on CamVid test datasets, with frame rates of 105FPS and 118FPS on a single 2080Ti GPU. The source codes are available at https://github.com/XU-GITHUB-curry/HAFormer.
MFPNet: Multi-scale Feature Propagation Network For Lightweight Semantic Segmentation
Sep 12, 2023



In contrast to the abundant research focusing on large-scale models, the progress in lightweight semantic segmentation appears to be advancing at a comparatively slower pace. However, existing compact methods often suffer from limited feature representation capability due to the shallowness of their networks. In this paper, we propose a novel lightweight segmentation architecture, called Multi-scale Feature Propagation Network (MFPNet), to address the dilemma. Specifically, we design a robust Encoder-Decoder structure featuring symmetrical residual blocks that consist of flexible bottleneck residual modules (BRMs) to explore deep and rich muti-scale semantic context. Furthermore, taking benefit from their capacity to model latent long-range contextual relationships, we leverage Graph Convolutional Networks (GCNs) to facilitate multi-scale feature propagation between the BRM blocks. When evaluated on benchmark datasets, our proposed approach shows superior segmentation results.