 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFT-HID: A Large Scale RGB-D Dataset for First and Third Person Human Interaction Analysis
Sep 21, 2022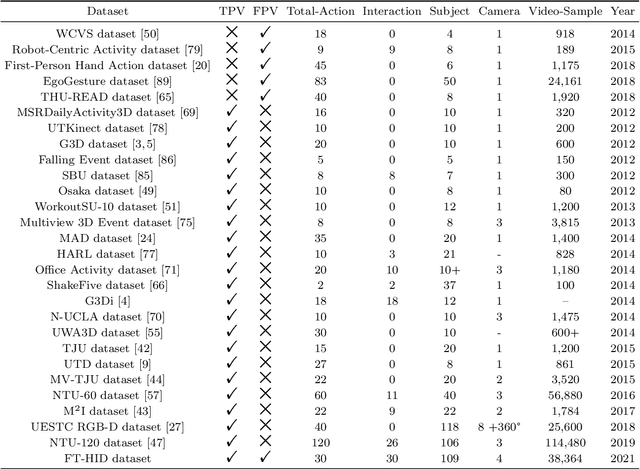
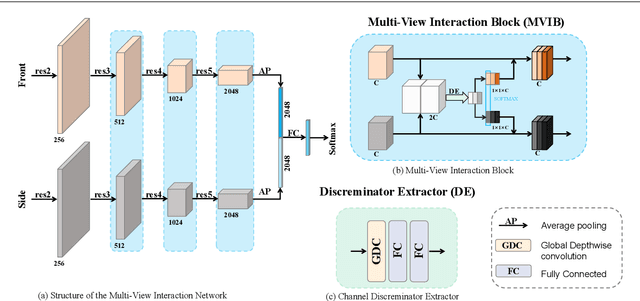
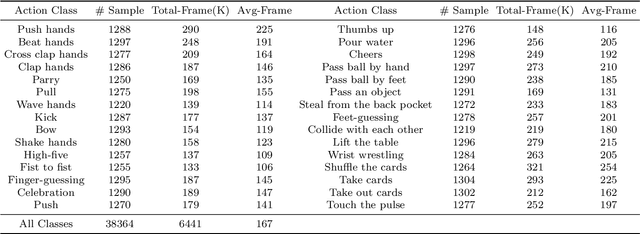
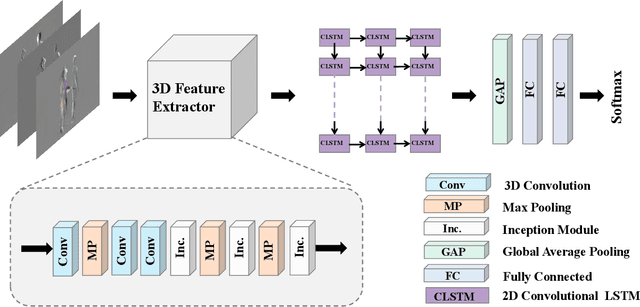
Analysis of human interaction is one important research topic of human motion analysis. It has been studied either using first person vision (FPV) or third person vision (TPV). However, the joint learning of both types of vision has so far attracted little attention. One of the reasons is the lack of suitable datasets that cover both FPV and TPV. In addition, existing benchmark datasets of either FPV or TPV have several limitations, including the limited number of samples, participant subjects, interaction categories, and modalities. In this work, we contribute a large-scale human interaction dataset, namely, FT-HID dataset. FT-HID contains pair-aligned samples of first person and third person visions. The dataset was collected from 109 distinct subjects and has more than 90K samples for three modalities. The dataset has been validated by using several existing action recognition methods. In addition, we introduce a novel multi-view interaction mechanism for skeleton sequences, and a joint learning multi-stream framework for first person and third person visions. Both methods yield promising results on the FT-HID dataset. It is expected that the introduction of this vision-aligned large-scale dataset will promote the development of both FPV and TPV, and their joint learning techniques for human action analysis. The dataset and code are available at \href{https://github.com/ENDLICHERE/FT-HID}{here}.
