 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAMark: A Self-Anchored Text Watermarking with Paragraph-Level Paraphrase Robustness
May 25, 2026Semantic-level watermarking (SWM) improves robustness against text modifications by treating sentences as the basic unit. However, robustness to paragraph-level paraphrasing remains difficult because such attacks globally disrupt watermark signals by changing sentence order. In this work, we propose SAMark, a self-anchored watermarking framework that removes the dependency on sentence order by establishing a step-independent green region in semantic space. To improve detectability, we introduce a multi-channel hyperbolic scoring mechanism that amplifies watermark signals while suppressing noise from weakly aligned candidates. We further propose a diversity-aware filtering strategy that combines hard filtering with soft regularization, extending beyond simple n-gram repetition filters to address semantic redundancy. Experimental results show that SAMark achieves up to 90.2% TP@FP1% under typical paragraph-level paraphrasing attacks, outperforming the strongest prior baseline by more than 30% on average, while maintaining generation quality competitive with unwatermarked text and breaking the robustness-quality trade-off that limits prior methods.
ARC-STAR: Auditable Post-Hoc Correction for PDE Foundation Models
May 21, 2026Partial differential equation (PDE) foundation models are pretrained networks that forecast how physical fields like velocity and pressure evolve from a single reusable solver. On unfamiliar flows their predictions drift step by step, errors concentrate in a few regions, yet retraining destabilizes the network and uniform post-hoc correction overlooks this spatial concentration. To address this, we propose a frozen-solver post-hoc correction framework, Adaptive Risk-Calibrated Spatial Triage for Auditable Refinement (ARC-STAR). ARC-STAR organizes correction into three stages: a global corrector removes broad solver bias, a blockwise local refiner cleans the post-global residual, and, at deployment, a label-free score routes refinement to high-risk blocks under a compute budget. The framework is designed to be (i) frozen-host, preserving the pretrained solver without fine-tuning; (ii) auditable, with global and local stages trained and evaluated separately for measurable contributions; and (iii) budget-aware, using a blockwise interface that either refines the full field or routes limited compute to high-risk regions. Across five flow benchmarks spanning ten regime cells, ARC-STAR is the only method that cuts velocity rollout error by at least 36x over raw Poseidon on every cell. The global stage reduces raw host error by 91-99%, and the local stage further reduces the remaining post-global residual by up to 94.4%. Our code implementation is available at https://anonymous.4open.science/r/arc_star.
Towards Robust LLM Post-Training: Automatic Failure Management for Reinforcement Fine-Tuning
May 06, 2026Reinforcement fine-tuning (RFT) has become a core paradigm for post-training large language models, yet its training process remains highly fragile. Existing efforts mainly improve reliability at the system level or address specific issues in individual subproblems by modifying RFT algorithms. Despite their effectiveness, they largely overlook the problem of failure management at the training-process level. When training goes wrong, practitioners still rely heavily on expert-driven manual inspection and correction, and automatic failure management for RFT remains largely unexplored. In this paper, we take a first step toward systematic failure management for reinforcement fine-tuning. To understand the empirical structure of RFT failures, we first construct RFT-FaultBench, the first benchmark for fine-grained failures in reinforcement fine-tuning, covering 5 fault families, 16 fault types, 779 training runs, 22,549 train-step records, and 1,457,288 trajectory-level records. Based on this benchmark, we conduct a comprehensive empirical study showing that RFT failures are both observable from training dynamics and distinguishable through their empirical fault fingerprints. Building on these findings, we propose RFT-FM, an automatic failure management framework for reinforcement fine-tuning that unifies anomaly detection, failure diagnosis, and auto remediation in a closed loop. Experimental results show that RFT-FaultBench is neither trivial nor saturated: it exhibits clear anomaly structure while still posing substantial challenges, especially under subtle fault settings. Moreover, RFT-FM shows strong capability in detecting, diagnosing, and mitigating RFT failures.
