 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Pose-based Estimation, Tracking and Action Recognition with Deep Learning: A Survey
Oct 19, 2023



Human pose analysis has garnered significant attention within both the research community and practical applications, owing to its expanding array of uses, including gaming, video surveillance, sports performance analysis, and human-computer interactions, among others. The advent of deep learning has significantly improved the accuracy of pose capture, making pose-based applications increasingly practical. This paper presents a comprehensive survey of pose-based applications utilizing deep learning, encompassing pose estimation, pose tracking, and action recognition.Pose estimation involves the determination of human joint positions from images or image sequences. Pose tracking is an emerging research direction aimed at generating consistent human pose trajectories over time. Action recognition, on the other hand, targets the identification of action types using pose estimation or tracking data. These three tasks are intricately interconnected, with the latter often reliant on the former. In this survey, we comprehensively review related works, spanning from single-person pose estimation to multi-person pose estimation, from 2D pose estimation to 3D pose estimation, from single image to video, from mining temporal context gradually to pose tracking, and lastly from tracking to pose-based action recognition. As a survey centered on the application of deep learning to pose analysis, we explicitly discuss both the strengths and limitations of existing techniques. Notably, we emphasize methodologies for integrating these three tasks into a unified framework within video sequences. Additionally, we explore the challenges involved and outline potential directions for future research.
Learning a Pose Lexicon for Semantic Action Recognition
Apr 01, 2016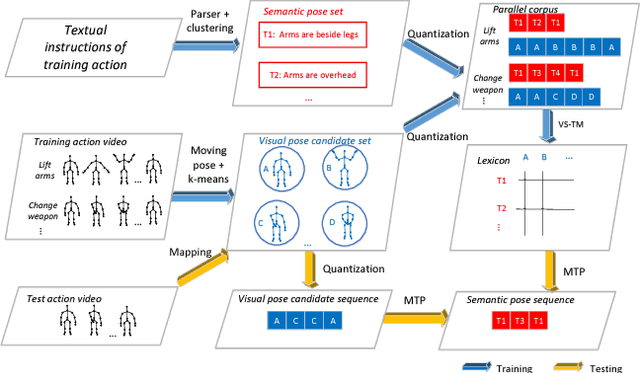



This paper presents a novel method for learning a pose lexicon comprising semantic poses defined by textual instructions and their associated visual poses defined by visual features. The proposed method simultaneously takes two input streams, semantic poses and visual pose candidates, and statistically learns a mapping between them to construct the lexicon. With the learned lexicon, action recognition can be cast as the problem of finding the maximum translation probability of a sequence of semantic poses given a stream of visual pose candidates. Experiments evaluating pre-trained and zero-shot action recognition conducted on MSRC-12 gesture and WorkoutSu-10 exercise datasets were used to verify the efficacy of the proposed method.