 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJointSplat: Probabilistic Joint Flow-Depth Optimization for Sparse-View Gaussian Splatting
Jun 04, 2025Reconstructing 3D scenes from sparse viewpoints is a long-standing challenge with wide applications. Recent advances in feed-forward 3D Gaussian sparse-view reconstruction methods provide an efficient solution for real-time novel view synthesis by leveraging geometric priors learned from large-scale multi-view datasets and computing 3D Gaussian centers via back-projection. Despite offering strong geometric cues, both feed-forward multi-view depth estimation and flow-depth joint estimation face key limitations: the former suffers from mislocation and artifact issues in low-texture or repetitive regions, while the latter is prone to local noise and global inconsistency due to unreliable matches when ground-truth flow supervision is unavailable. To overcome this, we propose JointSplat, a unified framework that leverages the complementarity between optical flow and depth via a novel probabilistic optimization mechanism. Specifically, this pixel-level mechanism scales the information fusion between depth and flow based on the matching probability of optical flow during training. Building upon the above mechanism, we further propose a novel multi-view depth-consistency loss to leverage the reliability of supervision while suppressing misleading gradients in uncertain areas. Evaluated on RealEstate10K and ACID, JointSplat consistently outperforms state-of-the-art (SOTA) methods, demonstrating the effectiveness and robustness of our proposed probabilistic joint flow-depth optimization approach for high-fidelity sparse-view 3D reconstruction.
S2AFormer: Strip Self-Attention for Efficient Vision Transformer
May 28, 2025Vision Transformer (ViT) has made significant advancements in computer vision, thanks to its token mixer's sophisticated ability to capture global dependencies between all tokens. However, the quadratic growth in computational demands as the number of tokens increases limits its practical efficiency. Although recent methods have combined the strengths of convolutions and self-attention to achieve better trade-offs, the expensive pairwise token affinity and complex matrix operations inherent in self-attention remain a bottleneck. To address this challenge, we propose S2AFormer, an efficient Vision Transformer architecture featuring novel Strip Self-Attention (SSA). We design simple yet effective Hybrid Perception Blocks (HPBs) to effectively integrate the local perception capabilities of CNNs with the global context modeling of Transformer's attention mechanisms. A key innovation of SSA lies in its reducing the spatial dimensions of $K$ and $V$ while compressing the channel dimensions of $Q$ and $K$. This design significantly reduces computational overhead while preserving accuracy, striking an optimal balance between efficiency and effectiveness. We evaluate the robustness and efficiency of S2AFormer through extensive experiments on multiple vision benchmarks, including ImageNet-1k for image classification, ADE20k for semantic segmentation, and COCO for object detection and instance segmentation. Results demonstrate that S2AFormer achieves significant accuracy gains with superior efficiency in both GPU and non-GPU environments, making it a strong candidate for efficient vision Transformers.
SCASeg: Strip Cross-Attention for Efficient Semantic Segmentation
Nov 26, 2024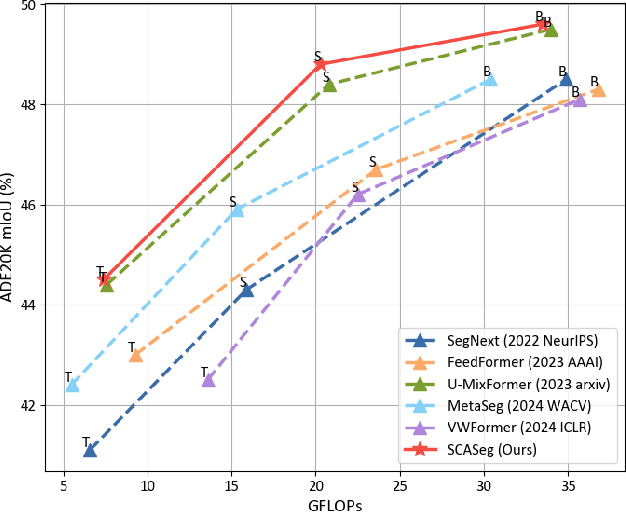

