 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer Guided Geometry Model for Flow-Based Unsupervised Visual Odometry
Paper and Code
Dec 08, 2020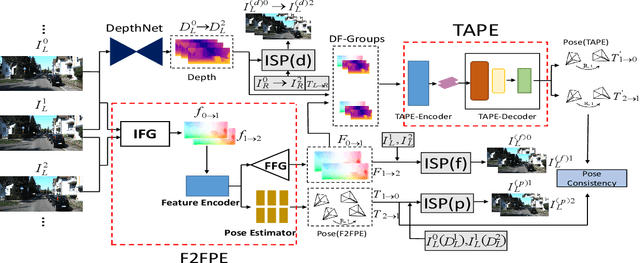
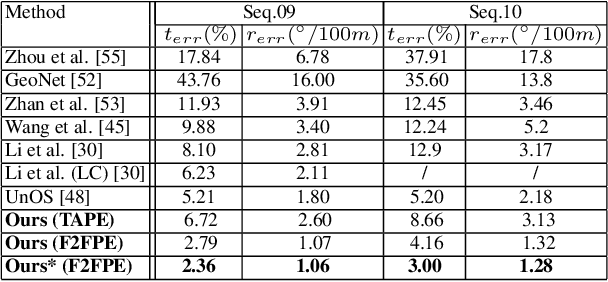
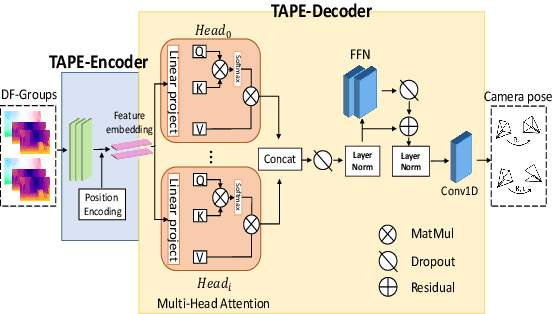
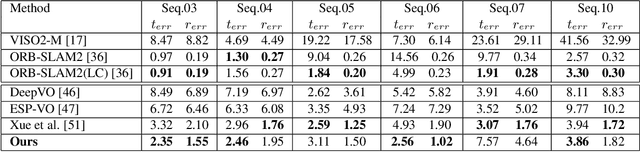
Existing unsupervised visual odometry (VO) methods either match pairwise images or integrate the temporal information using recurrent neural networks over a long sequence of images. They are either not accurate, time-consuming in training or error accumulative. In this paper, we propose a method consisting of two camera pose estimators that deal with the information from pairwise images and a short sequence of images respectively. For image sequences, a Transformer-like structure is adopted to build a geometry model over a local temporal window, referred to as Transformer-based Auxiliary Pose Estimator (TAPE). Meanwhile, a Flow-to-Flow Pose Estimator (F2FPE) is proposed to exploit the relationship between pairwise images. The two estimators are constrained through a simple yet effective consistency loss in training. Empirical evaluation has shown that the proposed method outperforms the state-of-the-art unsupervised learning-based methods by a large margin and performs comparably to supervised and traditional ones on the KITTI and Malaga dataset.