Learning Using Privileged Information for Zero-Shot Action Recognition
Jun 22, 2022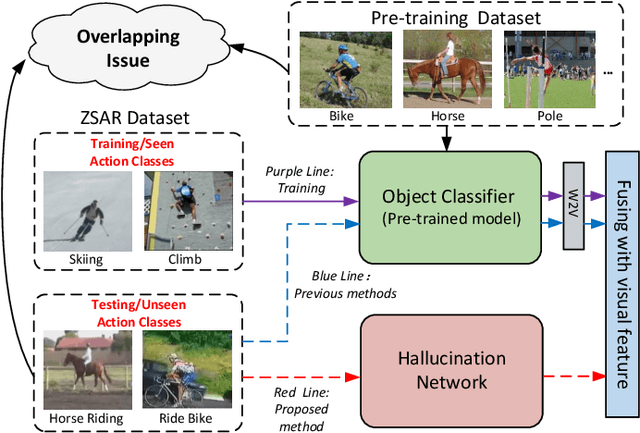
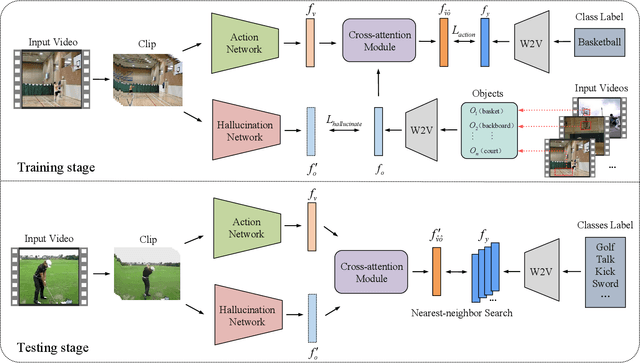
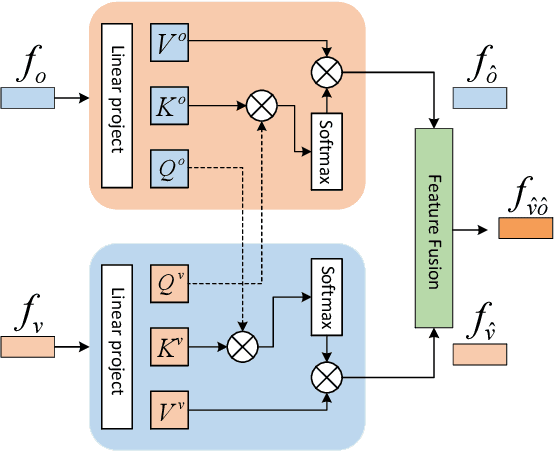
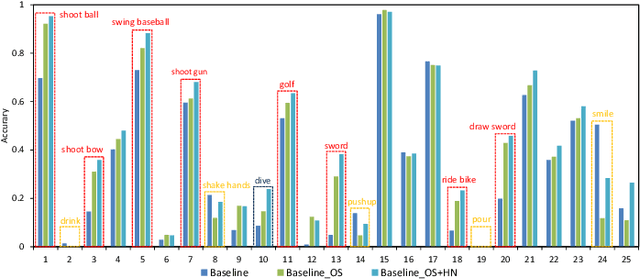
Zero-Shot Action Recognition (ZSAR) aims to recognize video actions that have never been seen during training. Most existing methods assume a shared semantic space between seen and unseen actions and intend to directly learn a mapping from a visual space to the semantic space. This approach has been challenged by the semantic gap between the visual space and semantic space. This paper presents a novel method that uses object semantics as privileged information to narrow the semantic gap and, hence, effectively, assist the learning. In particular, a simple hallucination network is proposed to implicitly extract object semantics during testing without explicitly extracting objects and a cross-attention module is developed to augment visual feature with the object semantics. Experiments on the Olympic Sports, HMDB51 and UCF101 datasets have shown that the proposed method outperforms the state-of-the-art methods by a large margin.
SAR-NAS: Skeleton-based Action Recognition via Neural Architecture Searching
Oct 29, 2020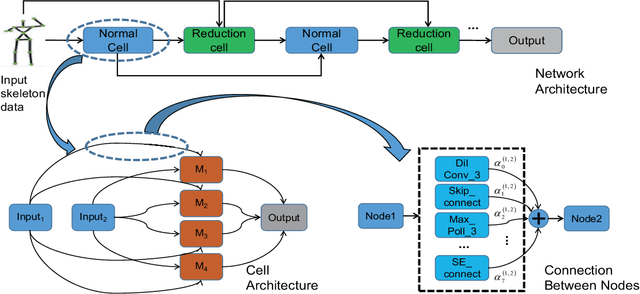
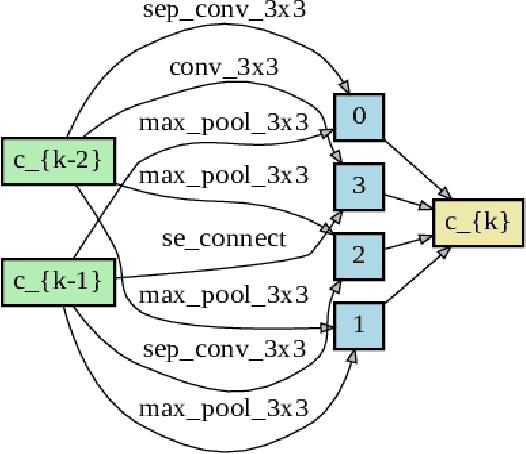
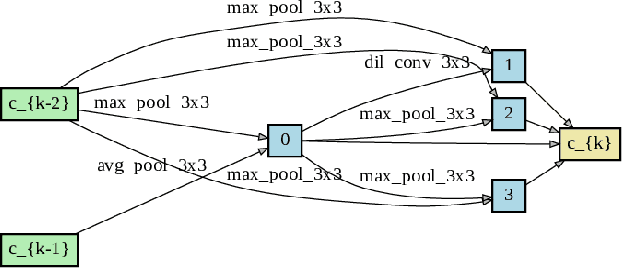

This paper presents a study of automatic design of neural network architectures for skeleton-based action recognition. Specifically, we encode a skeleton-based action instance into a tensor and carefully define a set of operations to build two types of network cells: normal cells and reduction cells. The recently developed DARTS (Differentiable Architecture Search) is adopted to search for an effective network architecture that is built upon the two types of cells. All operations are 2D based in order to reduce the overall computation and search space. Experiments on the challenging NTU RGB+D and Kinectics datasets have verified that most of the networks developed to date for skeleton-based action recognition are likely not compact and efficient. The proposed method provides an approach to search for such a compact network that is able to achieve comparative or even better performance than the state-of-the-art methods.