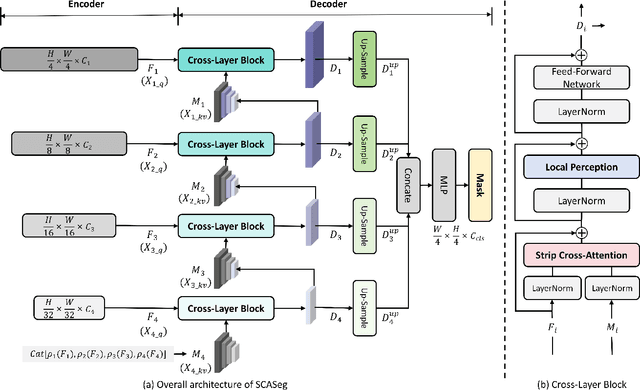

The Vision Transformer (ViT) has achieved notable success in computer vision, with its variants extensively validated across various downstream tasks, including semantic segmentation. However, designed as general-purpose visual encoders, ViT backbones often overlook the specific needs of task decoders, revealing opportunities to design decoders tailored to efficient semantic segmentation. This paper proposes Strip Cross-Attention (SCASeg), an innovative decoder head explicitly designed for semantic segmentation. Instead of relying on the simple conventional skip connections, we employ lateral connections between the encoder and decoder stages, using encoder features as Queries for the cross-attention modules. Additionally, we introduce a Cross-Layer Block that blends hierarchical feature maps from different encoder and decoder stages to create a unified representation for Keys and Values. To further boost computational efficiency, SCASeg compresses queries and keys into strip-like patterns to optimize memory usage and inference speed over the traditional vanilla cross-attention. Moreover, the Cross-Layer Block incorporates the local perceptual strengths of convolution, enabling SCASeg to capture both global and local context dependencies across multiple layers. This approach facilitates effective feature interaction at different scales, improving the overall performance. Experiments show that the adaptable decoder of SCASeg produces competitive performance across different setups, surpassing leading segmentation architectures on all benchmark datasets, including ADE20K, Cityscapes, COCO-Stuff 164k, and Pascal VOC2012, even under varying computational limitations.
Efficient Semantic Segmentation via Lightweight Multiple-Information Interaction Network
Oct 03, 2024Recently, the integration of the local modeling capabilities of Convolutional Neural Networks (CNNs) with the global dependency strengths of Transformers has created a sensation in the semantic segmentation community. However, substantial computational workloads and high hardware memory demands remain major obstacles to their further application in real-time scenarios. In this work, we propose a lightweight multiple-information interaction network for real-time semantic segmentation, called LMIINet, which effectively combines CNNs and Transformers while reducing redundant computations and memory footprint. It features Lightweight Feature Interaction Bottleneck (LFIB) modules comprising efficient convolutions that enhance context integration. Additionally, improvements are made to the Flatten Transformer by enhancing local and global feature interaction to capture detailed semantic information. The incorporation of a combination coefficient learning scheme in both LFIB and Transformer blocks facilitates improved feature interaction. Extensive experiments demonstrate that LMIINet excels in balancing accuracy and efficiency. With only 0.72M parameters and 11.74G FLOPs, LMIINet achieves 72.0% mIoU at 100 FPS on the Cityscapes test set and 69.94% mIoU at 160 FPS on the CamVid test dataset using a single RTX2080Ti GPU.
ReviveDiff: A Universal Diffusion Model for Restoring Images in Adverse Weather Conditions
Sep 27, 2024



Images captured in challenging environments--such as nighttime, foggy, rainy weather, and underwater--often suffer from significant degradation, resulting in a substantial loss of visual quality. Effective restoration of these degraded images is critical for the subsequent vision tasks. While many existing approaches have successfully incorporated specific priors for individual tasks, these tailored solutions limit their applicability to other degradations. In this work, we propose a universal network architecture, dubbed "ReviveDiff", which can address a wide range of degradations and bring images back to life by enhancing and restoring their quality. Our approach is inspired by the observation that, unlike degradation caused by movement or electronic issues, quality degradation under adverse conditions primarily stems from natural media (such as fog, water, and low luminance), which generally preserves the original structures of objects. To restore the quality of such images, we leveraged the latest advancements in diffusion models and developed ReviveDiff to restore image quality from both macro and micro levels across some key factors determining image quality, such as sharpness, distortion, noise level, dynamic range, and color accuracy. We rigorously evaluated ReviveDiff on seven benchmark datasets covering five types of degrading conditions: Rainy, Underwater, Low-light, Smoke, and Nighttime Hazy. Our experimental results demonstrate that ReviveDiff outperforms the state-of-the-art methods both quantitatively and visually.
MacFormer: Semantic Segmentation with Fine Object Boundaries
Aug 11, 2024



Semantic segmentation involves assigning a specific category to each pixel in an image. While Vision Transformer-based models have made significant progress, current semantic segmentation methods often struggle with precise predictions in localized areas like object boundaries. To tackle this challenge, we introduce a new semantic segmentation architecture, ``MacFormer'', which features two key components. Firstly, using learnable agent tokens, a Mutual Agent Cross-Attention (MACA) mechanism effectively facilitates the bidirectional integration of features across encoder and decoder layers. This enables better preservation of low-level features, such as elementary edges, during decoding. Secondly, a Frequency Enhancement Module (FEM) in the decoder leverages high-frequency and low-frequency components to boost features in the frequency domain, benefiting object boundaries with minimal computational complexity increase. MacFormer is demonstrated to be compatible with various network architectures and outperforms existing methods in both accuracy and efficiency on benchmark datasets ADE20K and Cityscapes under different computational constraints.
HAFormer: Unleashing the Power of Hierarchy-Aware Features for Lightweight Semantic Segmentation
Jul 11, 2024

