 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevils in Middle Layers of Large Vision-Language Models: Interpreting, Detecting and Mitigating Object Hallucinations via Attention Lens
Nov 23, 2024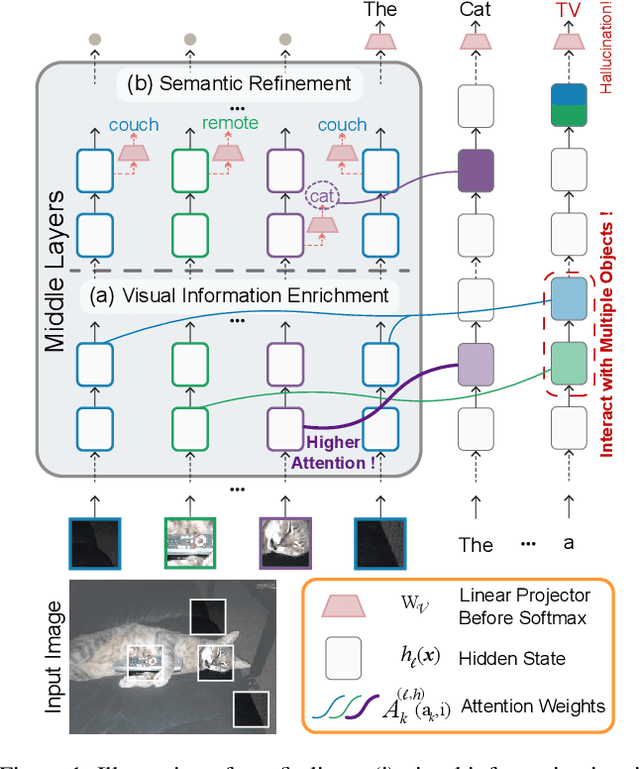
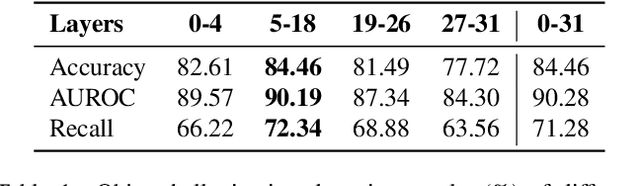
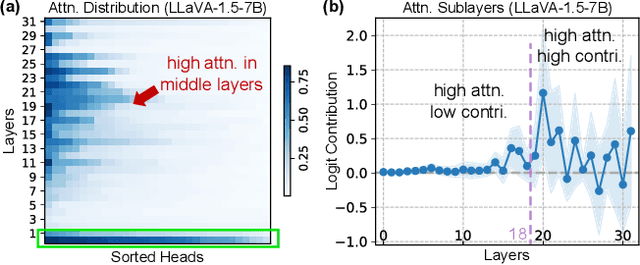
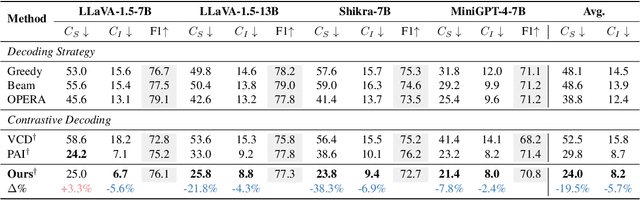
Hallucinations in Large Vision-Language Models (LVLMs) significantly undermine their reliability, motivating researchers to explore the causes of hallucination. However, most studies primarily focus on the language aspect rather than the visual. In this paper, we address how LVLMs process visual information and whether this process causes hallucination. Firstly, we use the attention lens to identify the stages at which LVLMs handle visual data, discovering that the middle layers are crucial. Moreover, we find that these layers can be further divided into two stages: "visual information enrichment" and "semantic refinement" which respectively propagate visual data to object tokens and interpret it through text. By analyzing attention patterns during the visual information enrichment stage, we find that real tokens consistently receive higher attention weights than hallucinated ones, serving as a strong indicator of hallucination. Further examination of multi-head attention maps reveals that hallucination tokens often result from heads interacting with inconsistent objects. Based on these insights, we propose a simple inference-time method that adjusts visual attention by integrating information across various heads. Extensive experiments demonstrate that this approach effectively mitigates hallucinations in mainstream LVLMs without additional training costs.
Leveraging GPT-2 for Classifying Spam Reviews with Limited Labeled Data via Adversarial Training
Dec 24, 2020
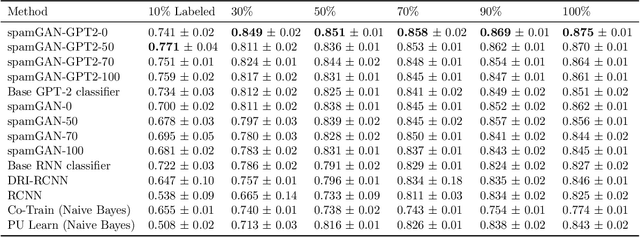
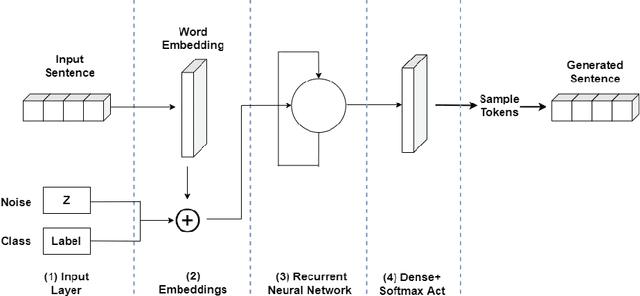
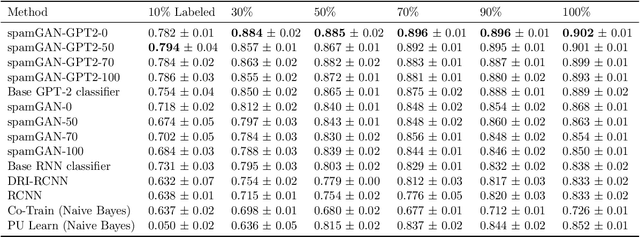
Online reviews are a vital source of information when purchasing a service or a product. Opinion spammers manipulate these reviews, deliberately altering the overall perception of the service. Though there exists a corpus of online reviews, only a few have been labeled as spam or non-spam, making it difficult to train spam detection models. We propose an adversarial training mechanism leveraging the capabilities of Generative Pre-Training 2 (GPT-2) for classifying opinion spam with limited labeled data and a large set of unlabeled data. Experiments on TripAdvisor and YelpZip datasets show that the proposed model outperforms state-of-the-art techniques by at least 7% in terms of accuracy when labeled data is limited. The proposed model can also generate synthetic spam/non-spam reviews with reasonable perplexity, thereby, providing additional labeled data during training.