 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual-Advantage On-Policy Distillation for Vision-Language Models
May 21, 2026On-policy knowledge distillation has proven effective for language models, yet its application to vision-language models (VLMs) remains underexplored. We observe that standard on-policy distillation can improve a student's output quality while failing to strengthen its reliance on visual input: on vision-critical tokens, the student's predictions remain largely unchanged whether or not fine-grained visual detail is present, even though the teacher's predictions depend heavily on it.To make this difference observable, we introduce visual advantage (VA), the token-level log-probability difference when the teacher scores a student-generated rollout with versus without access to fine-grained visual detail. VA is concentrated in a small minority of tokens, and these high-VA tokens are the ones that actually carry the visual supervision signal. This motivates a distillation objective that treats them differently from language scaffolding, so their contribution is not diluted by the abundant surrounding language tokens.We propose Visual-Advantage On-Policy Distillation (VA-OPD), which uses VA at two granularities: rollout-level reweighting by trajectory-averaged VA, and token-level KL averaged within high-VA and low-VA groups separately. We train on two math datasets (Geometry3K and ViRL39K) and evaluate on eight benchmarks covering both mathematical reasoning and visual understanding, across three teacher sizes (4B, 8B, and 32B) on the Qwen3-VL family. VA-OPD improves over standard on-policy distillation on every benchmark, with the gain growing monotonically along both the teacher-size and data-scale axes, suggesting that these factors compound consistently.
Cycle-resolved Cephalopod-Inspired Pulsed-Jet Robot With High-Volume Expulsion and Drag-Reduced Gliding
May 07, 2026Cephalopod pulsed-jet locomotion is not a single isolated expulsion event, but a coordinated cycle involving jet expulsion, passive gliding, and mantle refilling. Inspired by this cycle-resolved biological strategy, this paper presents a cephalopod-inspired pulsed-jet robot with a rigid-soft hybrid origami mantle that enables large, actively driven, and geometry-guided body deformation. The proposed mantle integrates rigid folding panels with a compliant silicone framework, allowing a 75% effective cavity-volume reduction during expulsion and reducing the projected cross-sectional drag area by approximately 75.7% in the contracted gliding configuration. Using this platform, we formulate a cycle-resolved framework to separately investigate how expelled volume, glide duration, and refill pathway influence whole-cycle locomotion performance. Experiments show that the robot reaches a peak speed of approximately 0.5 m/s (3.8 BL/s) and an average speed exceeding 0.2 m/s (1.5 BL/s) within the first jetting cycle. The results further demonstrate the roles of high expelled-volume-ratio contraction in speed generation, reduced-drag-area gliding under different glide durations, and mantle-aperture-inspired passive inlet valves in assisting refill. This work provides both a robotic implementation of actively deformable cephalopod-like jet propulsion and a unified experimental platform for studying expulsion-gliding-refilling dynamics in pulsed-jet locomotion.
Unified Structural-Hydrodynamic Modeling of Underwater Underactuated Mechanisms and Soft Robots
Mar 09, 2026Underwater robots are widely deployed for ocean exploration and manipulation. Underactuated mechanisms are particularly advantageous in aquatic environments, as reducing actuator count lowers the risk of motor leakage while introducing inherent mechanical compliance. However, accurate modeling of underwater underactuated and soft robotic systems remains challenging because it requires identifying a high-dimensional set of internal structural and external hydrodynamic parameters. In this work, we propose a trajectory-driven global optimization framework for unified structural-hydrodynamic modeling of underwater multibody systems. Inspired by the Covariance Matrix Adaptation Evolution Strategy (CMA-ES), the proposed approach simultaneously identifies coupled internal elastic, damping, and distributed hydrodynamic parameters through trajectory-level matching between simulation and experimental motion. This enables high-fidelity reproduction of both underactuated mechanisms and compliant soft robotic systems in underwater environments. We first validate the framework on a link-by-link underactuated multibody mechanism, demonstrating accurate identification of distributed hydrodynamic coefficients, with a normalized end effector position error below 5% across multiple trajectories, varying initial conditions, and both active-passive and fully passive configurations. The identified modeling strategy is then transferred to a single octopus-inspired soft arm, showing strong real-to-sim consistency without manual retuning. Finally, eight identified arms are assembled into a swimming octopus robot, where the unified parameter set enables realistic whole body behavior without additional parameter calibration. These results demonstrate the scalability and transferability of the proposed structural-hydrodynamic modeling framework across underwater underactuated and soft robotic systems.