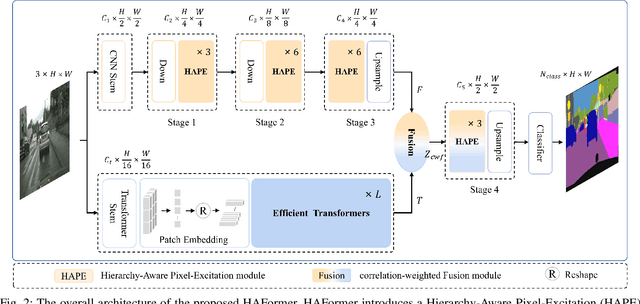
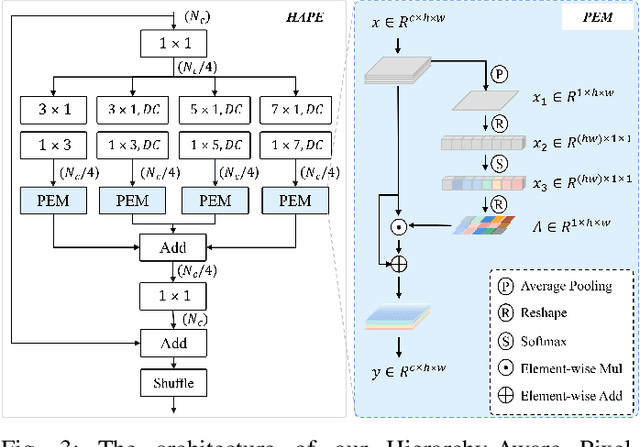
Both Convolutional Neural Networks (CNNs) and Transformers have shown great success in semantic segmentation tasks. Efforts have been made to integrate CNNs with Transformer models to capture both local and global context interactions. However, there is still room for enhancement, particularly when considering constraints on computational resources. In this paper, we introduce HAFormer, a model that combines the hierarchical features extraction ability of CNNs with the global dependency modeling capability of Transformers to tackle lightweight semantic segmentation challenges. Specifically, we design a Hierarchy-Aware Pixel-Excitation (HAPE) module for adaptive multi-scale local feature extraction. During the global perception modeling, we devise an Efficient Transformer (ET) module streamlining the quadratic calculations associated with traditional Transformers. Moreover, a correlation-weighted Fusion (cwF) module selectively merges diverse feature representations, significantly enhancing predictive accuracy. HAFormer achieves high performance with minimal computational overhead and compact model size, achieving 74.2% mIoU on Cityscapes and 71.1% mIoU on CamVid test datasets, with frame rates of 105FPS and 118FPS on a single 2080Ti GPU. The source codes are available at https://github.com/XU-GITHUB-curry/HAFormer.
MFPNet: Multi-scale Feature Propagation Network For Lightweight Semantic Segmentation
Sep 12, 2023



In contrast to the abundant research focusing on large-scale models, the progress in lightweight semantic segmentation appears to be advancing at a comparatively slower pace. However, existing compact methods often suffer from limited feature representation capability due to the shallowness of their networks. In this paper, we propose a novel lightweight segmentation architecture, called Multi-scale Feature Propagation Network (MFPNet), to address the dilemma. Specifically, we design a robust Encoder-Decoder structure featuring symmetrical residual blocks that consist of flexible bottleneck residual modules (BRMs) to explore deep and rich muti-scale semantic context. Furthermore, taking benefit from their capacity to model latent long-range contextual relationships, we leverage Graph Convolutional Networks (GCNs) to facilitate multi-scale feature propagation between the BRM blocks. When evaluated on benchmark datasets, our proposed approach shows superior segmentation results.
Lightweight Real-time Semantic Segmentation Network with Efficient Transformer and CNN
Feb 21, 2023



