 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemember and Recall: Associative-Memory-based Trajectory Prediction
Oct 03, 2024



Trajectory prediction is a pivotal component of autonomous driving systems, enabling the application of accumulated movement experience to current scenarios. Although most existing methods concentrate on learning continuous representations to gain valuable experience, they often suffer from computational inefficiencies and struggle with unfamiliar situations. To address this issue, we propose the Fragmented-Memory-based Trajectory Prediction (FMTP) model, inspired by the remarkable learning capabilities of humans, particularly their ability to leverage accumulated experience and recall relevant memories in unfamiliar situations. The FMTP model employs discrete representations to enhance computational efficiency by reducing information redundancy while maintaining the flexibility to utilize past experiences. Specifically, we design a learnable memory array by consolidating continuous trajectory representations from the training set using defined quantization operations during the training phase. This approach further eliminates redundant information while preserving essential features in discrete form. Additionally, we develop an advanced reasoning engine based on language models to deeply learn the associative rules among these discrete representations. Our method has been evaluated on various public datasets, including ETH-UCY, inD, SDD, nuScenes, Waymo, and VTL-TP. The extensive experimental results demonstrate that our approach achieves significant performance and extracts more valuable experience from past trajectories to inform the current state.
Focal and Global Spatial-Temporal Transformer for Skeleton-based Action Recognition
Oct 06, 2022
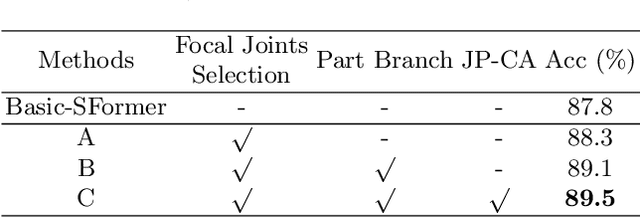
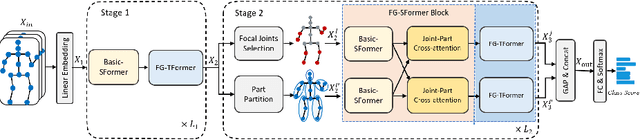

Despite great progress achieved by transformer in various vision tasks, it is still underexplored for skeleton-based action recognition with only a few attempts. Besides, these methods directly calculate the pair-wise global self-attention equally for all the joints in both the spatial and temporal dimensions, undervaluing the effect of discriminative local joints and the short-range temporal dynamics. In this work, we propose a novel Focal and Global Spatial-Temporal Transformer network (FG-STFormer), that is equipped with two key components: (1) FG-SFormer: focal joints and global parts coupling spatial transformer. It forces the network to focus on modelling correlations for both the learned discriminative spatial joints and human body parts respectively. The selective focal joints eliminate the negative effect of non-informative ones during accumulating the correlations. Meanwhile, the interactions between the focal joints and body parts are incorporated to enhance the spatial dependencies via mutual cross-attention. (2) FG-TFormer: focal and global temporal transformer. Dilated temporal convolution is integrated into the global self-attention mechanism to explicitly capture the local temporal motion patterns of joints or body parts, which is found to be vital important to make temporal transformer work. Extensive experimental results on three benchmarks, namely NTU-60, NTU-120 and NW-UCLA, show our FG-STFormer surpasses all existing transformer-based methods, and compares favourably with state-of-the art GCN-based methods.
