 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdjustable Molecular Representation for Unified Pre-training Strategy
Paper and Code
Dec 28, 2023

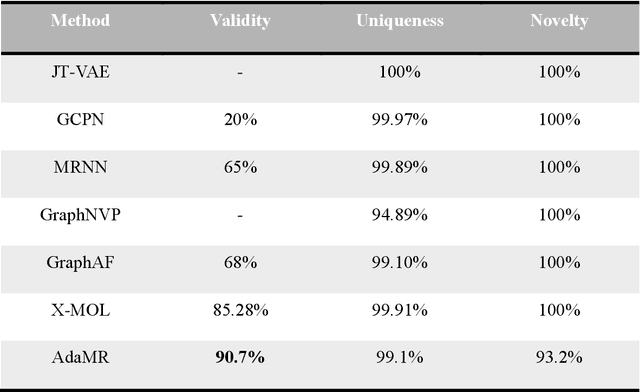

We propose a new large-scale molecular model, named AdaMR, which stands for Adjustable Molecular Representation for Unified Pre-training Strategy. Unlike recent large-scale molecular models that use a single molecular encoding, AdaMR employs a granularity-adjustable molecular encoder, learning molecular representations at both the atomic and substructure levels. For the pre-training process, we designed a task for molecular canonicalization, which involves transforming ltiple generic molecular representations into canonical representations. By adjusting the granularity of molecular encoding, the trained model can improve the effects on multiple downstream tasks, such as model attribute prediction and molecule generation. Substructure-level molecular representation retains information of specific atom groups or arrangements that determine chemical properties and have similar functions, which is beneficial for tasks like property prediction. Meanwhile, atomic-level representation, combined with generative molecular canonicalization pre-training tasks, enhances the validity, novelty, and uniqueness in generative tasks. These features of AdaMR demonstrate its strong performance in numerous downstream tasks. We use different molecular properties prediction tasks on six different datasets on MoleculeNet and two generative tasks on ZINC250K dataset to evaluate our proposed molecular encoding and pre-training methods, and obtain state-of-the-art (SOTA) results on five of these tasks.