 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Practical Guide to Multi-Objective Reinforcement Learning and Planning
Mar 17, 2021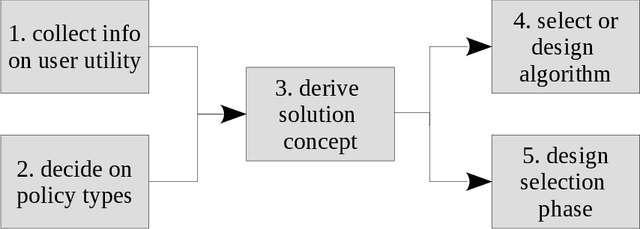

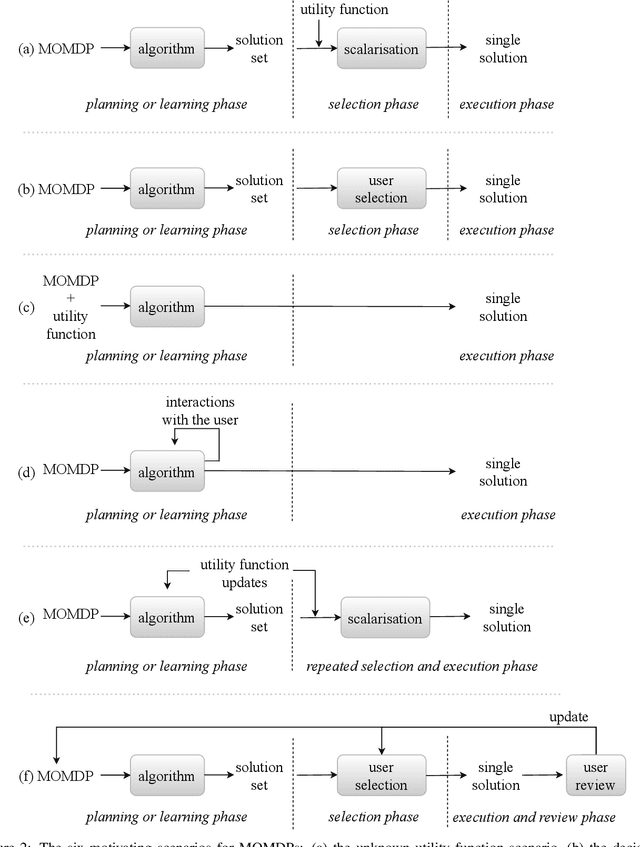
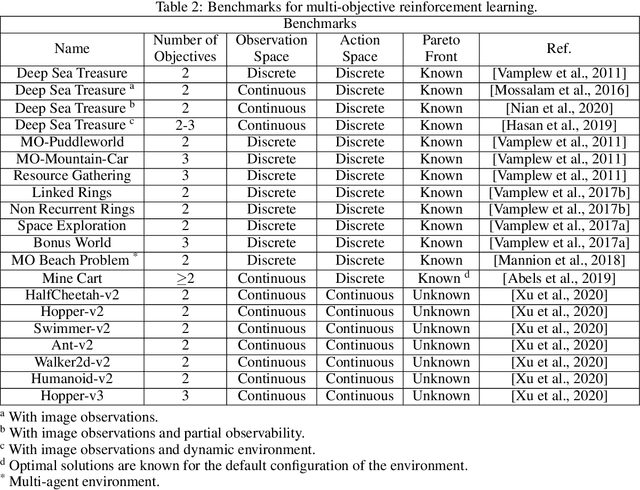
Real-world decision-making tasks are generally complex, requiring trade-offs between multiple, often conflicting, objectives. Despite this, the majority of research in reinforcement learning and decision-theoretic planning either assumes only a single objective, or that multiple objectives can be adequately handled via a simple linear combination. Such approaches may oversimplify the underlying problem and hence produce suboptimal results. This paper serves as a guide to the application of multi-objective methods to difficult problems, and is aimed at researchers who are already familiar with single-objective reinforcement learning and planning methods who wish to adopt a multi-objective perspective on their research, as well as practitioners who encounter multi-objective decision problems in practice. It identifies the factors that may influence the nature of the desired solution, and illustrates by example how these influence the design of multi-objective decision-making systems for complex problems.
Leveraging GPT-2 for Classifying Spam Reviews with Limited Labeled Data via Adversarial Training
Dec 24, 2020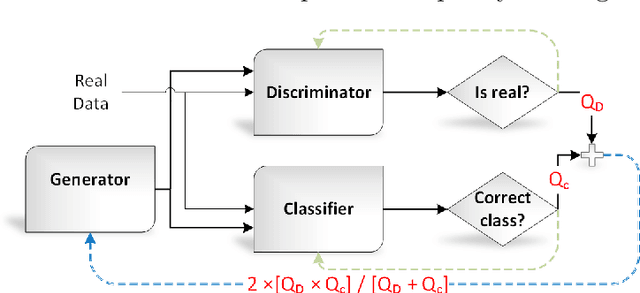
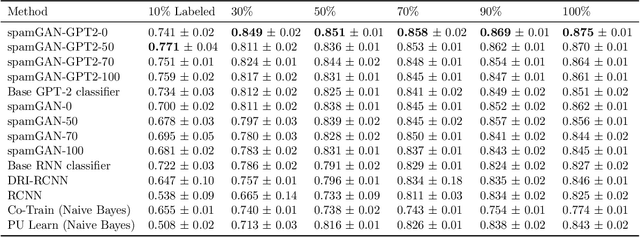
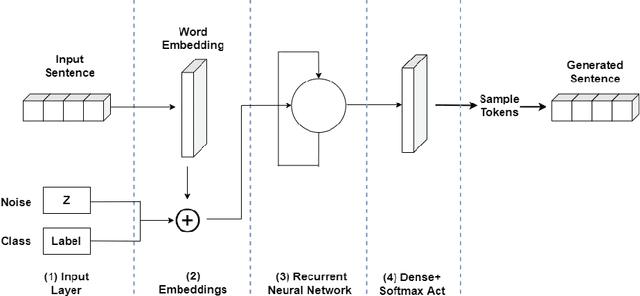
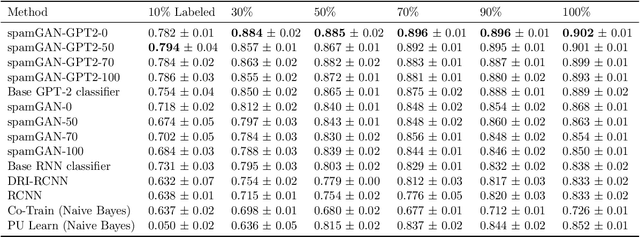
Online reviews are a vital source of information when purchasing a service or a product. Opinion spammers manipulate these reviews, deliberately altering the overall perception of the service. Though there exists a corpus of online reviews, only a few have been labeled as spam or non-spam, making it difficult to train spam detection models. We propose an adversarial training mechanism leveraging the capabilities of Generative Pre-Training 2 (GPT-2) for classifying opinion spam with limited labeled data and a large set of unlabeled data. Experiments on TripAdvisor and YelpZip datasets show that the proposed model outperforms state-of-the-art techniques by at least 7% in terms of accuracy when labeled data is limited. The proposed model can also generate synthetic spam/non-spam reviews with reasonable perplexity, thereby, providing additional labeled data during training.
EasyRL: A Simple and Extensible Reinforcement Learning Framework
Aug 04, 2020


