 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Context Aggregation Network for Lightweight Saliency Detection of Surface Defects
Sep 22, 2023



Surface defect inspection is a very challenging task in which surface defects usually show weak appearances or exist under complex backgrounds. Most high-accuracy defect detection methods require expensive computation and storage overhead, making them less practical in some resource-constrained defect detection applications. Although some lightweight methods have achieved real-time inference speed with fewer parameters, they show poor detection accuracy in complex defect scenarios. To this end, we develop a Global Context Aggregation Network (GCANet) for lightweight saliency detection of surface defects on the encoder-decoder structure. First, we introduce a novel transformer encoder on the top layer of the lightweight backbone, which captures global context information through a novel Depth-wise Self-Attention (DSA) module. The proposed DSA performs element-wise similarity in channel dimension while maintaining linear complexity. In addition, we introduce a novel Channel Reference Attention (CRA) module before each decoder block to strengthen the representation of multi-level features in the bottom-up path. The proposed CRA exploits the channel correlation between features at different layers to adaptively enhance feature representation. The experimental results on three public defect datasets demonstrate that the proposed network achieves a better trade-off between accuracy and running efficiency compared with other 17 state-of-the-art methods. Specifically, GCANet achieves competitive accuracy (91.79% $F_{\beta}^{w}$, 93.55% $S_\alpha$, and 97.35% $E_\phi$) on SD-saliency-900 while running 272fps on a single gpu.
Contrastive Proposal Extension with LSTM Network for Weakly Supervised Object Detection
Oct 16, 2021


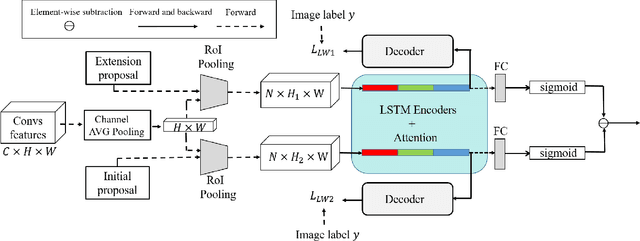
Weakly supervised object detection (WSOD) has attracted more and more attention since it only uses image-level labels and can save huge annotation costs. Most of the WSOD methods use Multiple Instance Learning (MIL) as their basic framework, which regard it as an instance classification problem. However, these methods based on MIL tends to converge only on the most discriminate regions of different instances, rather than their corresponding complete regions, that is, insufficient integrity. Inspired by the habit of observing things by the human, we propose a new method by comparing the initial proposals and the extension ones to optimize those initial proposals. Specifically, we propose one new strategy for WSOD by involving contrastive proposal extension (CPE), which consists of multiple directional contrastive proposal extensions (D-CPE), and each D-CPE contains encoders based on LSTM network and corresponding decoders. Firstly, the boundary of initial proposals in MIL is extended to different positions according to well-designed sequential order. Then, CPE compares the extended proposal and the initial proposal by extracting the feature semantics of them using the encoders, and calculates the integrity of the initial proposal to optimize the score of the initial proposal. These contrastive contextual semantics will guide the basic WSOD to suppress bad proposals and improve the scores of good ones. In addition, a simple two-stream network is designed as the decoder to constrain the temporal coding of LSTM and improve the performance of WSOD further. Experiments on PASCAL VOC 2007, VOC 2012 and MS-COCO datasets show that our method has achieved the state-of-the-art results.
