 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode Review Agent Benchmark
Mar 24, 2026Software engineering agents have shown significant promise in writing code. As AI agents permeate code writing, and generate huge volumes of code automatically -- the matter of code quality comes front and centre. As the automatically generated code gets integrated into huge code-bases -- the issue of code review and broadly quality assurance becomes important. In this paper, we take a fresh look at the problem and curate a code review dataset for AI agents to work with. Our dataset called c-CRAB (pronounced see-crab) can evaluate agents for code review tasks. Specifically given a pull-request (which could be coming from code generation agents or humans), if a code review agent produces a review, our evaluation framework can asses the reviewing capability of the code review agents. Our evaluation framework is used to evaluate the state of the art today -- the open-source PR-agent, as well as commercial code review agents from Devin, Claude Code, and Codex. Our c-CRAB dataset is systematically constructed from human reviews -- given a human review of a pull request instance we generate corresponding tests to evaluate the code review agent generated reviews. Such a benchmark construction gives us several insights. Firstly, the existing review agents taken together can solve only around 40% of the c-CRAB tasks, indicating the potential to close this gap by future research. Secondly, we observe that the agent reviews often consider different aspects from the human reviews -- indicating the potential for human-agent collaboration for code review that could be deployed in future software teams. Last but not the least, the agent generated tests from our data-set act as a held out test-suite and hence quality gate for agent generated reviews. What this will mean for future collaboration of code generation agents, test generation agents and code review agents -- remains to be investigated.
Enhancing Repository-Level Code Generation with Integrated Contextual Information
Jun 05, 2024

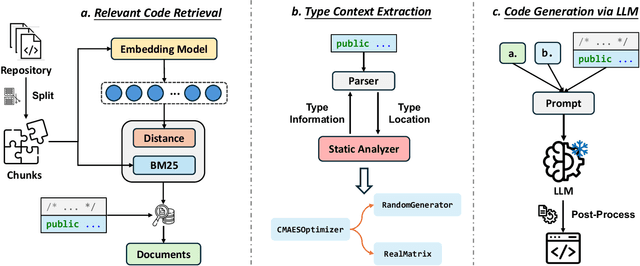

Large language models (LLMs) have demonstrated remarkable capabilities in code generation tasks. However, repository-level code generation presents unique challenges, particularly due to the need to utilize information spread across multiple files within a repository. Existing retrieval-based approaches sometimes fall short as they are limited in obtaining a broader and deeper repository context. In this paper, we present CatCoder, a novel code generation framework designed for statically typed programming languages. CatCoder enhances repository-level code generation by integrating relevant code and type context. Specifically, it leverages static analyzers to extract type dependencies and merges this information with retrieved code to create comprehensive prompts for LLMs. To evaluate the effectiveness of CatCoder, we adapt and construct benchmarks that include 199 Java tasks and 90 Rust tasks. The results show that CatCoder outperforms the RepoCoder baseline by up to 17.35%, in terms of pass@k score. Furthermore, the generalizability of CatCoder is assessed using various LLMs, including both code-specialized models and general-purpose models. Our findings indicate consistent performance improvements across all models, which underlines the practicality of CatCoder.
Evaluating Large Language Models with Runtime Behavior of Program Execution
Mar 25, 2024



Large language models for code (i.e., code LLMs) have shown strong code understanding and generation capabilities. To evaluate the capabilities of code LLMs in various aspects, many benchmarks have been proposed (e.g., HumanEval and ClassEval). Code reasoning is one of the most essential abilities of code LLMs, but existing benchmarks for code reasoning are not sufficient. Typically, they focus on predicting the input and output of a program, ignoring the evaluation of the intermediate behavior during program execution, as well as the logical consistency (e.g., the model should not give the correct output if the prediction of execution path is wrong) when performing the reasoning. To address these problems, in this paper, we propose a framework, namely REval, for evaluating code reasoning abilities and consistency of code LLMs with program execution. We utilize existing code benchmarks and adapt them to new benchmarks within our framework. A large-scale empirical study is conducted and most LLMs show unsatisfactory performance on both Runtime Behavior Reasoning (i.e., an average accuracy of 44.4%) and Incremental Consistency Evaluation (i.e., an average IC score of 10.3). Evaluation results of current code LLMs reflect the urgent need for the community to strengthen the code reasoning capability of code LLMs.