 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2AFormer: Strip Self-Attention for Efficient Vision Transformer
May 28, 2025Vision Transformer (ViT) has made significant advancements in computer vision, thanks to its token mixer's sophisticated ability to capture global dependencies between all tokens. However, the quadratic growth in computational demands as the number of tokens increases limits its practical efficiency. Although recent methods have combined the strengths of convolutions and self-attention to achieve better trade-offs, the expensive pairwise token affinity and complex matrix operations inherent in self-attention remain a bottleneck. To address this challenge, we propose S2AFormer, an efficient Vision Transformer architecture featuring novel Strip Self-Attention (SSA). We design simple yet effective Hybrid Perception Blocks (HPBs) to effectively integrate the local perception capabilities of CNNs with the global context modeling of Transformer's attention mechanisms. A key innovation of SSA lies in its reducing the spatial dimensions of $K$ and $V$ while compressing the channel dimensions of $Q$ and $K$. This design significantly reduces computational overhead while preserving accuracy, striking an optimal balance between efficiency and effectiveness. We evaluate the robustness and efficiency of S2AFormer through extensive experiments on multiple vision benchmarks, including ImageNet-1k for image classification, ADE20k for semantic segmentation, and COCO for object detection and instance segmentation. Results demonstrate that S2AFormer achieves significant accuracy gains with superior efficiency in both GPU and non-GPU environments, making it a strong candidate for efficient vision Transformers.
Fast Extrinsic Calibration for Multiple Inertial Measurement Units in Visual-Inertial System
Sep 24, 2024



In this paper, we propose a fast extrinsic calibration method for fusing multiple inertial measurement units (MIMU) to improve visual-inertial odometry (VIO) localization accuracy. Currently, data fusion algorithms for MIMU highly depend on the number of inertial sensors. Based on the assumption that extrinsic parameters between inertial sensors are perfectly calibrated, the fusion algorithm provides better localization accuracy with more IMUs, while neglecting the effect of extrinsic calibration error. Our method builds two non-linear least-squares problems to estimate the MIMU relative position and orientation separately, independent of external sensors and inertial noises online estimation. Then we give the general form of the virtual IMU (VIMU) method and propose its propagation on manifold. We perform our method on datasets, our self-made sensor board, and board with different IMUs, validating the superiority of our method over competing methods concerning speed, accuracy, and robustness. In the simulation experiment, we show that only fusing two IMUs with our calibration method to predict motion can rival nine IMUs. Real-world experiments demonstrate better localization accuracy of the VIO integrated with our calibration method and VIMU propagation on manifold.
Unsupervised Monocular Depth Estimation Based on Hierarchical Feature-Guided Diffusion
Jun 14, 2024



Unsupervised monocular depth estimation has received widespread attention because of its capability to train without ground truth. In real-world scenarios, the images may be blurry or noisy due to the influence of weather conditions and inherent limitations of the camera. Therefore, it is particularly important to develop a robust depth estimation model. Benefiting from the training strategies of generative networks, generative-based methods often exhibit enhanced robustness. In light of this, we employ a well-converging diffusion model among generative networks for unsupervised monocular depth estimation. Additionally, we propose a hierarchical feature-guided denoising module. This model significantly enriches the model's capacity for learning and interpreting depth distribution by fully leveraging image features to guide the denoising process. Furthermore, we explore the implicit depth within reprojection and design an implicit depth consistency loss. This loss function serves to enhance the performance of the model and ensure the scale consistency of depth within a video sequence. We conduct experiments on the KITTI, Make3D, and our self-collected SIMIT datasets. The results indicate that our approach stands out among generative-based models, while also showcasing remarkable robustness.
SASO: Joint 3D Semantic-Instance Segmentation via Multi-scale Semantic Association and Salient Point Clustering Optimization
Jun 25, 2020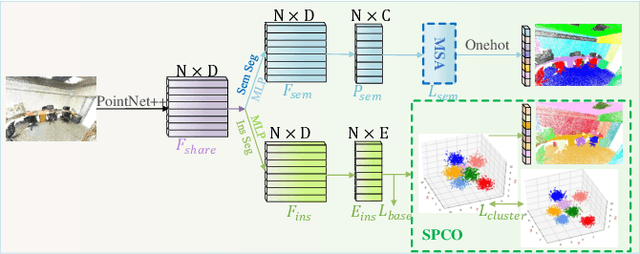
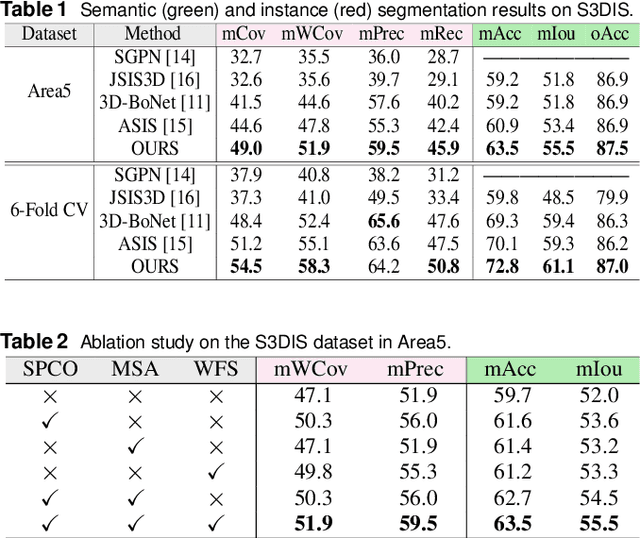
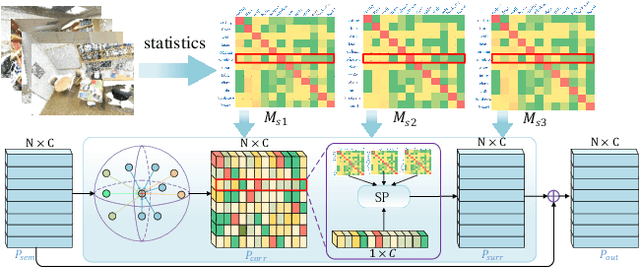