MIRROR: Manifold Ideal Reference ReconstructOR for Generalizable AI-Generated Image Detection
Feb 02, 2026High-fidelity generative models have narrowed the perceptual gap between synthetic and real images, posing serious threats to media security. Most existing AI-generated image (AIGI) detectors rely on artifact-based classification and struggle to generalize to evolving generative traces. In contrast, human judgment relies on stable real-world regularities, with deviations from the human cognitive manifold serving as a more generalizable signal of forgery. Motivated by this insight, we reformulate AIGI detection as a Reference-Comparison problem that verifies consistency with the real-image manifold rather than fitting specific forgery cues. We propose MIRROR (Manifold Ideal Reference ReconstructOR), a framework that explicitly encodes reality priors using a learnable discrete memory bank. MIRROR projects an input into a manifold-consistent ideal reference via sparse linear combination, and uses the resulting residuals as robust detection signals. To evaluate whether detectors reach the "superhuman crossover" required to replace human experts, we introduce the Human-AIGI benchmark, featuring a psychophysically curated human-imperceptible subset. Across 14 benchmarks, MIRROR consistently outperforms prior methods, achieving gains of 2.1% on six standard benchmarks and 8.1% on seven in-the-wild benchmarks. On Human-AIGI, MIRROR reaches 89.6% accuracy across 27 generators, surpassing both lay users and visual experts, and further approaching the human perceptual limit as pretrained backbones scale. The code is publicly available at: https://github.com/349793927/MIRROR
SecureAgentBench: Benchmarking Secure Code Generation under Realistic Vulnerability Scenarios
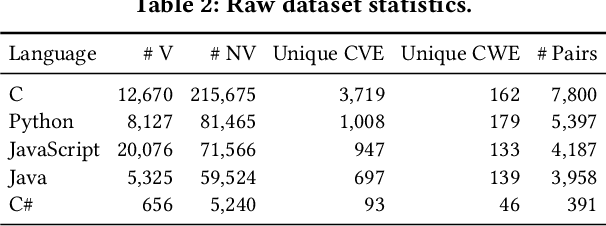
Sep 26, 2025Large language model (LLM) powered code agents are rapidly transforming software engineering by automating tasks such as testing, debugging, and repairing, yet the security risks of their generated code have become a critical concern. Existing benchmarks have offered valuable insights but remain insufficient: they often overlook the genuine context in which vulnerabilities were introduced or adopt narrow evaluation protocols that fail to capture either functional correctness or newly introduced vulnerabilities. We therefore introduce SecureAgentBench, a benchmark of 105 coding tasks designed to rigorously evaluate code agents' capabilities in secure code generation. Each task includes (i) realistic task settings that require multi-file edits in large repositories, (ii) aligned contexts based on real-world open-source vulnerabilities with precisely identified introduction points, and (iii) comprehensive evaluation that combines functionality testing, vulnerability checking through proof-of-concept exploits, and detection of newly introduced vulnerabilities using static analysis. We evaluate three representative agents (SWE-agent, OpenHands, and Aider) with three state-of-the-art LLMs (Claude 3.7 Sonnet, GPT-4.1, and DeepSeek-V3.1). Results show that (i) current agents struggle to produce secure code, as even the best-performing one, SWE-agent supported by DeepSeek-V3.1, achieves merely 15.2% correct-and-secure solutions, (ii) some agents produce functionally correct code but still introduce vulnerabilities, including new ones not previously recorded, and (iii) adding explicit security instructions for agents does not significantly improve secure coding, underscoring the need for further research. These findings establish SecureAgentBench as a rigorous benchmark for secure code generation and a step toward more reliable software development with LLMs.