D2-TPred: Discontinuous Dependency for Trajectory Prediction under Traffic Lights
Jul 21, 2022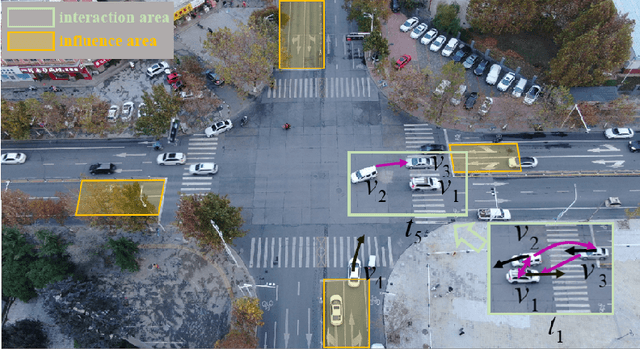
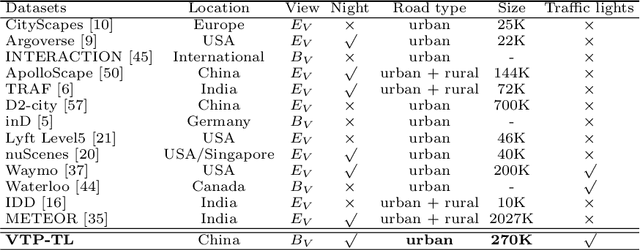
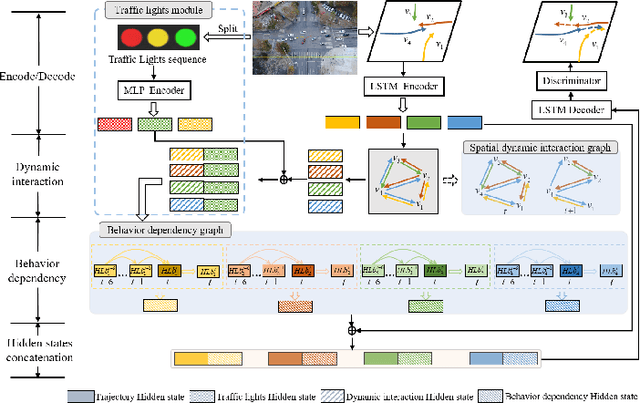
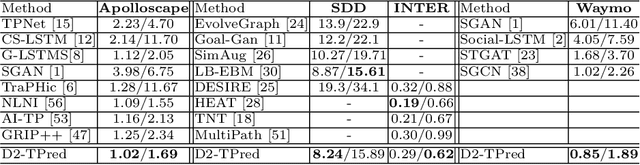
A profound understanding of inter-agent relationships and motion behaviors is important to achieve high-quality planning when navigating in complex scenarios, especially at urban traffic intersections. We present a trajectory prediction approach with respect to traffic lights, D2-TPred, which uses a spatial dynamic interaction graph (SDG) and a behavior dependency graph (BDG) to handle the problem of discontinuous dependency in the spatial-temporal space. Specifically, the SDG is used to capture spatial interactions by reconstructing sub-graphs for different agents with dynamic and changeable characteristics during each frame. The BDG is used to infer motion tendency by modeling the implicit dependency of the current state on priors behaviors, especially the discontinuous motions corresponding to acceleration, deceleration, or turning direction. Moreover, we present a new dataset for vehicle trajectory prediction under traffic lights called VTP-TL. Our experimental results show that our model achieves more than {20.45% and 20.78% }improvement in terms of ADE and FDE, respectively, on VTP-TL as compared to other trajectory prediction algorithms. The dataset and code are available at: https://github.com/VTP-TL/D2-TPred.
Multi-Agent Broad Reinforcement Learning for Intelligent Traffic Light Control
Mar 08, 2022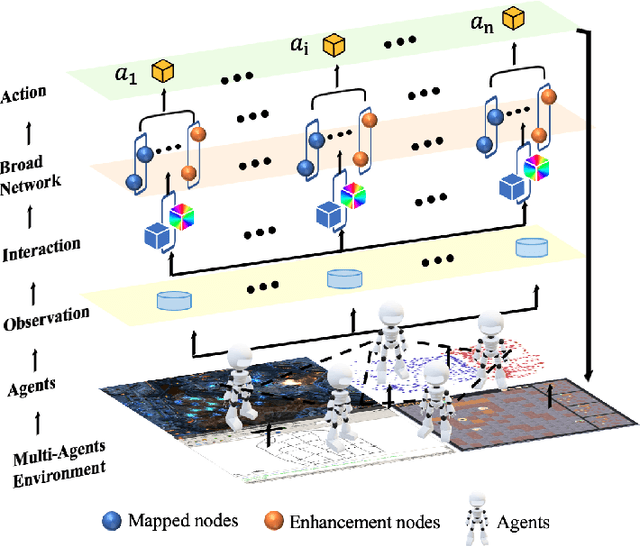