Unveiling Language Routing Isolation in Multilingual MoE Models for Interpretable Subnetwork Adaptation
Apr 04, 2026Mixture-of-Experts (MoE) models exhibit striking performance disparities across languages, yet the internal mechanisms driving these gaps remain poorly understood. In this work, we conduct a systematic analysis of expert routing patterns in MoE models, revealing a phenomenon we term Language Routing Isolation, in which high- and low-resource languages tend to activate largely disjoint expert sets. Through layer-stratified analysis, we further show that routing patterns exhibit a layer-wise convergence-divergence pattern across model depth. Building on these findings, we propose RISE (Routing Isolation-guided Subnetwork Enhancement), a framework that exploits routing isolation to identify and adapt language-specific expert subnetworks. RISE applies a tripartite selection strategy, using specificity scores to identify language-specific experts in shallow and deep layers and overlap scores to select universal experts in middle layers. By training only the selected subnetwork while freezing all other parameters, RISE substantially improves low-resource language performance while preserving capabilities in other languages. Experiments on 10 languages demonstrate that RISE achieves target-language F1 gains of up to 10.85% with minimal cross-lingual degradation.
EvoSkills: Self-Evolving Agent Skills via Co-Evolutionary Verification
Apr 02, 2026Anthropic proposes the concept of skills for LLM agents to tackle multi-step professional tasks that simple tool invocations cannot address. A tool is a single, self-contained function, whereas a skill is a structured bundle of interdependent multi-file artifacts. Currently, skill generation is not only label-intensive due to manual authoring, but also may suffer from human--machine cognitive misalignment, which can lead to degraded agent performance, as evidenced by evaluations on SkillsBench. Therefore, we aim to enable agents to autonomously generate skills. However, existing self-evolving methods designed for tools cannot be directly applied to skills due to their increased complexity. To address these issues, we propose EvoSkills, a self-evolving skills framework that enables agents to autonomously construct complex, multi-file skill packages. Specifically, EvoSkills couples a Skill Generator that iteratively refines skills with a Surrogate Verifier that co-evolves to provide informative and actionable feedback without access to ground-truth test content. On SkillsBench, EvoSkills achieves the highest pass rate among five baselines on both Claude Code and Codex, and also exhibits strong generalization capabilities to six additional LLMs.
When Users Change Their Mind: Evaluating Interruptible Agents in Long-Horizon Web Navigation
Apr 01, 2026As LLM agents transition from short, static problem solving to executing complex, long-horizon tasks in dynamic environments, the ability to handle user interruptions, such as adding requirement or revising goals, during mid-task execution is becoming a core requirement for realistic deployment. However, existing benchmarks largely assume uninterrupted agent behavior or study interruptions only in short, unconstrained language tasks. In this paper, we present the first systematic study of interruptible agents in long-horizon, environmentally grounded web navigation tasks, where actions induce persistent state changes. We formalize three realistic interruption types, including addition, revision, and retraction, and introduce InterruptBench, a benchmark derived from WebArena-Lite that synthesizes high-quality interruption scenarios under strict semantic constraints. Using a unified interruption simulation framework, we evaluate six strong LLM backbones across single- and multi-turn interruption settings, analyzing both their effectiveness in adapting to updated intents and their efficiency in recovering from mid-task changes. Our results show that handling user interruptions effectively and efficiently during long-horizon agentic tasks remains challenging for powerful large-scale LLMs. Code and dataset are available at https://github.com/HenryPengZou/InterruptBench.
Unlocking Multimodal Document Intelligence: From Current Triumphs to Future Frontiers of Visual Document Retrieval
Feb 23, 2026With the rapid proliferation of multimodal information, Visual Document Retrieval (VDR) has emerged as a critical frontier in bridging the gap between unstructured visually rich data and precise information acquisition. Unlike traditional natural image retrieval, visual documents exhibit unique characteristics defined by dense textual content, intricate layouts, and fine-grained semantic dependencies. This paper presents the first comprehensive survey of the VDR landscape, specifically through the lens of the Multimodal Large Language Model (MLLM) era. We begin by examining the benchmark landscape, and subsequently dive into the methodological evolution, categorizing approaches into three primary aspects: multimodal embedding models, multimodal reranker models, and the integration of Retrieval-Augmented Generation (RAG) and Agentic systems for complex document intelligence. Finally, we identify persistent challenges and outline promising future directions, aiming to provide a clear roadmap for future multimodal document intelligence.
