 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Using Privileged Information for Zero-Shot Action Recognition
Paper and Code
Jun 22, 2022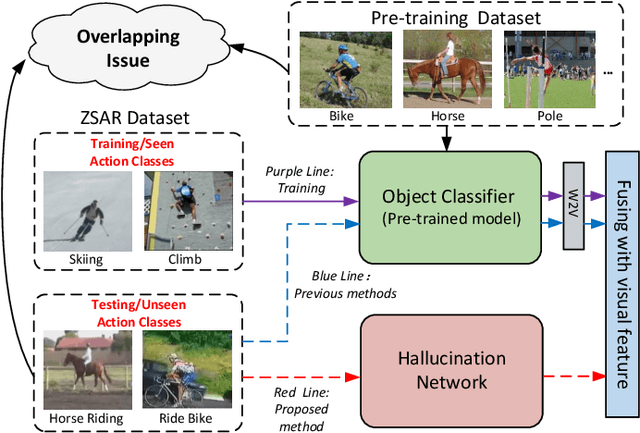
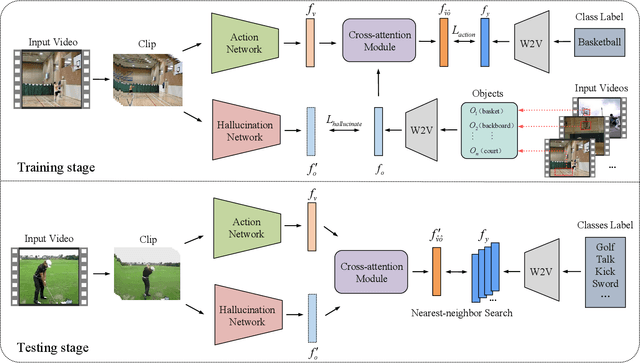
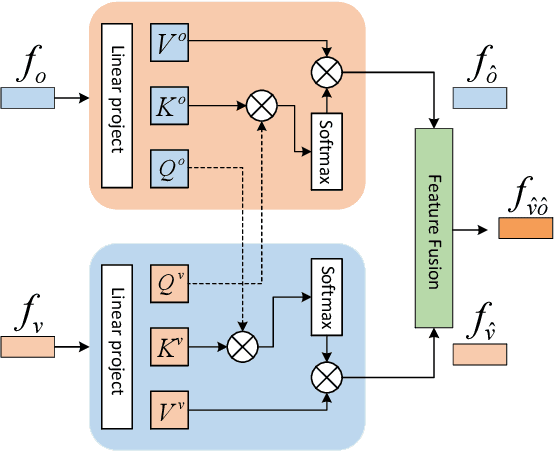
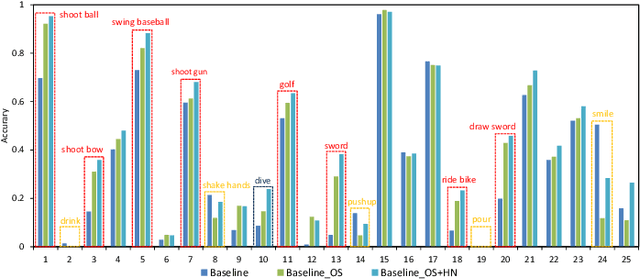
Zero-Shot Action Recognition (ZSAR) aims to recognize video actions that have never been seen during training. Most existing methods assume a shared semantic space between seen and unseen actions and intend to directly learn a mapping from a visual space to the semantic space. This approach has been challenged by the semantic gap between the visual space and semantic space. This paper presents a novel method that uses object semantics as privileged information to narrow the semantic gap and, hence, effectively, assist the learning. In particular, a simple hallucination network is proposed to implicitly extract object semantics during testing without explicitly extracting objects and a cross-attention module is developed to augment visual feature with the object semantics. Experiments on the Olympic Sports, HMDB51 and UCF101 datasets have shown that the proposed method outperforms the state-of-the-art methods by a large margin.