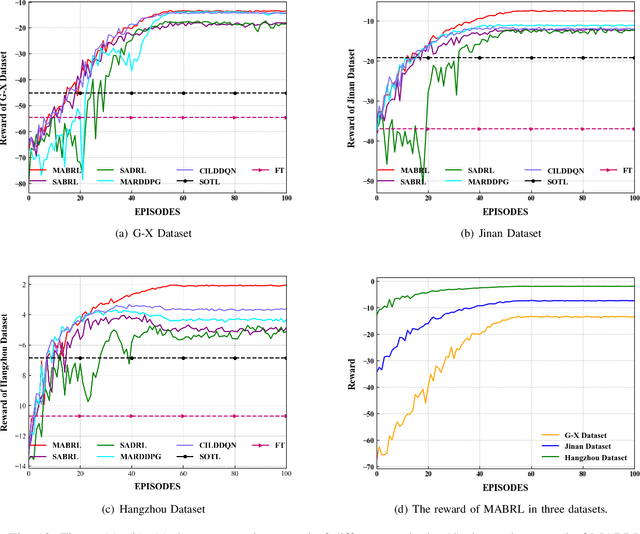
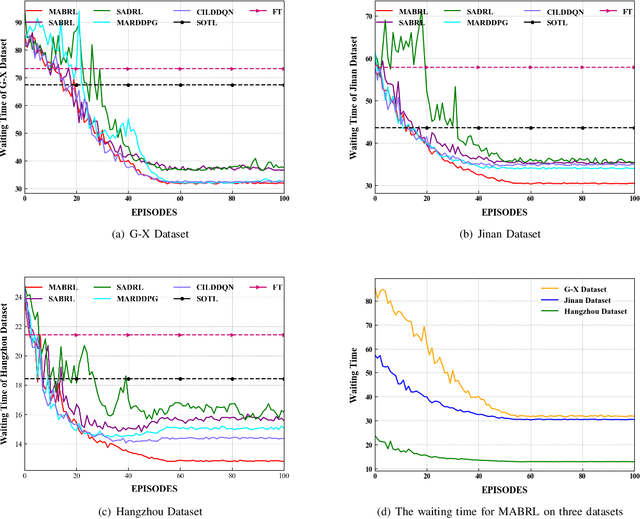
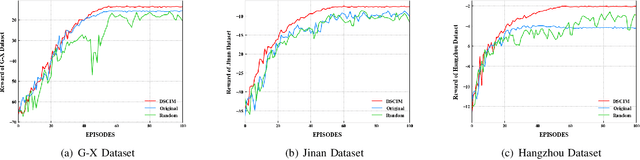
Intelligent Traffic Light Control System (ITLCS) is a typical Multi-Agent System (MAS), which comprises multiple roads and traffic lights.Constructing a model of MAS for ITLCS is the basis to alleviate traffic congestion. Existing approaches of MAS are largely based on Multi-Agent Deep Reinforcement Learning (MADRL). Although the Deep Neural Network (DNN) of MABRL is effective, the training time is long, and the parameters are difficult to trace. Recently, Broad Learning Systems (BLS) provided a selective way for learning in the deep neural networks by a flat network. Moreover, Broad Reinforcement Learning (BRL) extends BLS in Single Agent Deep Reinforcement Learning (SADRL) problem with promising results. However, BRL does not focus on the intricate structures and interaction of agents. Motivated by the feature of MADRL and the issue of BRL, we propose a Multi-Agent Broad Reinforcement Learning (MABRL) framework to explore the function of BLS in MAS. Firstly, unlike most existing MADRL approaches, which use a series of deep neural networks structures, we model each agent with broad networks. Then, we introduce a dynamic self-cycling interaction mechanism to confirm the "3W" information: When to interact, Which agents need to consider, What information to transmit. Finally, we do the experiments based on the intelligent traffic light control scenario. We compare the MABRL approach with six different approaches, and experimental results on three datasets verify the effectiveness of MABRL.