GM-PRM: A Generative Multimodal Process Reward Model for Multimodal Mathematical Reasoning
Aug 06, 2025Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities but often struggle with complex, multi-step mathematical reasoning, where minor errors in visual perception or logical deduction can lead to complete failure. While Process Reward Models (PRMs) offer step-by-step supervision, existing multimodal PRMs are limited to being binary verifiers that can identify but not correct errors, offering little explanatory power. To address these deficiencies, we introduce the Generative Multimodal Process Reward Model (GM-PRM), a novel paradigm that transforms the PRM from a passive judge into an active reasoning collaborator. Instead of a simple scalar score, GM-PRM provides a fine-grained, interpretable analysis of each reasoning step, evaluating its step intent, visual alignment, and logical soundness. More critically, GM-PRM is trained to generate a corrected version of the first erroneous step it identifies. This unique corrective capability enables our new test-time inference strategy, Refined Best-of-N (Refined-BoN). This framework actively enhances solution quality by using the PRM's generated correction to guide the policy model toward a more promising reasoning trajectory, thereby improving the diversity and correctness of the solution pool. We demonstrate that GM-PRM achieves state-of-the-art results on multiple multimodal math benchmarks, significantly boosting policy model performance with remarkable data efficiency, requiring only a 20K-sample training dataset. Our code will be released upon acceptance.
SAFEERASER: Enhancing Safety in Multimodal Large Language Models through Multimodal Machine Unlearning
Feb 18, 2025



As Multimodal Large Language Models (MLLMs) develop, their potential security issues have become increasingly prominent. Machine Unlearning (MU), as an effective strategy for forgetting specific knowledge in training data, has been widely used in privacy protection. However, MU for safety in MLLM has yet to be fully explored. To address this issue, we propose SAFEERASER, a safety unlearning benchmark for MLLMs, consisting of 3,000 images and 28.8K VQA pairs. We comprehensively evaluate unlearning methods from two perspectives: forget quality and model utility. Our findings show that existing MU methods struggle to maintain model performance while implementing the forget operation and often suffer from over-forgetting. Hence, we introduce Prompt Decouple (PD) Loss to alleviate over-forgetting through decouple prompt during unlearning process. To quantitatively measure over-forgetting mitigated by PD Loss, we propose a new metric called Safe Answer Refusal Rate (SARR). Experimental results demonstrate that combining PD Loss with existing unlearning methods can effectively prevent over-forgetting and achieve a decrease of 79.5% in the SARR metric of LLaVA-7B and LLaVA-13B, while maintaining forget quality and model utility. Our code and dataset will be released upon acceptance. Warning: This paper contains examples of harmful language and images, and reader discretion is recommended.
Look Twice Before You Answer: Memory-Space Visual Retracing for Hallucination Mitigation in Multimodal Large Language Models
Oct 04, 2024
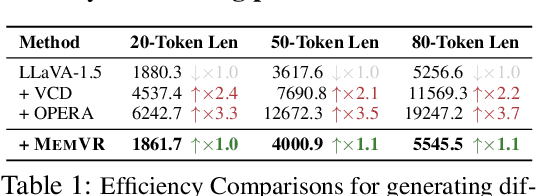
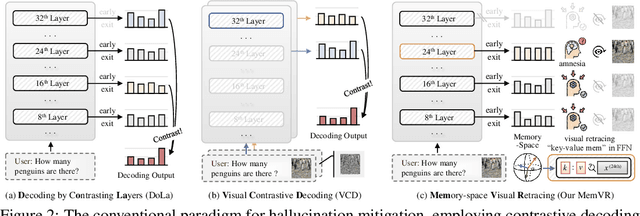
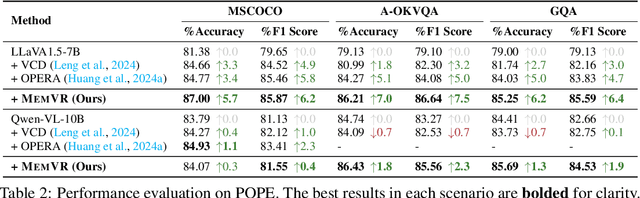
Despite their impressive capabilities, Multimodal Large Language Models (MLLMs) are susceptible to hallucinations, especially assertively fabricating content not present in the visual inputs. To address the aforementioned challenge, we follow a common cognitive process - when one's initial memory of critical on-sight details fades, it is intuitive to look at them a second time to seek a factual and accurate answer. Therefore, we introduce Memory-space Visual Retracing (MemVR), a novel hallucination mitigation paradigm that without the need for external knowledge retrieval or additional fine-tuning. In particular, we treat visual prompts as supplementary evidence to be reinjected into MLLMs via Feed Forward Network (FFN) as key-value memory, when the model is uncertain or even amnesic about question-relevant visual memories. Comprehensive experimental evaluations demonstrate that MemVR significantly mitigates hallucination issues across various MLLMs and excels in general benchmarks without incurring added time overhead, thus emphasizing its potential for widespread applicability.