 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Diminishing Returns of Early-Exit Decoding in Modern LLMs
Mar 24, 2026In Large Language Model (LLM) inference, early-exit refers to stopping computation at an intermediate layer once the prediction is sufficiently confident, thereby reducing latency and cost. However, recent LLMs adopt improved pretraining recipes and architectures that reduce layer redundancy, potentially limiting early-exit opportunities. We re-evaluate layer-wise early-exit in modern LLMs and analyze how intermediate representations evolve during training. We introduce a metric to quantify a model's intrinsic suitability for early-exit and propose a benchmark for researchers to explore the potential early-exit benefits on different models and workloads. Our results show a diminishing trend in early-exit effectiveness across newer model generations. We further find that dense transformers generally offer greater early-exit potential than Mixture-of-Experts and State Space Models. In addition, larger models, particularly those with more than 20 billion parameters, and base pretrained models without specialized tuning tend to exhibit higher early-exit potential.
RLHFless: Serverless Computing for Efficient RLHF
Feb 26, 2026Reinforcement Learning from Human Feedback (RLHF) has been widely applied to Large Language Model (LLM) post-training to align model outputs with human preferences. Recent models, such as DeepSeek-R1, have also shown RLHF's potential to improve LLM reasoning on complex tasks. In RL, inference and training co-exist, creating dynamic resource demands throughout the workflow. Compared to traditional RL, RLHF further challenges training efficiency due to expanding model sizes and resource consumption. Several RLHF frameworks aim to balance flexible abstraction and efficient execution. However, they rely on serverful infrastructures, which struggle with fine-grained resource variability. As a result, during synchronous RLHF training, idle time between or within RL components often causes overhead and resource wastage. To address these issues, we present RLHFless, the first scalable training framework for synchronous RLHF, built on serverless computing environments. RLHFless adapts to dynamic resource demands throughout the RLHF pipeline, pre-computes shared prefixes to avoid repeated computation, and uses a cost-aware actor scaling strategy that accounts for response length variation to find sweet spots with lower cost and higher speed. In addition, RLHFless assigns workloads efficiently to reduce intra-function imbalance and idle time. Experiments on both physical testbeds and a large-scale simulated cluster show that RLHFless achieves up to 1.35x speedup and 44.8% cost reduction compared to the state-of-the-art baseline.
ServerlessLoRA: Minimizing Latency and Cost in Serverless Inference for LoRA-Based LLMs
May 20, 2025Serverless computing has grown rapidly for serving Large Language Model (LLM) inference due to its pay-as-you-go pricing, fine-grained GPU usage, and rapid scaling. However, our analysis reveals that current serverless can effectively serve general LLM but fail with Low-Rank Adaptation (LoRA) inference due to three key limitations: 1) massive parameter redundancy among functions where 99% of weights are unnecessarily duplicated, 2) costly artifact loading latency beyond LLM loading, and 3) magnified resource contention when serving multiple LoRA LLMs. These inefficiencies lead to massive GPU wastage, increased Time-To-First-Token (TTFT), and high monetary costs. We propose ServerlessLoRA, a novel serverless inference system designed for faster and cheaper LoRA LLM serving. ServerlessLoRA enables secure backbone LLM sharing across isolated LoRA functions to reduce redundancy. We design a pre-loading method that pre-loads comprehensive LoRA artifacts to minimize cold-start latency. Furthermore, ServerlessLoRA employs contention aware batching and offloading to mitigate GPU resource conflicts during bursty workloads. Experiment on industrial workloads demonstrates that ServerlessLoRA reduces TTFT by up to 86% and cuts monetary costs by up to 89% compared to state-of-the-art LLM inference solutions.
fMoE: Fine-Grained Expert Offloading for Large Mixture-of-Experts Serving
Feb 07, 2025



Large Language Models (LLMs) have gained immense success in revolutionizing various applications, including content generation, search and recommendation, and AI-assisted operation. To reduce high training costs, Mixture-of-Experts (MoE) architecture has become a popular backbone for modern LLMs. However, despite the benefits, serving MoE-based LLMs experience severe memory inefficiency due to sparsely activated experts. Recent studies propose to offload inactive experts from GPU memory to CPU memory to improve the serving efficiency of MoE models. However, they either incur high inference latency or high model memory footprints due to coarse-grained designs. To tame the latency-memory trade-off in MoE serving, we present fMoE, a fine-grained expert offloading system for MoE serving that achieves low inference latency with memory efficiency. We design fMoE to extract fine-grained expert selection patterns from MoE models and semantic hints from input prompts to efficiently guide expert prefetching, caching, and offloading decisions. fMoE is prototyped on top of HuggingFace Transformers and deployed on a six-GPU testbed. Experiments with open-source MoE models and real-world workloads show that fMoE reduces inference latency by 47% and improves expert hit rate by 36% over state-of-the-art solutions.
