 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Stream Global-Local Feature Collaborative Representation Network for Scene Classification of Mining Area
Jul 27, 2025



Scene classification of mining areas provides accurate foundational data for geological environment monitoring and resource development planning. This study fuses multi-source data to construct a multi-modal mine land cover scene classification dataset. A significant challenge in mining area classification lies in the complex spatial layout and multi-scale characteristics. By extracting global and local features, it becomes possible to comprehensively reflect the spatial distribution, thereby enabling a more accurate capture of the holistic characteristics of mining scenes. We propose a dual-branch fusion model utilizing collaborative representation to decompose global features into a set of key semantic vectors. This model comprises three key components:(1) Multi-scale Global Transformer Branch: It leverages adjacent large-scale features to generate global channel attention features for small-scale features, effectively capturing the multi-scale feature relationships. (2) Local Enhancement Collaborative Representation Branch: It refines the attention weights by leveraging local features and reconstructed key semantic sets, ensuring that the local context and detailed characteristics of the mining area are effectively integrated. This enhances the model's sensitivity to fine-grained spatial variations. (3) Dual-Branch Deep Feature Fusion Module: It fuses the complementary features of the two branches to incorporate more scene information. This fusion strengthens the model's ability to distinguish and classify complex mining landscapes. Finally, this study employs multi-loss computation to ensure a balanced integration of the modules. The overall accuracy of this model is 83.63%, which outperforms other comparative models. Additionally, it achieves the best performance across all other evaluation metrics.
Multi-level Graph Subspace Contrastive Learning for Hyperspectral Image Clustering
Apr 08, 2024Hyperspectral image (HSI) clustering is a challenging task due to its high complexity. Despite subspace clustering shows impressive performance for HSI, traditional methods tend to ignore the global-local interaction in HSI data. In this study, we proposed a multi-level graph subspace contrastive learning (MLGSC) for HSI clustering. The model is divided into the following main parts. Graph convolution subspace construction: utilizing spectral and texture feautures to construct two graph convolution views. Local-global graph representation: local graph representations were obtained by step-by-step convolutions and a more representative global graph representation was obtained using an attention-based pooling strategy. Multi-level graph subspace contrastive learning: multi-level contrastive learning was conducted to obtain local-global joint graph representations, to improve the consistency of the positive samples between views, and to obtain more robust graph embeddings. Specifically, graph-level contrastive learning is used to better learn global representations of HSI data. Node-level intra-view and inter-view contrastive learning is designed to learn joint representations of local regions of HSI. The proposed model is evaluated on four popular HSI datasets: Indian Pines, Pavia University, Houston, and Xu Zhou. The overall accuracies are 97.75%, 99.96%, 92.28%, and 95.73%, which significantly outperforms the current state-of-the-art clustering methods.
S2RC-GCN: A Spatial-Spectral Reliable Contrastive Graph Convolutional Network for Complex Land Cover Classification Using Hyperspectral Images
Apr 01, 2024
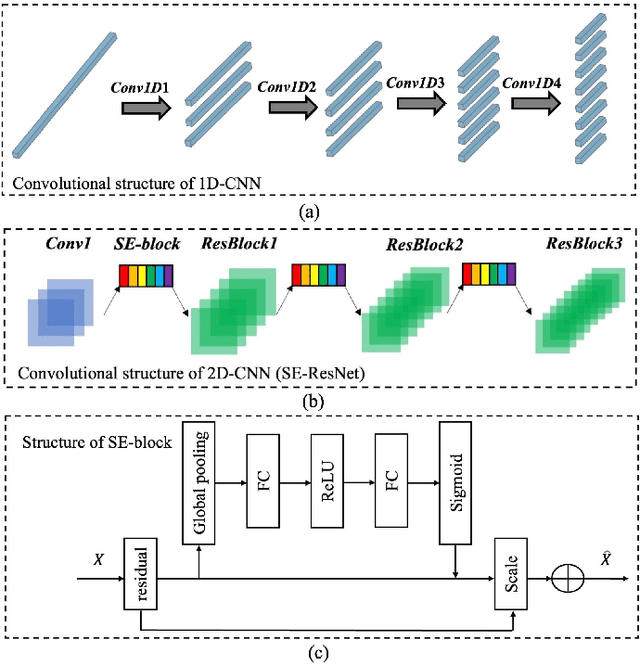


Spatial correlations between different ground objects are an important feature of mining land cover research. Graph Convolutional Networks (GCNs) can effectively capture such spatial feature representations and have demonstrated promising results in performing hyperspectral imagery (HSI) classification tasks of complex land. However, the existing GCN-based HSI classification methods are prone to interference from redundant information when extracting complex features. To classify complex scenes more effectively, this study proposes a novel spatial-spectral reliable contrastive graph convolutional classification framework named S2RC-GCN. Specifically, we fused the spectral and spatial features extracted by the 1D- and 2D-encoder, and the 2D-encoder includes an attention model to automatically extract important information. We then leveraged the fused high-level features to construct graphs and fed the resulting graphs into the GCNs to determine more effective graph representations. Furthermore, a novel reliable contrastive graph convolution was proposed for reliable contrastive learning to learn and fuse robust features. Finally, to test the performance of the model on complex object classification, we used imagery taken by Gaofen-5 in the Jiang Xia area to construct complex land cover datasets. The test results show that compared with other models, our model achieved the best results and effectively improved the classification performance of complex remote sensing imagery.
Multiview Subspace Clustering of Hyperspectral Images based on Graph Convolutional Networks
Mar 03, 2024High-dimensional and complex spectral structures make clustering of hy-perspectral images (HSI) a challenging task. Subspace clustering has been shown to be an effective approach for addressing this problem. However, current subspace clustering algorithms are mainly designed for a single view and do not fully exploit spatial or texture feature information in HSI. This study proposed a multiview subspace clustering of HSI based on graph convolutional networks. (1) This paper uses the powerful classification ability of graph convolutional network and the learning ability of topologi-cal relationships between nodes to analyze and express the spatial relation-ship of HSI. (2) Pixel texture and pixel neighbor spatial-spectral infor-mation were sent to construct two graph convolutional subspaces. (3) An attention-based fusion module was used to adaptively construct a more discriminative feature map. The model was evaluated on three popular HSI datasets, including Indian Pines, Pavia University, and Houston. It achieved overall accuracies of 92.38%, 93.43%, and 83.82%, respectively and significantly outperformed the state-of-the-art clustering methods. In conclusion, the proposed model can effectively improve the clustering ac-curacy of HSI.
Pixel-Superpixel Contrastive Learning and Pseudo-Label Correction for Hyperspectral Image Clustering
Dec 15, 2023



