 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFT-HID: A Large Scale RGB-D Dataset for First and Third Person Human Interaction Analysis
Paper and Code
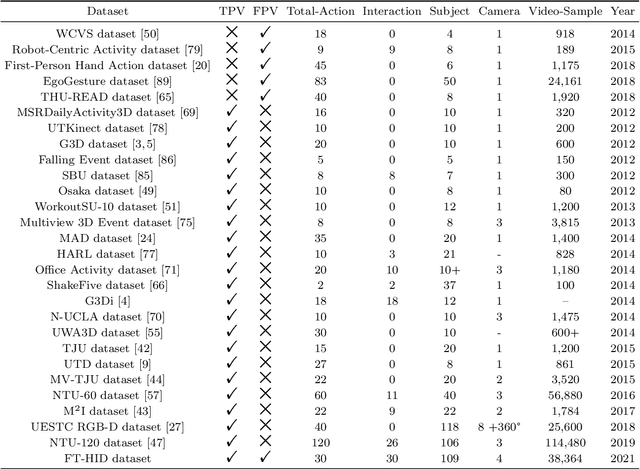
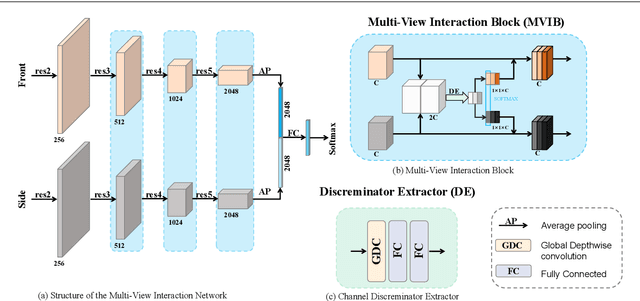
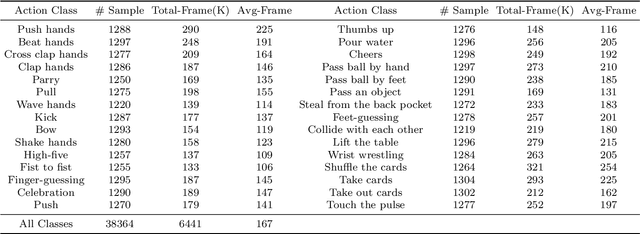
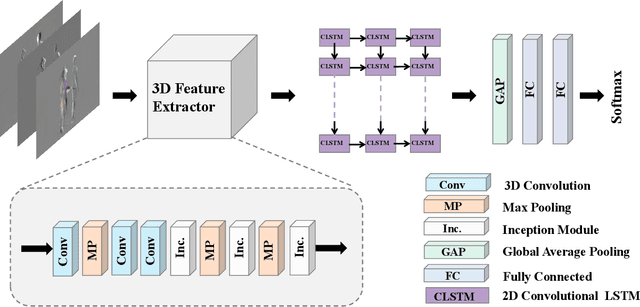
Analysis of human interaction is one important research topic of human motion analysis. It has been studied either using first person vision (FPV) or third person vision (TPV). However, the joint learning of both types of vision has so far attracted little attention. One of the reasons is the lack of suitable datasets that cover both FPV and TPV. In addition, existing benchmark datasets of either FPV or TPV have several limitations, including the limited number of samples, participant subjects, interaction categories, and modalities. In this work, we contribute a large-scale human interaction dataset, namely, FT-HID dataset. FT-HID contains pair-aligned samples of first person and third person visions. The dataset was collected from 109 distinct subjects and has more than 90K samples for three modalities. The dataset has been validated by using several existing action recognition methods. In addition, we introduce a novel multi-view interaction mechanism for skeleton sequences, and a joint learning multi-stream framework for first person and third person visions. Both methods yield promising results on the FT-HID dataset. It is expected that the introduction of this vision-aligned large-scale dataset will promote the development of both FPV and TPV, and their joint learning techniques for human action analysis. The dataset and code are available at \href{https://github.com/ENDLICHERE/FT-HID}{here}.