Harvesting Idle Resources in Serverless Computing via Reinforcement Learning
Aug 28, 2021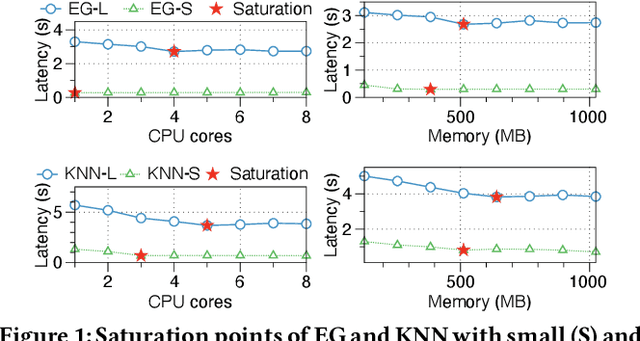

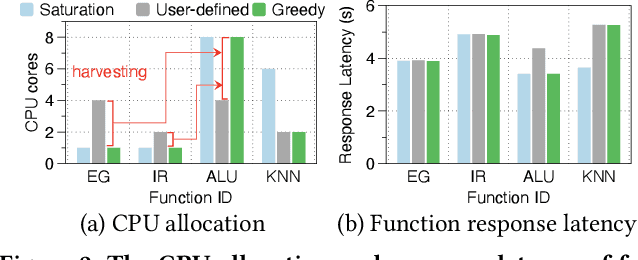
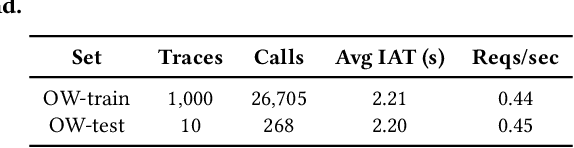
Serverless computing has become a new cloud computing paradigm that promises to deliver high cost-efficiency and simplified cloud deployment with automated resource scaling at a fine granularity. Users decouple a cloud application into chained functions and preset each serverless function's memory and CPU demands at megabyte-level and core-level, respectively. Serverless platforms then automatically scale the number of functions to accommodate the workloads. However, the complexities of chained functions make it non-trivial to accurately determine the resource demands of each function for users, leading to either resource over-provision or under-provision for individual functions. This paper presents FaaSRM, a new resource manager (RM) for serverless platforms that maximizes resource efficiency by dynamically harvesting idle resources from functions over-supplied to functions under-supplied. FaaSRM monitors each function's resource utilization in real-time, detects over-provisioning and under-provisioning, and applies deep reinforcement learning to harvest idle resources safely using a safeguard mechanism and accelerate functions efficiently. We have implemented and deployed a FaaSRM prototype in a 13-node Apache OpenWhisk cluster. Experimental results on the OpenWhisk cluster show that FaaSRM reduces the execution time of 98% of function invocations by 35.81% compared to the baseline RMs by harvesting idle resources from 38.8% of the invocations and accelerating 39.2% of the invocations.
Leveraging GPT-2 for Classifying Spam Reviews with Limited Labeled Data via Adversarial Training
Dec 24, 2020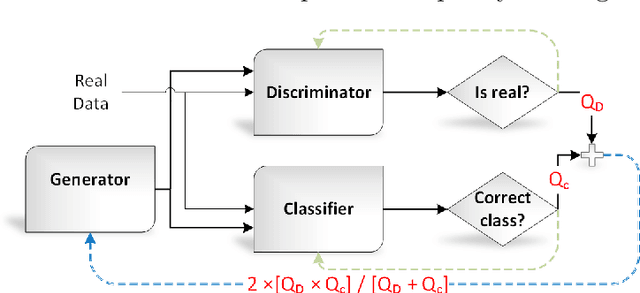
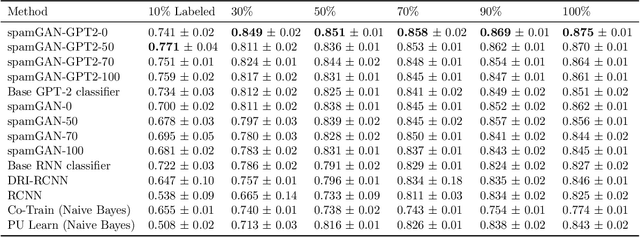
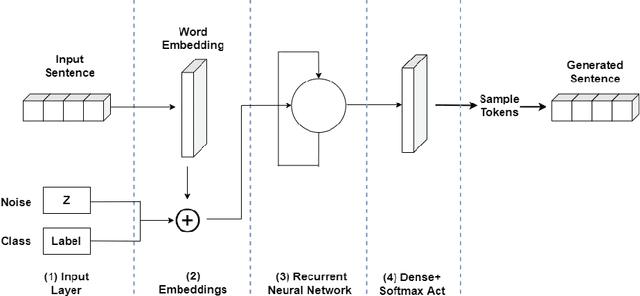
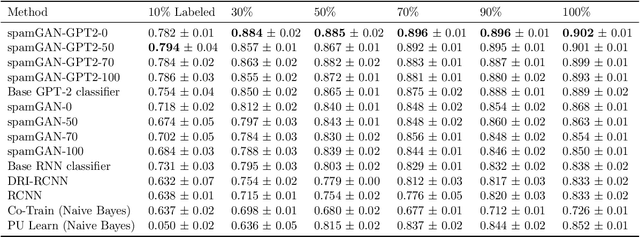
Online reviews are a vital source of information when purchasing a service or a product. Opinion spammers manipulate these reviews, deliberately altering the overall perception of the service. Though there exists a corpus of online reviews, only a few have been labeled as spam or non-spam, making it difficult to train spam detection models. We propose an adversarial training mechanism leveraging the capabilities of Generative Pre-Training 2 (GPT-2) for classifying opinion spam with limited labeled data and a large set of unlabeled data. Experiments on TripAdvisor and YelpZip datasets show that the proposed model outperforms state-of-the-art techniques by at least 7% in terms of accuracy when labeled data is limited. The proposed model can also generate synthetic spam/non-spam reviews with reasonable perplexity, thereby, providing additional labeled data during training.