R2Vul: Learning to Reason about Software Vulnerabilities with Reinforcement Learning and Structured Reasoning Distillation
Apr 07, 2025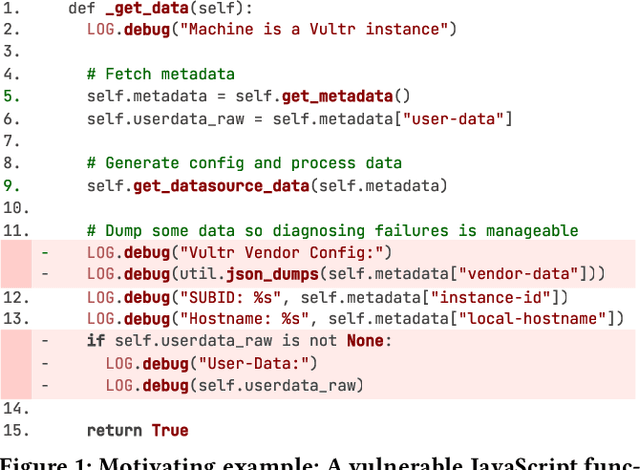


Large language models (LLMs) have shown promising performance in software vulnerability detection (SVD), yet their reasoning capabilities remain unreliable. Existing approaches relying on chain-of-thought (CoT) struggle to provide relevant and actionable security assessments. Additionally, effective SVD requires not only generating coherent reasoning but also differentiating between well-founded and misleading yet plausible security assessments, an aspect overlooked in prior work. To this end, we introduce R2Vul, a novel approach that distills structured reasoning into small LLMs using reinforcement learning from AI feedback (RLAIF). Through RLAIF, R2Vul enables LLMs to produce structured, security-aware reasoning that is actionable and reliable while explicitly learning to distinguish valid assessments from misleading ones. We evaluate R2Vul across five languages against SAST tools, CoT, instruction tuning, and classification-based baselines. Our results show that R2Vul with structured reasoning distillation enables a 1.5B student LLM to rival larger models while improving generalization to out-of-distribution vulnerabilities. Beyond model improvements, we contribute a large-scale, multilingual preference dataset featuring structured reasoning to support future research in SVD.
SAFEERASER: Enhancing Safety in Multimodal Large Language Models through Multimodal Machine Unlearning
Feb 18, 2025



As Multimodal Large Language Models (MLLMs) develop, their potential security issues have become increasingly prominent. Machine Unlearning (MU), as an effective strategy for forgetting specific knowledge in training data, has been widely used in privacy protection. However, MU for safety in MLLM has yet to be fully explored. To address this issue, we propose SAFEERASER, a safety unlearning benchmark for MLLMs, consisting of 3,000 images and 28.8K VQA pairs. We comprehensively evaluate unlearning methods from two perspectives: forget quality and model utility. Our findings show that existing MU methods struggle to maintain model performance while implementing the forget operation and often suffer from over-forgetting. Hence, we introduce Prompt Decouple (PD) Loss to alleviate over-forgetting through decouple prompt during unlearning process. To quantitatively measure over-forgetting mitigated by PD Loss, we propose a new metric called Safe Answer Refusal Rate (SARR). Experimental results demonstrate that combining PD Loss with existing unlearning methods can effectively prevent over-forgetting and achieve a decrease of 79.5% in the SARR metric of LLaVA-7B and LLaVA-13B, while maintaining forget quality and model utility. Our code and dataset will be released upon acceptance. Warning: This paper contains examples of harmful language and images, and reader discretion is recommended.