Multi-scale discriminative Region Discovery for Weakly-Supervised Object Localization
Sep 24, 2019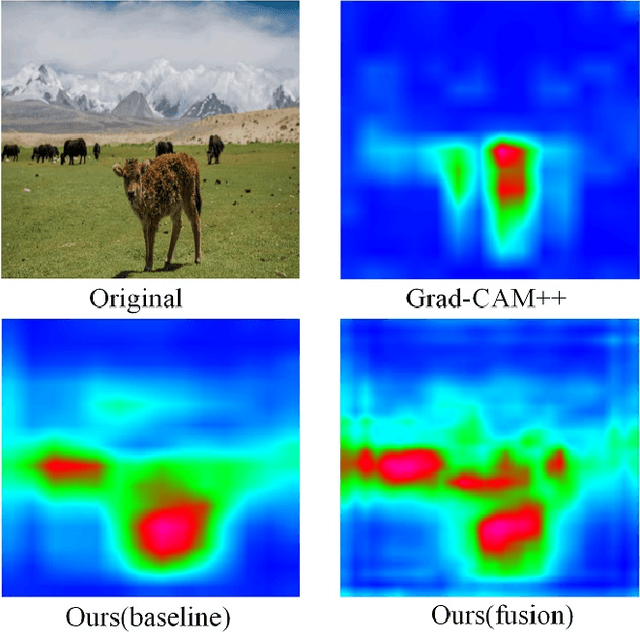
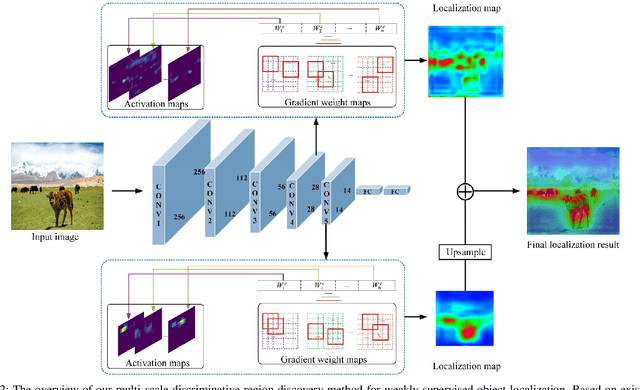
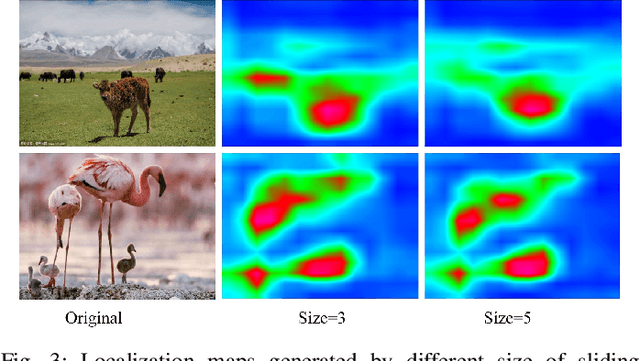
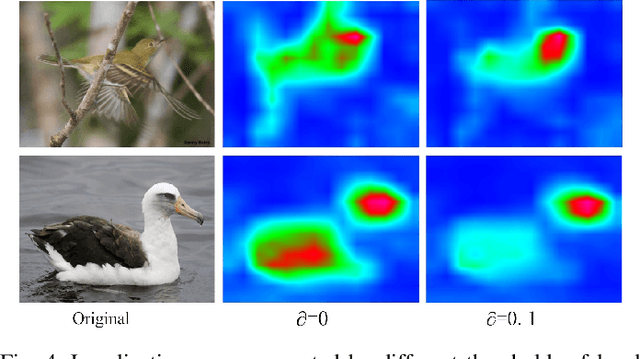
Localizing objects with weak supervision in an image is a key problem of the research in computer vision community. Many existing Weakly-Supervised Object Localization (WSOL) approaches tackle this problem by estimating the most discriminative regions with feature maps (activation maps) obtained by Deep Convolutional Neural Network, that is, only the objects or parts of them with the most discriminative response will be located. However, the activation maps often display different local maximum responses or relatively weak response when one image contains multiple objects with the same type or small objects. In this paper, we propose a simple yet effective multi-scale discriminative region discovery method to localize not only more integral objects but also as many as possible with only image-level class labels. The gradient weights flowing into different convolutional layers of CNN are taken as the input of our method, which is different from previous methods only considering that of the final convolutional layer. To mine more discriminative regions for the task of object localization, the multiple local maximum from the gradient weight maps are leveraged to generate the localization map with a parallel sliding window. Furthermore, multi-scale localization maps from different convolutional layers are fused to produce the final result. We evaluate the proposed method with the foundation of VGGnet on the ILSVRC 2016, CUB-200-2011 and PASCAL VOC 2012 datasets. On ILSVRC 2016, the proposed method yields the Top-1 localization error of 48.65\%, which outperforms previous results by 2.75\%. On PASCAL VOC 2012, our approach achieve the highest localization accuracy of 0.43. Even for CUB-200-2011 dataset, our method still achieves competitive results.