We propose a novel 3D point cloud segmentation framework named SASO, which jointly performs semantic and instance segmentation tasks. For semantic segmentation task, inspired by the inherent correlation among objects in spatial context, we propose a Multi-scale Semantic Association (MSA) module to explore the constructive effects of the semantic context information. For instance segmentation task, different from previous works that utilize clustering only in inference procedure, we propose a Salient Point Clustering Optimization (SPCO) module to introduce a clustering procedure into the training process and impel the network focusing on points that are difficult to be distinguished. In addition, because of the inherent structures of indoor scenes, the imbalance problem of the category distribution is rarely considered but severely limits the performance of 3D scene perception. To address this issue, we introduce an adaptive Water Filling Sampling (WFS) algorithm to balance the category distribution of training data. Extensive experiments demonstrate that our method outperforms the state-of-the-art methods on benchmark datasets in both semantic segmentation and instance segmentation tasks.
3DCFS: Fast and Robust Joint 3D Semantic-Instance Segmentation via Coupled Feature Selection
Mar 01, 2020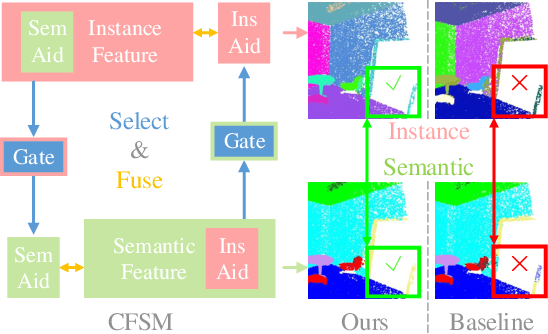
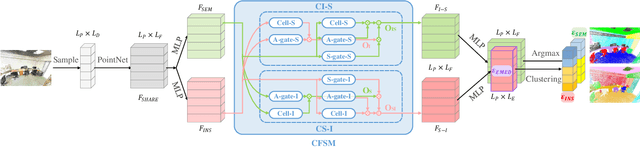
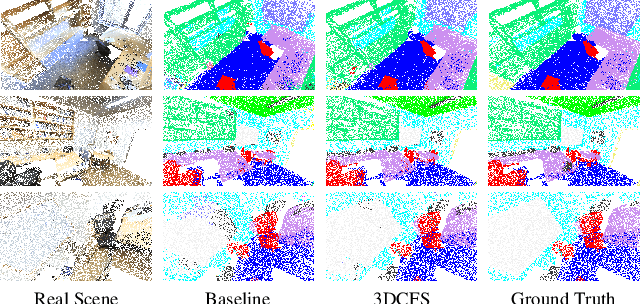
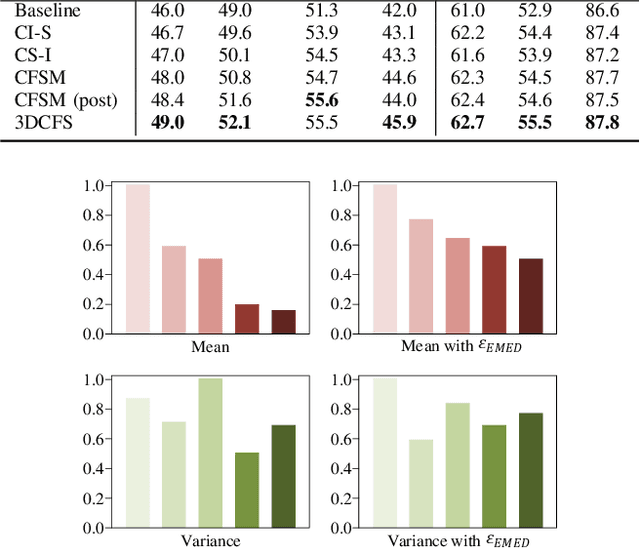
We propose a novel fast and robust 3D point clouds segmentation framework via coupled feature selection, named 3DCFS, that jointly performs semantic and instance segmentation. Inspired by the human scene perception process, we design a novel coupled feature selection module, named CFSM, that adaptively selects and fuses the reciprocal semantic and instance features from two tasks in a coupled manner. To further boost the performance of the instance segmentation task in our 3DCFS, we investigate a loss function that helps the model learn to balance the magnitudes of the output embedding dimensions during training, which makes calculating the Euclidean distance more reliable and enhances the generalizability of the model. Extensive experiments demonstrate that our 3DCFS outperforms state-of-the-art methods on benchmark datasets in terms of accuracy, speed and computational cost.