 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOPRA: Decoding Over-accumulation Penalization and Re-allocation in Specific Weighting Layer
Jul 23, 2024In this work, we introduce DOPRA, a novel approach designed to mitigate hallucinations in multi-modal large language models (MLLMs). Unlike existing solutions that typically involve costly supplementary training data or the integration of external knowledge sources, DOPRA innovatively addresses hallucinations by decoding specific weighted layer penalties and redistribution, offering an economical and effective solution without additional resources. DOPRA is grounded in unique insights into the intrinsic mechanisms controlling hallucinations within MLLMs, especially the models' tendency to over-rely on a subset of summary tokens in the self-attention matrix, neglecting critical image-related information. This phenomenon is particularly pronounced in certain strata. To counteract this over-reliance, DOPRA employs a strategy of weighted overlay penalties and redistribution in specific layers, such as the 12th layer, during the decoding process. Furthermore, DOPRA includes a retrospective allocation process that re-examines the sequence of generated tokens, allowing the algorithm to reallocate token selection to better align with the actual image content, thereby reducing the incidence of hallucinatory descriptions in auto-generated captions. Overall, DOPRA represents a significant step forward in improving the output quality of MLLMs by systematically reducing hallucinations through targeted adjustments during the decoding process.
Dynamic Hypergraph Convolutional Networks for Skeleton-Based Action Recognition
Dec 20, 2021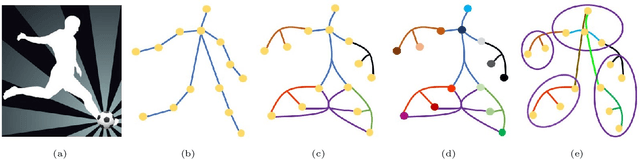
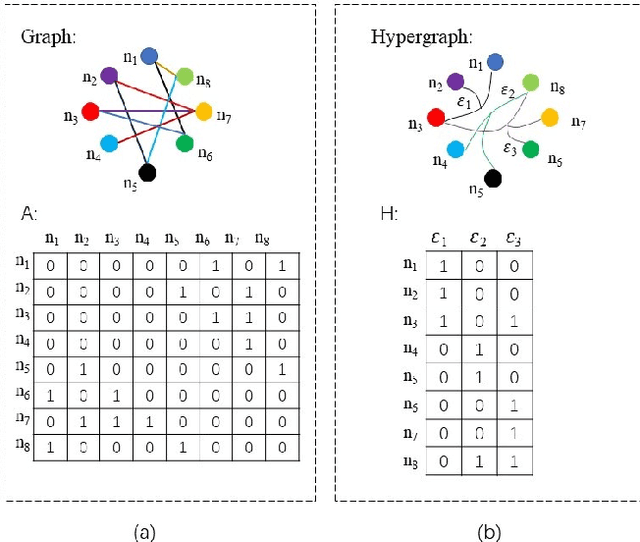
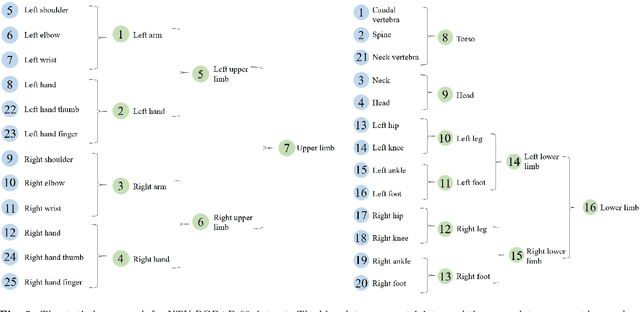
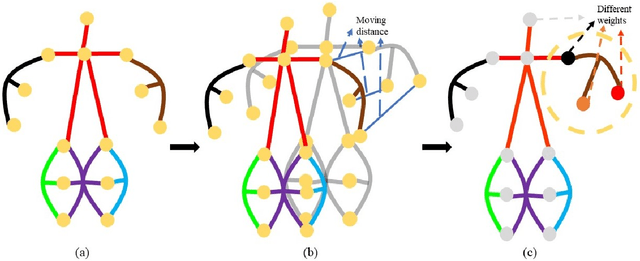
Graph convolutional networks (GCNs) based methods have achieved advanced performance on skeleton-based action recognition task. However, the skeleton graph cannot fully represent the motion information contained in skeleton data. In addition, the topology of the skeleton graph in the GCN-based methods is manually set according to natural connections, and it is fixed for all samples, which cannot well adapt to different situations. In this work, we propose a novel dynamic hypergraph convolutional networks (DHGCN) for skeleton-based action recognition. DHGCN uses hypergraph to represent the skeleton structure to effectively exploit the motion information contained in human joints. Each joint in the skeleton hypergraph is dynamically assigned the corresponding weight according to its moving, and the hypergraph topology in our model can be dynamically adjusted to different samples according to the relationship between the joints. Experimental results demonstrate that the performance of our model achieves competitive performance on three datasets: Kinetics-Skeleton 400, NTU RGB+D 60, and NTU RGB+D 120.