Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Pose Lexicon for Semantic Action Recognition
Paper and Code
Apr 01, 2016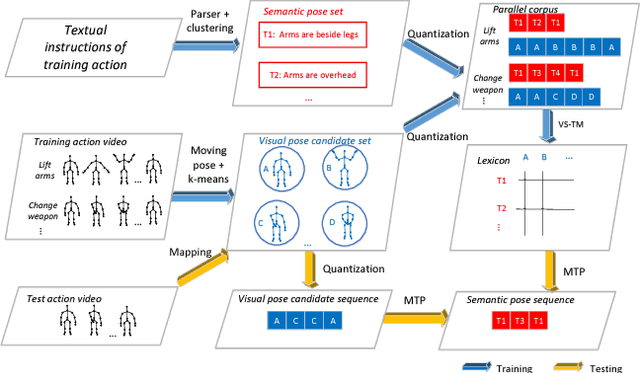



This paper presents a novel method for learning a pose lexicon comprising semantic poses defined by textual instructions and their associated visual poses defined by visual features. The proposed method simultaneously takes two input streams, semantic poses and visual pose candidates, and statistically learns a mapping between them to construct the lexicon. With the learned lexicon, action recognition can be cast as the problem of finding the maximum translation probability of a sequence of semantic poses given a stream of visual pose candidates. Experiments evaluating pre-trained and zero-shot action recognition conducted on MSRC-12 gesture and WorkoutSu-10 exercise datasets were used to verify the efficacy of the proposed method.
* Accepted by the 2016 IEEE International Conference on Multimedia and
Expo (ICME 2016). 6 pages paper and 4 pages supplementary material
View paper on