MDSSD: Multi-scale Deconvolutional Single Shot Detector for Small Objects
Aug 19, 2018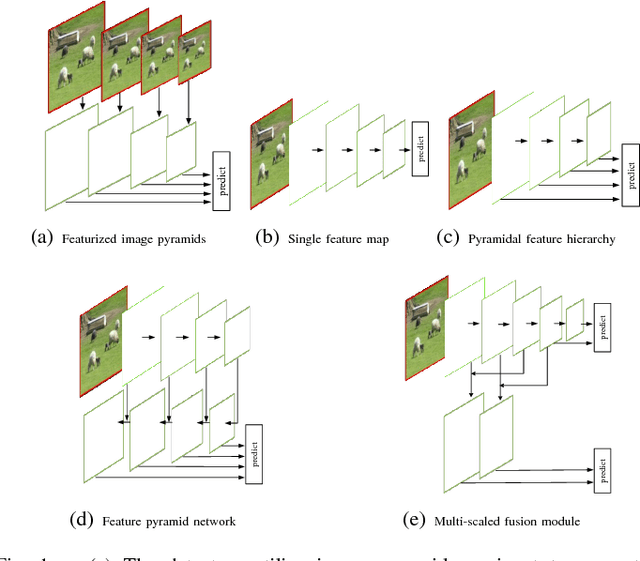

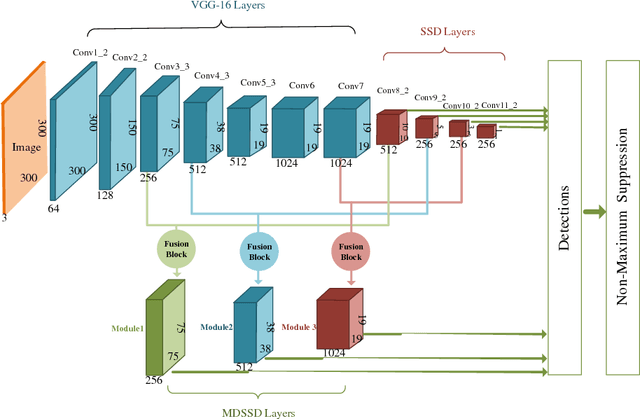
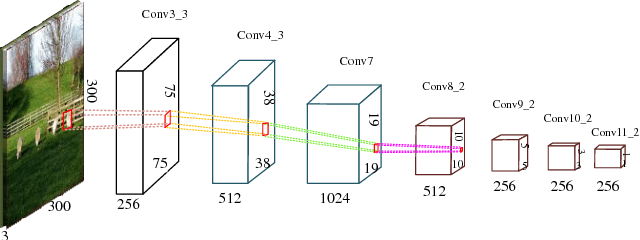
For most of the object detectors based on multi-scale feature maps, the shallow layers are mainly responsible for small object detection due to their fine details. However, the performance of detecting small object instances is still less satisfactory because of the deficiency of semantic information on shallow features. For the top semantic features, the representation of fine details for small objects are potentially wiped out. In this paper, we design a Multi-scale Deconvolutional Single Shot Detector (MDSSD), especially for the detection of small objects. In MDSSD, to generate features with strong representational power for small object instances, we add the high-level features with rich semantic information to the low-level features via deconvolution Fusion Block. It is noteworthy that multiple high-level features with different scales are upsampled simultaneously in our framework. Afterwards, we implement the skip connections to form more descriptive feature maps for small objects and predictions are made on these new fusion features. Our proposed framework achieves 78.6% mAP on PASCAL VOC2007 test and 26.8% mAP on MS COCO test-dev2015 at 38.5 FPS with only 300*300 input. The results outperform baseline SSD by 1.1 and 1.7 points respectively, especially with 2 -- 5 points improvement on some small objects categories.