Devils in Middle Layers of Large Vision-Language Models: Interpreting, Detecting and Mitigating Object Hallucinations via Attention Lens
Nov 23, 2024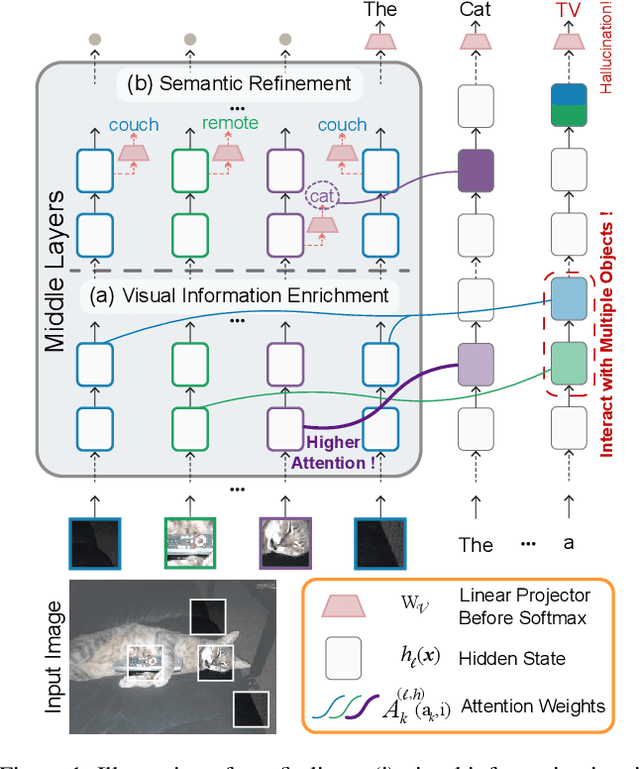
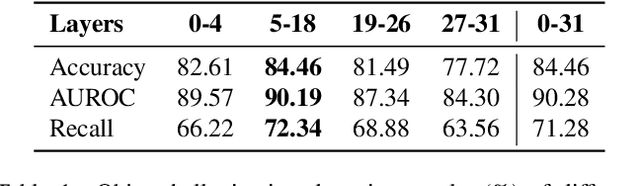
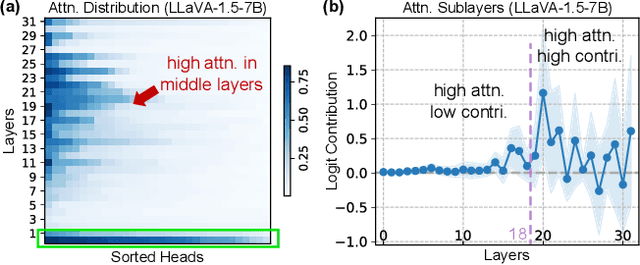
Hallucinations in Large Vision-Language Models (LVLMs) significantly undermine their reliability, motivating researchers to explore the causes of hallucination. However, most studies primarily focus on the language aspect rather than the visual. In this paper, we address how LVLMs process visual information and whether this process causes hallucination. Firstly, we use the attention lens to identify the stages at which LVLMs handle visual data, discovering that the middle layers are crucial. Moreover, we find that these layers can be further divided into two stages: "visual information enrichment" and "semantic refinement" which respectively propagate visual data to object tokens and interpret it through text. By analyzing attention patterns during the visual information enrichment stage, we find that real tokens consistently receive higher attention weights than hallucinated ones, serving as a strong indicator of hallucination. Further examination of multi-head attention maps reveals that hallucination tokens often result from heads interacting with inconsistent objects. Based on these insights, we propose a simple inference-time method that adjusts visual attention by integrating information across various heads. Extensive experiments demonstrate that this approach effectively mitigates hallucinations in mainstream LVLMs without additional training costs.
