 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHPCAgentTester: A Multi-Agent LLM Approach for Enhanced HPC Unit Test Generation
Nov 13, 2025Unit testing in High-Performance Computing (HPC) is critical but challenged by parallelism, complex algorithms, and diverse hardware. Traditional methods often fail to address non-deterministic behavior and synchronization issues in HPC applications. This paper introduces HPCAgentTester, a novel multi-agent Large Language Model (LLM) framework designed to automate and enhance unit test generation for HPC software utilizing OpenMP and MPI. HPCAgentTester employs a unique collaborative workflow where specialized LLM agents (Recipe Agent and Test Agent) iteratively generate and refine test cases through a critique loop. This architecture enables the generation of context-aware unit tests that specifically target parallel execution constructs, complex communication patterns, and hierarchical parallelism. We demonstrate HPCAgentTester's ability to produce compilable and functionally correct tests for OpenMP and MPI primitives, effectively identifying subtle bugs that are often missed by conventional techniques. Our evaluation shows that HPCAgentTester significantly improves test compilation rates and correctness compared to standalone LLMs, offering a more robust and scalable solution for ensuring the reliability of parallel software systems.
Governance Challenges in Reinforcement Learning from Human Feedback: Evaluator Rationality and Reinforcement Stability
Apr 17, 2025


Reinforcement Learning from Human Feedback (RLHF) is central in aligning large language models (LLMs) with human values and expectations. However, the process remains susceptible to governance challenges, including evaluator bias, inconsistency, and the unreliability of feedback. This study examines how the cognitive capacity of evaluators, specifically their level of rationality, affects the stability of reinforcement signals. A controlled experiment comparing high-rationality and low-rationality participants reveals that evaluators with higher rationality scores produce significantly more consistent and expert-aligned feedback. In contrast, lower-rationality participants demonstrate considerable variability in their reinforcement decisions ($p < 0.01$). To address these challenges and improve RLHF governance, we recommend implementing evaluator pre-screening, systematic auditing of feedback consistency, and reliability-weighted reinforcement aggregation. These measures enhance the fairness, transparency, and robustness of AI alignment pipelines.
Synthesizing Public Opinions with LLMs: Role Creation, Impacts, and the Future to eDemorcacy
Mar 31, 2025This paper investigates the use of Large Language Models (LLMs) to synthesize public opinion data, addressing challenges in traditional survey methods like declining response rates and non-response bias. We introduce a novel technique: role creation based on knowledge injection, a form of in-context learning that leverages RAG and specified personality profiles from the HEXACO model and demographic information, and uses that for dynamically generated prompts. This method allows LLMs to simulate diverse opinions more accurately than existing prompt engineering approaches. We compare our results with pre-trained models with standard few-shot prompts. Experiments using questions from the Cooperative Election Study (CES) demonstrate that our role-creation approach significantly improves the alignment of LLM-generated opinions with real-world human survey responses, increasing answer adherence. In addition, we discuss challenges, limitations and future research directions.
Collaboration is all you need: LLM Assisted Safe Code Translation
Mar 14, 2025This paper introduces UniTranslator, a visionary framework that re-imagines code translation as a collaborative endeavor among multiple, compact LLMs. By orchestrating the interaction of specialized agents, each focused on different aspects of the translation process and grounded in a deep understanding of programming concepts, UniTranslator achieves a level of accuracy and efficiency that rivals larger, monolithic models. Our preliminary evaluation demonstrates the potential of UniTranslator to overcome the limitations of existing approaches and unlock the power of smaller LLMs for complex code translation tasks. We explore the effectiveness of this dynamic multi-agent paradigm in handling diverse language pairs, including low-resource languages, and in mitigating common issues such as code artifacts and hallucinations through the use of Natural Language Inference (NLI) grounding and iterative feedback mechanisms
A Multi-Agent Framework for Automated Vulnerability Detection and Repair in Solidity and Move Smart Contracts
Feb 22, 2025The rapid growth of the blockchain ecosystem and the increasing value locked in smart contracts necessitate robust security measures. While languages like Solidity and Move aim to improve smart contract security, vulnerabilities persist. This paper presents Smartify, a novel multi-agent framework leveraging Large Language Models (LLMs) to automatically detect and repair vulnerabilities in Solidity and Move smart contracts. Unlike traditional methods that rely solely on vast pre-training datasets, Smartify employs a team of specialized agents working on different specially fine-tuned LLMs to analyze code based on underlying programming concepts and language-specific security principles. We evaluated Smartify on a dataset for Solidity and a curated dataset for Move, demonstrating its effectiveness in fixing a wide range of vulnerabilities. Our results show that Smartify (Gemma2+codegemma) achieves state-of-the-art performance, surpassing existing LLMs and enhancing general-purpose models' capabilities, such as Llama 3.1. Notably, Smartify can incorporate language-specific knowledge, such as the nuances of Move, without requiring massive language-specific pre-training datasets. This work offers a detailed analysis of various LLMs' performance on smart contract repair, highlighting the strengths of our multi-agent approach and providing a blueprint for developing more secure and reliable decentralized applications in the growing blockchain landscape. We also provide a detailed recipe for extending this to other similar use cases.
LogBabylon: A Unified Framework for Cross-Log File Integration and Analysis
Dec 16, 2024Logs are critical resources that record events, activities, or messages produced by software applications, operating systems, servers, and network devices. However, consolidating the heterogeneous logs and cross-referencing them is challenging and complicated. Manually analyzing the log data is time-consuming and prone to errors. LogBabylon is a centralized log data consolidating solution that leverages Large Language Models (LLMs) integrated with Retrieval-Augmented Generation (RAG) technology. LogBabylon interprets the log data in a human-readable way and adds insight analysis of the system performance and anomaly alerts. It provides a paramount view of the system landscape, enabling proactive management and rapid incident response. LogBabylon consolidates diverse log sources and enhances the extracted information's accuracy and relevancy. This facilitates a deeper understanding of log data, supporting more effective decision-making and operational efficiency. Furthermore, LogBabylon streamlines the log analysis process, significantly reducing the time and effort required to interpret complex datasets. Its capabilities extend to generating context-aware insights, offering an invaluable tool for continuous monitoring, performance optimization, and security assurance in dynamic computing environments.
Harnessing the Power of LLMs: Automating Unit Test Generation for High-Performance Computing
Jul 06, 2024

