 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR2Vul: Learning to Reason about Software Vulnerabilities with Reinforcement Learning and Structured Reasoning Distillation
Paper and Code
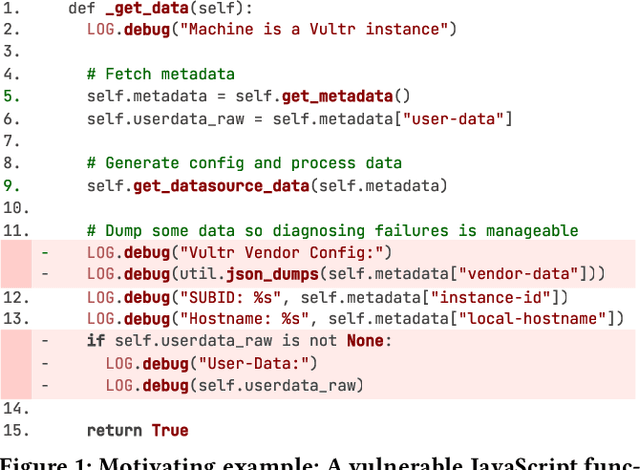


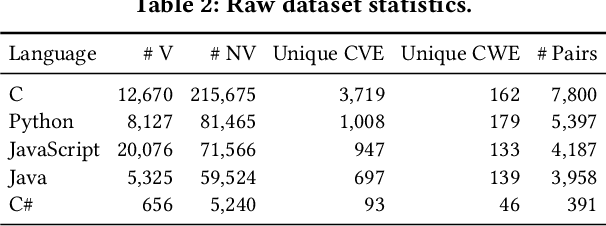
Large language models (LLMs) have shown promising performance in software vulnerability detection (SVD), yet their reasoning capabilities remain unreliable. Existing approaches relying on chain-of-thought (CoT) struggle to provide relevant and actionable security assessments. Additionally, effective SVD requires not only generating coherent reasoning but also differentiating between well-founded and misleading yet plausible security assessments, an aspect overlooked in prior work. To this end, we introduce R2Vul, a novel approach that distills structured reasoning into small LLMs using reinforcement learning from AI feedback (RLAIF). Through RLAIF, R2Vul enables LLMs to produce structured, security-aware reasoning that is actionable and reliable while explicitly learning to distinguish valid assessments from misleading ones. We evaluate R2Vul across five languages against SAST tools, CoT, instruction tuning, and classification-based baselines. Our results show that R2Vul with structured reasoning distillation enables a 1.5B student LLM to rival larger models while improving generalization to out-of-distribution vulnerabilities. Beyond model improvements, we contribute a large-scale, multilingual preference dataset featuring structured reasoning to support future research in SVD.