Dynamic Hypergraph Convolutional Networks for Skeleton-Based Action Recognition
Dec 20, 2021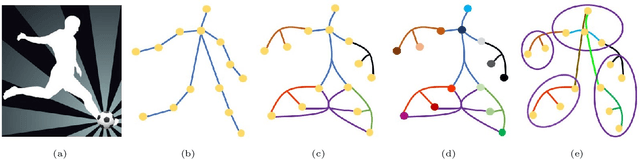
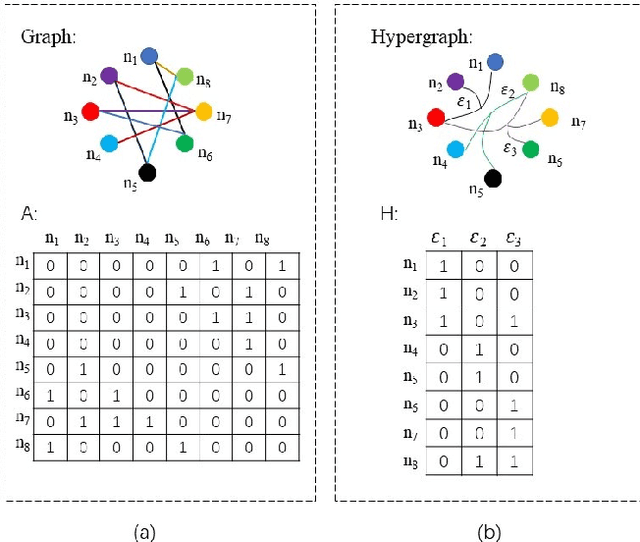
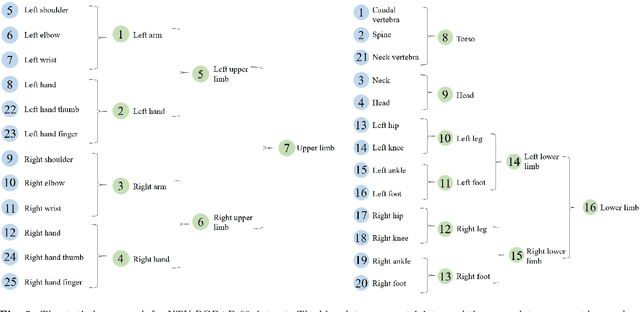
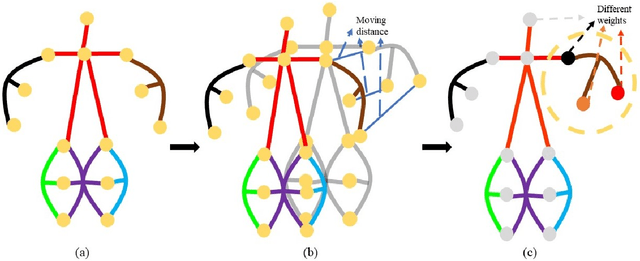
Graph convolutional networks (GCNs) based methods have achieved advanced performance on skeleton-based action recognition task. However, the skeleton graph cannot fully represent the motion information contained in skeleton data. In addition, the topology of the skeleton graph in the GCN-based methods is manually set according to natural connections, and it is fixed for all samples, which cannot well adapt to different situations. In this work, we propose a novel dynamic hypergraph convolutional networks (DHGCN) for skeleton-based action recognition. DHGCN uses hypergraph to represent the skeleton structure to effectively exploit the motion information contained in human joints. Each joint in the skeleton hypergraph is dynamically assigned the corresponding weight according to its moving, and the hypergraph topology in our model can be dynamically adjusted to different samples according to the relationship between the joints. Experimental results demonstrate that the performance of our model achieves competitive performance on three datasets: Kinetics-Skeleton 400, NTU RGB+D 60, and NTU RGB+D 120.