In recent years, Reinforcement Learning (RL), has become a popular field of study as well as a tool for enterprises working on cutting-edge artificial intelligence research. To this end, many researchers have built RL frameworks such as openAI Gym and KerasRL for ease of use. While these works have made great strides towards bringing down the barrier of entry for those new to RL, we propose a much simpler framework called EasyRL, by providing an interactive graphical user interface for users to train and evaluate RL agents. As it is entirely graphical, EasyRL does not require programming knowledge for training and testing simple built-in RL agents. EasyRL also supports custom RL agents and environments, which can be highly beneficial for RL researchers in evaluating and comparing their RL models.
GANs for Semi-Supervised Opinion Spam Detection
Mar 19, 2019



Online reviews have become a vital source of information in purchasing a service (product). Opinion spammers manipulate reviews, affecting the overall perception of the service. A key challenge in detecting opinion spam is obtaining ground truth. Though there exists a large set of reviews online, only a few of them have been labeled spam or non-spam. In this paper, we propose spamGAN, a generative adversarial network which relies on limited set of labeled data as well as unlabeled data for opinion spam detection. spamGAN improves the state-of-the-art GAN based techniques for text classification. Experiments on TripAdvisor dataset show that spamGAN outperforms existing spam detection techniques when limited labeled data is used. Apart from detecting spam reviews, spamGAN can also generate reviews with reasonable perplexity.
Scaling POMDPs For Selecting Sellers in E-markets-Extended Version
Dec 09, 2015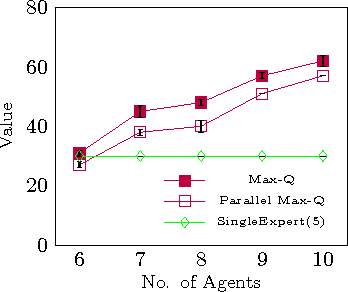

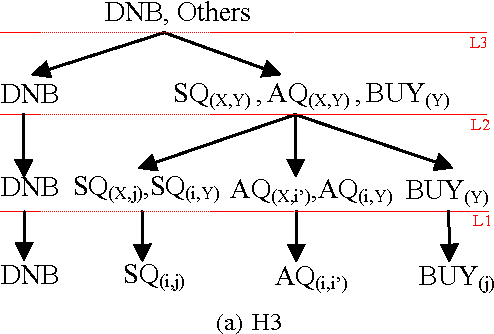

In multiagent e-marketplaces, buying agents need to select good sellers by querying other buyers (called advisors). Partially Observable Markov Decision Processes (POMDPs) have shown to be an effective framework for optimally selecting sellers by selectively querying advisors. However, current solution methods do not scale to hundreds or even tens of agents operating in the e-market. In this paper, we propose the Mixture of POMDP Experts (MOPE) technique, which exploits the inherent structure of trust-based domains, such as the seller selection problem in e-markets, by aggregating the solutions of smaller sub-POMDPs. We propose a number of variants of the MOPE approach that we analyze theoretically and empirically. Experiments show that MOPE can scale up to a hundred agents thereby leveraging the presence of more advisors to significantly improve buyer satisfaction.