 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2RC-GCN: A Spatial-Spectral Reliable Contrastive Graph Convolutional Network for Complex Land Cover Classification Using Hyperspectral Images
Apr 01, 2024Spatial correlations between different ground objects are an important feature of mining land cover research. Graph Convolutional Networks (GCNs) can effectively capture such spatial feature representations and have demonstrated promising results in performing hyperspectral imagery (HSI) classification tasks of complex land. However, the existing GCN-based HSI classification methods are prone to interference from redundant information when extracting complex features. To classify complex scenes more effectively, this study proposes a novel spatial-spectral reliable contrastive graph convolutional classification framework named S2RC-GCN. Specifically, we fused the spectral and spatial features extracted by the 1D- and 2D-encoder, and the 2D-encoder includes an attention model to automatically extract important information. We then leveraged the fused high-level features to construct graphs and fed the resulting graphs into the GCNs to determine more effective graph representations. Furthermore, a novel reliable contrastive graph convolution was proposed for reliable contrastive learning to learn and fuse robust features. Finally, to test the performance of the model on complex object classification, we used imagery taken by Gaofen-5 in the Jiang Xia area to construct complex land cover datasets. The test results show that compared with other models, our model achieved the best results and effectively improved the classification performance of complex remote sensing imagery.
Adjustable Molecular Representation for Unified Pre-training Strategy
Dec 28, 2023

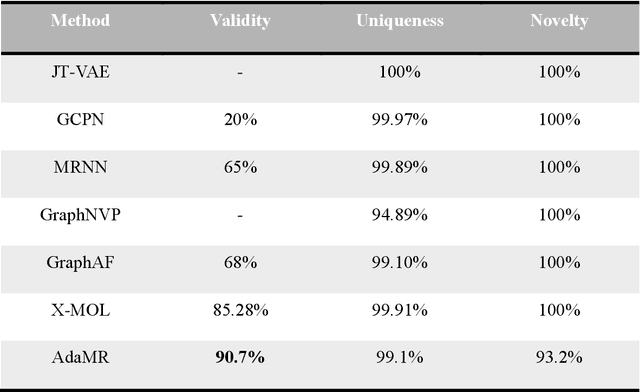

We propose a new large-scale molecular model, named AdaMR, which stands for Adjustable Molecular Representation for Unified Pre-training Strategy. Unlike recent large-scale molecular models that use a single molecular encoding, AdaMR employs a granularity-adjustable molecular encoder, learning molecular representations at both the atomic and substructure levels. For the pre-training process, we designed a task for molecular canonicalization, which involves transforming ltiple generic molecular representations into canonical representations. By adjusting the granularity of molecular encoding, the trained model can improve the effects on multiple downstream tasks, such as model attribute prediction and molecule generation. Substructure-level molecular representation retains information of specific atom groups or arrangements that determine chemical properties and have similar functions, which is beneficial for tasks like property prediction. Meanwhile, atomic-level representation, combined with generative molecular canonicalization pre-training tasks, enhances the validity, novelty, and uniqueness in generative tasks. These features of AdaMR demonstrate its strong performance in numerous downstream tasks. We use different molecular properties prediction tasks on six different datasets on MoleculeNet and two generative tasks on ZINC250K dataset to evaluate our proposed molecular encoding and pre-training methods, and obtain state-of-the-art (SOTA) results on five of these tasks.
Contrastive Multi-view Subspace Clustering of Hyperspectral Images based on Graph Convolutional Networks
Dec 11, 2023



High-dimensional and complex spectral structures make the clustering of hyperspectral images (HSI) a challenging task. Subspace clustering is an effective approach for addressing this problem. However, current subspace clustering algorithms are primarily designed for a single view and do not fully exploit the spatial or textural feature information in HSI. In this study, contrastive multi-view subspace clustering of HSI was proposed based on graph convolutional networks. Pixel neighbor textural and spatial-spectral information were sent to construct two graph convolutional subspaces to learn their affinity matrices. To maximize the interaction between different views, a contrastive learning algorithm was introduced to promote the consistency of positive samples and assist the model in extracting robust features. An attention-based fusion module was used to adaptively integrate these affinity matrices, constructing a more discriminative affinity matrix. The model was evaluated using four popular HSI datasets: Indian Pines, Pavia University, Houston, and Xu Zhou. It achieved overall accuracies of 97.61%, 96.69%, 87.21%, and 97.65%, respectively, and significantly outperformed state-of-the-art clustering methods. In conclusion, the proposed model effectively improves the clustering accuracy of HSI.
TrTr: A Versatile Pre-Trained Large Traffic Model based on Transformer for Capturing Trajectory Diversity in Vehicle Population
Sep 22, 2023Understanding trajectory diversity is a fundamental aspect of addressing practical traffic tasks. However, capturing the diversity of trajectories presents challenges, particularly with traditional machine learning and recurrent neural networks due to the requirement of large-scale parameters. The emerging Transformer technology, renowned for its parallel computation capabilities enabling the utilization of models with hundreds of millions of parameters, offers a promising solution. In this study, we apply the Transformer architecture to traffic tasks, aiming to learn the diversity of trajectories within vehicle populations. We analyze the Transformer's attention mechanism and its adaptability to the goals of traffic tasks, and subsequently, design specific pre-training tasks. To achieve this, we create a data structure tailored to the attention mechanism and introduce a set of noises that correspond to spatio-temporal demands, which are incorporated into the structured data during the pre-training process. The designed pre-training model demonstrates excellent performance in capturing the spatial distribution of the vehicle population, with no instances of vehicle overlap and an RMSE of 0.6059 when compared to the ground truth values. In the context of time series prediction, approximately 95% of the predicted trajectories' speeds closely align with the true speeds, within a deviation of 7.5144m/s. Furthermore, in the stability test, the model exhibits robustness by continuously predicting a time series ten times longer than the input sequence, delivering smooth trajectories and showcasing diverse driving behaviors. The pre-trained model also provides a good basis for downstream fine-tuning tasks. The number of parameters of our model is over 50 million.