SSAGCN: Social Soft Attention Graph Convolution Network for Pedestrian Trajectory Prediction
Dec 05, 2021

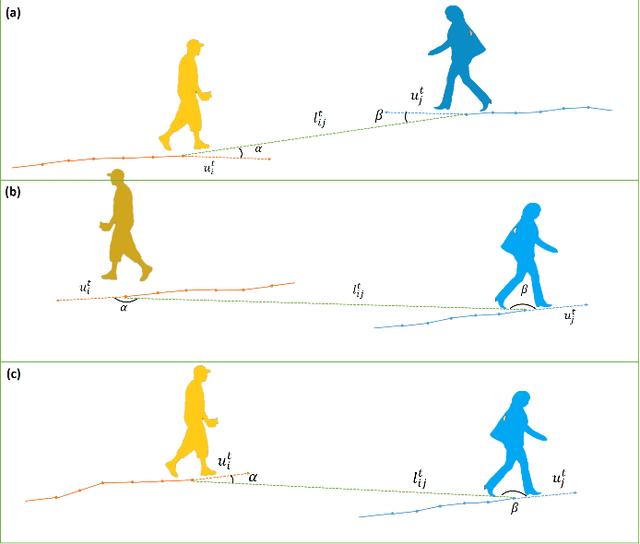
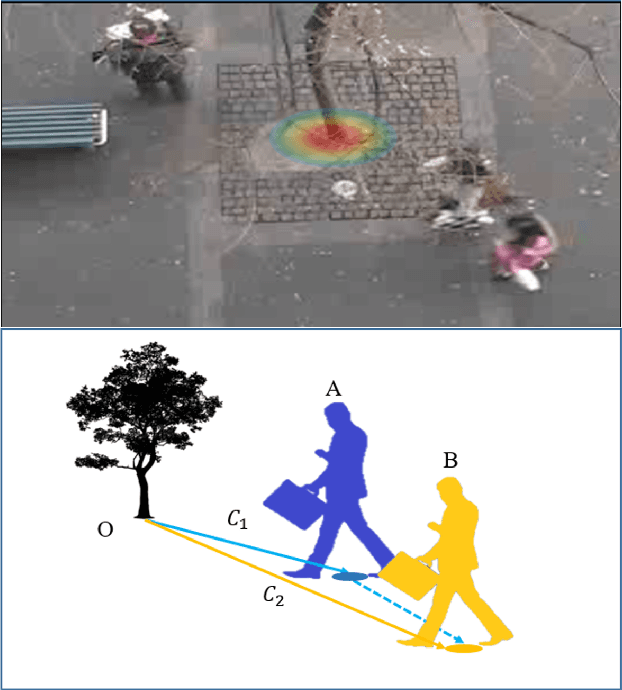
Pedestrian trajectory prediction is an important technique of autonomous driving, which has become a research hot-spot in recent years. Previous methods mainly rely on the position relationship of pedestrians to model social interaction, which is obviously not enough to represent the complex cases in real situations. In addition, most of existing work usually introduce the scene interaction module as an independent branch and embed the social interaction features in the process of trajectory generation, rather than simultaneously carrying out the social interaction and scene interaction, which may undermine the rationality of trajectory prediction. In this paper, we propose one new prediction model named Social Soft Attention Graph Convolution Network (SSAGCN) which aims to simultaneously handle social interactions among pedestrians and scene interactions between pedestrians and environments. In detail, when modeling social interaction, we propose a new \emph{social soft attention function}, which fully considers various interaction factors among pedestrians. And it can distinguish the influence of pedestrians around the agent based on different factors under various situations. For the physical interaction, we propose one new \emph{sequential scene sharing mechanism}. The influence of the scene on one agent at each moment can be shared with other neighbors through social soft attention, therefore the influence of the scene is expanded both in spatial and temporal dimension. With the help of these improvements, we successfully obtain socially and physically acceptable predicted trajectories. The experiments on public available datasets prove the effectiveness of SSAGCN and have achieved state-of-the-art results.
Contrastive Proposal Extension with LSTM Network for Weakly Supervised Object Detection
Oct 16, 2021


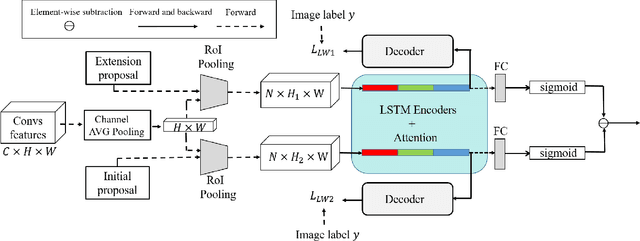
Weakly supervised object detection (WSOD) has attracted more and more attention since it only uses image-level labels and can save huge annotation costs. Most of the WSOD methods use Multiple Instance Learning (MIL) as their basic framework, which regard it as an instance classification problem. However, these methods based on MIL tends to converge only on the most discriminate regions of different instances, rather than their corresponding complete regions, that is, insufficient integrity. Inspired by the habit of observing things by the human, we propose a new method by comparing the initial proposals and the extension ones to optimize those initial proposals. Specifically, we propose one new strategy for WSOD by involving contrastive proposal extension (CPE), which consists of multiple directional contrastive proposal extensions (D-CPE), and each D-CPE contains encoders based on LSTM network and corresponding decoders. Firstly, the boundary of initial proposals in MIL is extended to different positions according to well-designed sequential order. Then, CPE compares the extended proposal and the initial proposal by extracting the feature semantics of them using the encoders, and calculates the integrity of the initial proposal to optimize the score of the initial proposal. These contrastive contextual semantics will guide the basic WSOD to suppress bad proposals and improve the scores of good ones. In addition, a simple two-stream network is designed as the decoder to constrain the temporal coding of LSTM and improve the performance of WSOD further. Experiments on PASCAL VOC 2007, VOC 2012 and MS-COCO datasets show that our method has achieved the state-of-the-art results.