Look Twice Before You Answer: Memory-Space Visual Retracing for Hallucination Mitigation in Multimodal Large Language Models
Oct 04, 2024
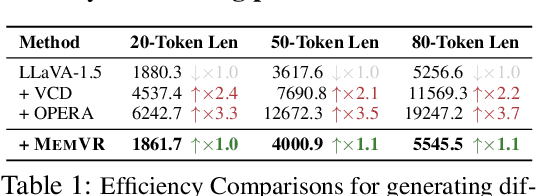
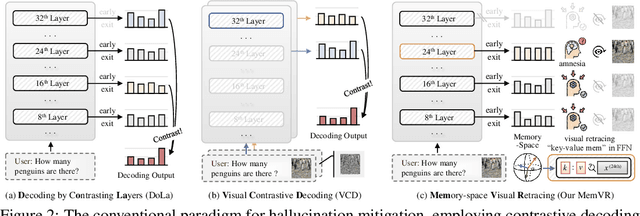
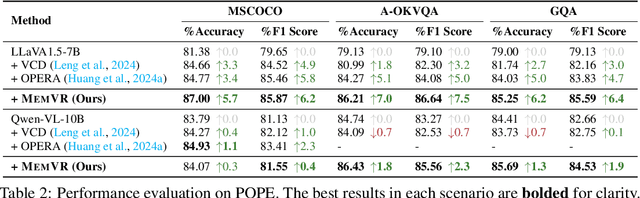
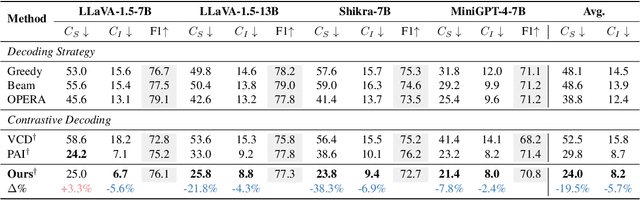
Despite their impressive capabilities, Multimodal Large Language Models (MLLMs) are susceptible to hallucinations, especially assertively fabricating content not present in the visual inputs. To address the aforementioned challenge, we follow a common cognitive process - when one's initial memory of critical on-sight details fades, it is intuitive to look at them a second time to seek a factual and accurate answer. Therefore, we introduce Memory-space Visual Retracing (MemVR), a novel hallucination mitigation paradigm that without the need for external knowledge retrieval or additional fine-tuning. In particular, we treat visual prompts as supplementary evidence to be reinjected into MLLMs via Feed Forward Network (FFN) as key-value memory, when the model is uncertain or even amnesic about question-relevant visual memories. Comprehensive experimental evaluations demonstrate that MemVR significantly mitigates hallucination issues across various MLLMs and excels in general benchmarks without incurring added time overhead, thus emphasizing its potential for widespread applicability.
Reefknot: A Comprehensive Benchmark for Relation Hallucination Evaluation, Analysis and Mitigation in Multimodal Large Language Models
Aug 18, 2024



Hallucination issues persistently plagued current multimodal large language models (MLLMs). While existing research primarily focuses on object-level or attribute-level hallucinations, sidelining the more sophisticated relation hallucinations that necessitate advanced reasoning abilities from MLLMs. Besides, recent benchmarks regarding relation hallucinations lack in-depth evaluation and effective mitigation. Moreover, their datasets are typically derived from a systematic annotation process, which could introduce inherent biases due to the predefined process. To handle the aforementioned challenges, we introduce Reefknot, a comprehensive benchmark specifically targeting relation hallucinations, consisting of over 20,000 samples derived from real-world scenarios. Specifically, we first provide a systematic definition of relation hallucinations, integrating perspectives from perceptive and cognitive domains. Furthermore, we construct the relation-based corpus utilizing the representative scene graph dataset Visual Genome (VG), from which semantic triplets follow real-world distributions. Our comparative evaluation across three distinct tasks revealed a substantial shortcoming in the capabilities of current MLLMs to mitigate relation hallucinations. Finally, we advance a novel confidence-based mitigation strategy tailored to tackle the relation hallucinations problem. Across three datasets, including Reefknot, we observed an average reduction of 9.75% in the hallucination rate. We believe our paper sheds valuable insights into achieving trustworthy multimodal intelligence. Our dataset and code will be released upon paper acceptance.