In the past decade, convolutional neural networks (CNNs) have shown prominence for semantic segmentation. Although CNN models have very impressive performance, the ability to capture global representation is still insufficient, which results in suboptimal results. Recently, Transformer achieved huge success in NLP tasks, demonstrating its advantages in modeling long-range dependency. Recently, Transformer has also attracted tremendous attention from computer vision researchers who reformulate the image processing tasks as a sequence-to-sequence prediction but resulted in deteriorating local feature details. In this work, we propose a lightweight real-time semantic segmentation network called LETNet. LETNet combines a U-shaped CNN with Transformer effectively in a capsule embedding style to compensate for respective deficiencies. Meanwhile, the elaborately designed Lightweight Dilated Bottleneck (LDB) module and Feature Enhancement (FE) module cultivate a positive impact on training from scratch simultaneously. Extensive experiments performed on challenging datasets demonstrate that LETNet achieves superior performances in accuracy and efficiency balance. Specifically, It only contains 0.95M parameters and 13.6G FLOPs but yields 72.8\% mIoU at 120 FPS on the Cityscapes test set and 70.5\% mIoU at 250 FPS on the CamVid test dataset using a single RTX 3090 GPU. The source code will be available at https://github.com/IVIPLab/LETNet.
FBSNet: A Fast Bilateral Symmetrical Network for Real-Time Semantic Segmentation
Sep 02, 2021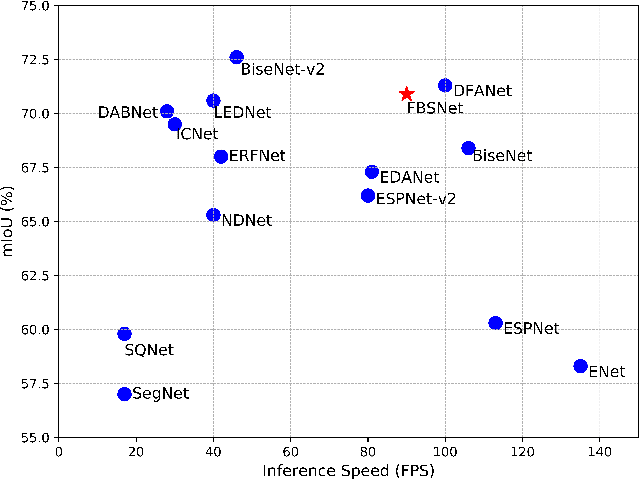
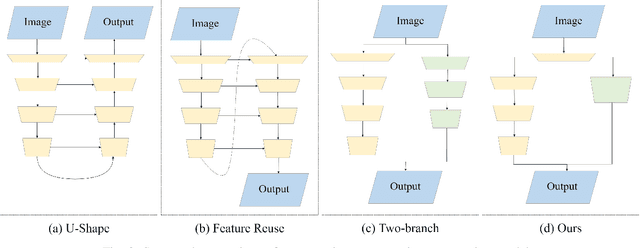
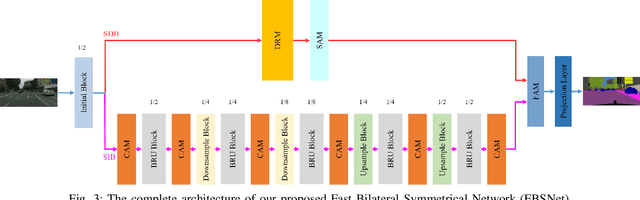
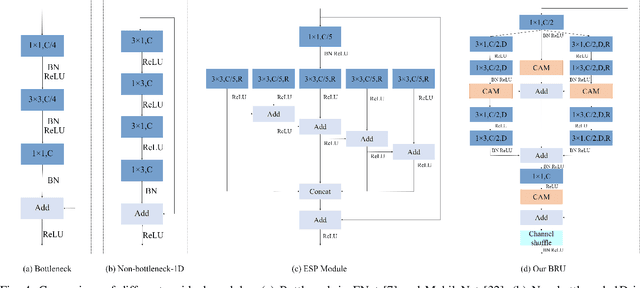
Real-time semantic segmentation, which can be visually understood as the pixel-level classification task on the input image, currently has broad application prospects, especially in the fast-developing fields of autonomous driving and drone navigation. However, the huge burden of calculation together with redundant parameters are still the obstacles to its technological development. In this paper, we propose a Fast Bilateral Symmetrical Network (FBSNet) to alleviate the above challenges. Specifically, FBSNet employs a symmetrical encoder-decoder structure with two branches, semantic information branch, and spatial detail branch. The semantic information branch is the main branch with deep network architecture to acquire the contextual information of the input image and meanwhile acquire sufficient receptive field. While spatial detail branch is a shallow and simple network used to establish local dependencies of each pixel for preserving details, which is essential for restoring the original resolution during the decoding phase. Meanwhile, a feature aggregation module (FAM) is designed to effectively combine the output features of the two branches. The experimental results of Cityscapes and CamVid show that the proposed FBSNet can strike a good balance between accuracy and efficiency. Specifically, it obtains 70.9\% and 68.9\% mIoU along with the inference speed of 90 fps and 120 fps on these two test datasets, respectively, with only 0.62 million parameters on a single RTX 2080Ti GPU.