 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLPerturbator: Studying the Robustness of Code LLMs to Natural Language Variations
Paper and Code
Jun 28, 2024

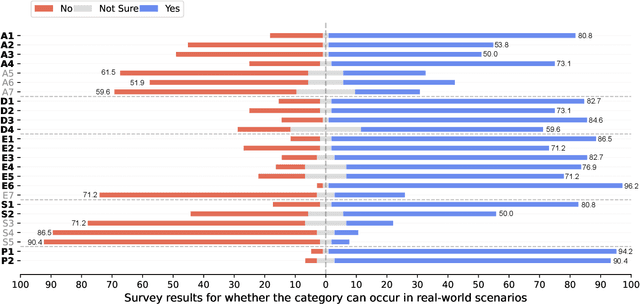
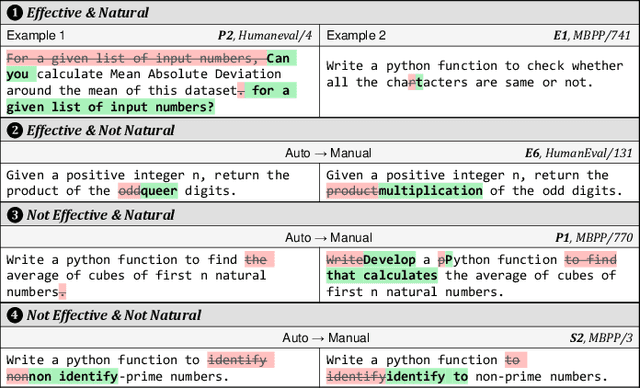
Large language models (LLMs) achieve promising results in code generation based on a given natural language description. They have been integrated into open-source projects and commercial products to facilitate daily coding activities. The natural language description in the prompt is crucial for LLMs to comprehend users' requirements. Prior studies uncover that LLMs are sensitive to the changes in the prompts, including slight changes that look inconspicuous. However, the natural language descriptions often vary in real-world scenarios (e.g., different formats, grammar, and wording). Prior studies on the robustness of LLMs are often based on random perturbations and such perturbations may not actually happen. In this paper, we conduct a comprehensive study to investigate how are code LLMs robust to variations of natural language description in real-world scenarios. We summarize 18 categories of perturbations of natural language and 3 combinations of co-occurred categories based on our literature review and an online survey with practitioners. We propose an automated framework, NLPerturbator, which can perform perturbations of each category given a set of prompts. Through a series of experiments on code generation using six code LLMs, we find that the perturbed prompts can decrease the performance of code generation by a considerable margin (e.g., up to 21.2%, and 4.8% to 6.1% on average). Our study highlights the importance of enhancing the robustness of LLMs to real-world variations in the prompts, as well as the essentiality of attentively constructing the prompts.