User-Guided Personalized Image Aesthetic Assessment based on Deep Reinforcement Learning
Jun 14, 2021

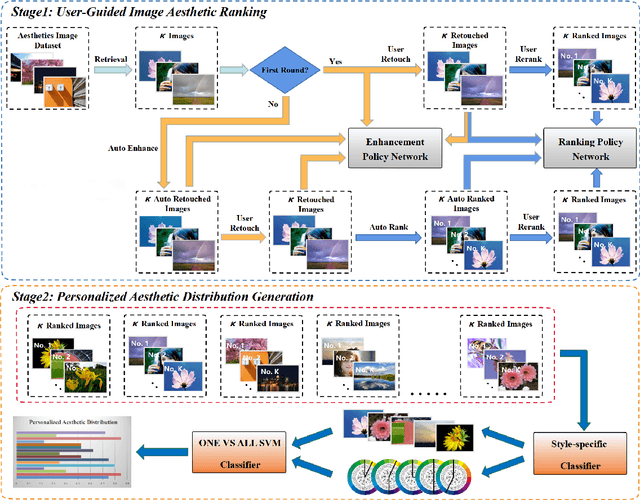
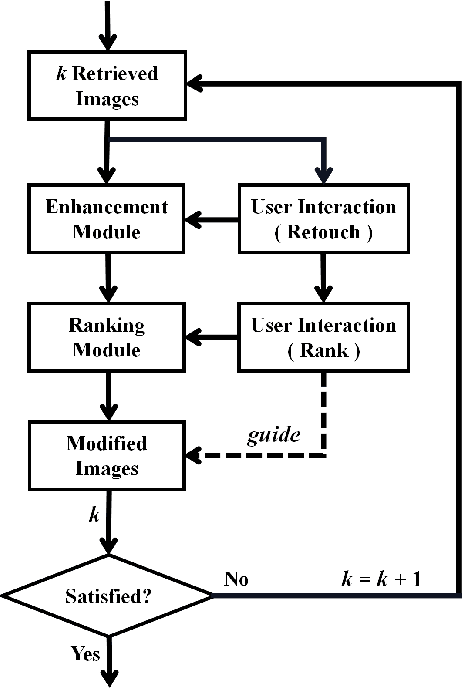
Personalized image aesthetic assessment (PIAA) has recently become a hot topic due to its usefulness in a wide variety of applications such as photography, film and television, e-commerce, fashion design and so on. This task is more seriously affected by subjective factors and samples provided by users. In order to acquire precise personalized aesthetic distribution by small amount of samples, we propose a novel user-guided personalized image aesthetic assessment framework. This framework leverages user interactions to retouch and rank images for aesthetic assessment based on deep reinforcement learning (DRL), and generates personalized aesthetic distribution that is more in line with the aesthetic preferences of different users. It mainly consists of two stages. In the first stage, personalized aesthetic ranking is generated by interactive image enhancement and manual ranking, meanwhile two policy networks will be trained. The images will be pushed to the user for manual retouching and simultaneously to the enhancement policy network. The enhancement network utilizes the manual retouching results as the optimization goals of DRL. After that, the ranking process performs the similar operations like the retouching mentioned before. These two networks will be trained iteratively and alternatively to help to complete the final personalized aesthetic assessment automatically. In the second stage, these modified images are labeled with aesthetic attributes by one style-specific classifier, and then the personalized aesthetic distribution is generated based on the multiple aesthetic attributes of these images, which conforms to the aesthetic preference of users better.