Hyperspectral image (HSI) clustering is gaining considerable attention owing to recent methods that overcome the inefficiency and misleading results from the absence of supervised information. Contrastive learning methods excel at existing pixel level and super pixel level HSI clustering tasks. The pixel-level contrastive learning method can effectively improve the ability of the model to capture fine features of HSI but requires a large time overhead. The super pixel-level contrastive learning method utilizes the homogeneity of HSI and reduces computing resources; however, it yields rough classification results. To exploit the strengths of both methods, we present a pixel super pixel contrastive learning and pseudo-label correction (PSCPC) method for the HSI clustering. PSCPC can reasonably capture domain-specific and fine-grained features through super pixels and the comparative learning of a small number of pixels within the super pixels. To improve the clustering performance of super pixels, this paper proposes a pseudo-label correction module that aligns the clustering pseudo-labels of pixels and super-pixels. In addition, pixel-level clustering results are used to supervise super pixel-level clustering, improving the generalization ability of the model. Extensive experiments demonstrate the effectiveness and efficiency of PSCPC.
Contrastive Multi-view Subspace Clustering of Hyperspectral Images based on Graph Convolutional Networks
Dec 11, 2023



High-dimensional and complex spectral structures make the clustering of hyperspectral images (HSI) a challenging task. Subspace clustering is an effective approach for addressing this problem. However, current subspace clustering algorithms are primarily designed for a single view and do not fully exploit the spatial or textural feature information in HSI. In this study, contrastive multi-view subspace clustering of HSI was proposed based on graph convolutional networks. Pixel neighbor textural and spatial-spectral information were sent to construct two graph convolutional subspaces to learn their affinity matrices. To maximize the interaction between different views, a contrastive learning algorithm was introduced to promote the consistency of positive samples and assist the model in extracting robust features. An attention-based fusion module was used to adaptively integrate these affinity matrices, constructing a more discriminative affinity matrix. The model was evaluated using four popular HSI datasets: Indian Pines, Pavia University, Houston, and Xu Zhou. It achieved overall accuracies of 97.61%, 96.69%, 87.21%, and 97.65%, respectively, and significantly outperformed state-of-the-art clustering methods. In conclusion, the proposed model effectively improves the clustering accuracy of HSI.
MS-Former: Memory-Supported Transformer for Weakly Supervised Change Detection with Patch-Level Annotations
Nov 16, 2023



Fully supervised change detection methods have achieved significant advancements in performance, yet they depend severely on acquiring costly pixel-level labels. Considering that the patch-level annotations also contain abundant information corresponding to both changed and unchanged objects in bi-temporal images, an intuitive solution is to segment the changes with patch-level annotations. How to capture the semantic variations associated with the changed and unchanged regions from the patch-level annotations to obtain promising change results is the critical challenge for the weakly supervised change detection task. In this paper, we propose a memory-supported transformer (MS-Former), a novel framework consisting of a bi-directional attention block (BAB) and a patch-level supervision scheme (PSS) tailored for weakly supervised change detection with patch-level annotations. More specifically, the BAM captures contexts associated with the changed and unchanged regions from the temporal difference features to construct informative prototypes stored in the memory bank. On the other hand, the BAM extracts useful information from the prototypes as supplementary contexts to enhance the temporal difference features, thereby better distinguishing changed and unchanged regions. After that, the PSS guides the network learning valuable knowledge from the patch-level annotations, thus further elevating the performance. Experimental results on three benchmark datasets demonstrate the effectiveness of our proposed method in the change detection task. The demo code for our work will be publicly available at \url{https://github.com/guanyuezhen/MS-Former}.
Towards Accurate and Reliable Change Detection of Remote Sensing Images via Knowledge Review and Online Uncertainty Estimation
May 31, 2023



Change detection (CD) is an essential task for various real-world applications, such as urban management and disaster assessment. However, previous methods primarily focus on improving the accuracy of CD, while neglecting the reliability of detection results. In this paper, we propose a novel change detection network, called AR-CDNet, which is able to provide accurate change maps and generate pixel-wise uncertainty. Specifically, an online uncertainty estimation branch is constructed to model the pixel-wise uncertainty, which is supervised by the difference between predicted change maps and corresponding ground truth during the training process. Furthermore, we introduce a knowledge review strategy to distill temporal change knowledge from low-level features to high-level ones, thereby enhancing the discriminability of temporal difference features. Finally, we aggregate the uncertainty-aware features extracted from the online uncertainty estimation branch with multi-level temporal difference features to improve the accuracy of CD. Once trained, our AR-CDNet can provide accurate change maps and evaluate pixel-wise uncertainty without ground truth. Experimental results on two benchmark datasets demonstrate the superior performance of AR-CDNet in the CD task. The demo code for our work will be publicly available at \url{https://github.com/guanyuezhen/AR-CDNet}.