Antagonistic Crowd Simulation Model Integrating Emotion Contagion and Deep Reinforcement Learning
Apr 29, 2021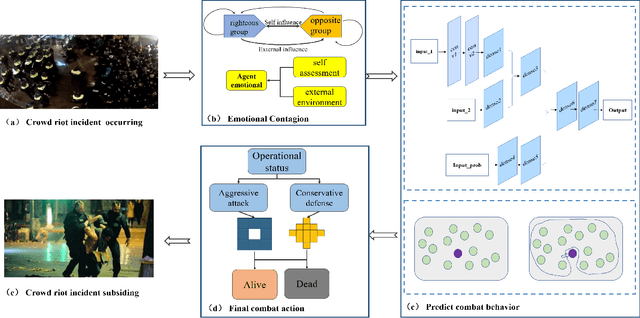


The antagonistic behavior of the crowd often exacerbates the seriousness of the situation in sudden riots, where the spreading of antagonistic emotion and behavioral decision making in the crowd play very important roles. However, the mechanism of complex emotion influencing decision making, especially in the environment of sudden confrontation, has not yet been explored clearly. In this paper, we propose one new antagonistic crowd simulation model by combing emotional contagion and deep reinforcement learning (ACSED). Firstly, we build a group emotional contagion model based on the improved SIS contagion disease model, and estimate the emotional state of the group at each time step during the simulation. Then, the tendency of group antagonistic behavior is modeled based on Deep Q Network (DQN), where the agent can learn the combat behavior autonomously, and leverages the mean field theory to quickly calculate the influence of other surrounding individuals on the central one. Finally, the rationality of the predicted behaviors by the DQN is further analyzed in combination with group emotion, and the final combat behavior of the agent is determined. The method proposed in this paper is verified through several different settings of experiments. The results prove that emotions have a vital impact on the group combat, and positive emotional states are more conducive to combat. Moreover, by comparing the simulation results with real scenes, the feasibility of the method is further verified, which can provide good reference for formulating battle plans and improving the winning rate of righteous groups battles in a variety of situations.
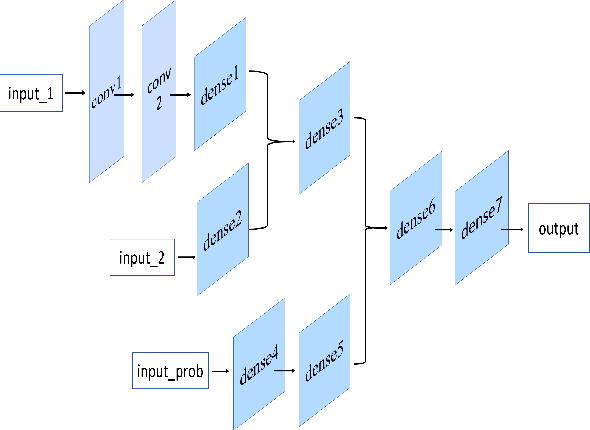
Probability Trajectory: One New Movement Description for Trajectory Prediction
Jan 26, 2021
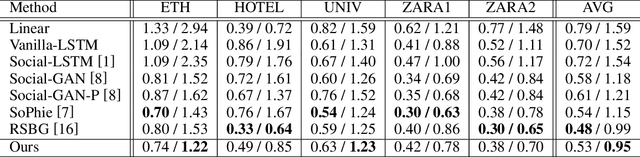


Trajectory prediction is a fundamental and challenging task for numerous applications, such as autonomous driving and intelligent robots. Currently, most of existing work treat the pedestrian trajectory as a series of fixed two-dimensional coordinates. However, in real scenarios, the trajectory often exhibits randomness, and has its own probability distribution. Inspired by this observed fact, also considering other movement characteristics of pedestrians, we propose one simple and intuitive movement description, probability trajectory, which maps the coordinate points of pedestrian trajectory into two-dimensional Gaussian distribution in images. Based on this unique description, we develop one novel trajectory prediction method, called social probability. The method combines the new probability trajectory and powerful convolution recurrent neural networks together. Both the input and output of our method are probability trajectories, which provide the recurrent neural network with sufficient spatial and random information of moving pedestrians. And the social probability extracts spatio-temporal features directly on the new movement description to generate robust and accurate predicted results. The experiments on public benchmark datasets show the effectiveness of the proposed method.