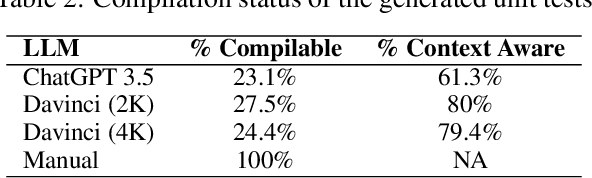
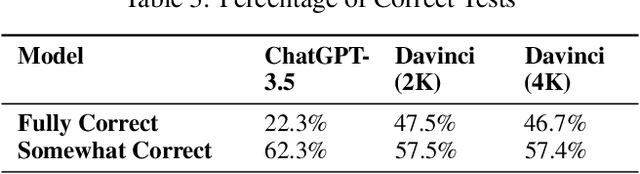
Unit testing is crucial in software engineering for ensuring quality. However, it's not widely used in parallel and high-performance computing software, particularly scientific applications, due to their smaller, diverse user base and complex logic. These factors make unit testing challenging and expensive, as it requires specialized knowledge and existing automated tools are often ineffective. To address this, we propose an automated method for generating unit tests for such software, considering their unique features like complex logic and parallel processing. Recently, large language models (LLMs) have shown promise in coding and testing. We explored the capabilities of Davinci (text-davinci-002) and ChatGPT (gpt-3.5-turbo) in creating unit tests for C++ parallel programs. Our results show that LLMs can generate mostly correct and comprehensive unit tests, although they have some limitations, such as repetitive assertions and blank test cases.
LookALike: Human Mimicry based collaborative decision making
Mar 16, 2024Artificial General Intelligence falls short when communicating role specific nuances to other systems. This is more pronounced when building autonomous LLM agents capable and designed to communicate with each other for real world problem solving. Humans can communicate context and domain specific nuances along with knowledge, and that has led to refinement of skills. In this work we propose and evaluate a novel method that leads to knowledge distillation among LLM agents leading to realtime human role play preserving unique contexts without relying on any stored data or pretraining. We also evaluate how our system performs better in simulated real world tasks compared to state of the art.
Teaching Machines to Code: Smart Contract Translation with LLMs
Mar 13, 2024
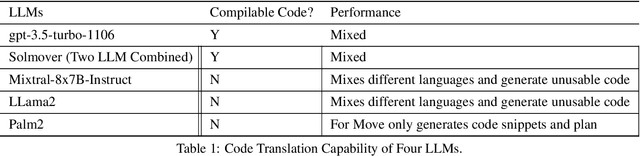


The advent of large language models (LLMs) has marked a significant milestone in the realm of artificial intelligence, with their capabilities often matching or surpassing human expertise in various domains. Among these achievements, their adeptness in translation tasks stands out, closely mimicking the intricate and preliminary processes undertaken by human translators to ensure the fidelity and quality of the translated content. Despite the advancements in utilizing LLMs for translating programming code across different languages, the domain of smart contract translation, particularly into languages not previously encountered by the LLM, remains largely unexplored. In our research, we present a pioneering approach, SolMover, which harnesses the synergy of two distinct LLMs within a unified framework. This framework is designed to grasp coding principles and apply this understanding to the translation of code into an unfamiliar language. Our study delves into the capacity of LLMs to mimic human learning processes, offering an in-depth evaluation of our methodology for converting smart contracts written in Solidity to Move, a language with limited resources. The framework employs one LLM to decipher coding conventions for the new language, creating a blueprint for the second LLM, which, lacking planning abilities, possesses coding expertise. The empirical evidence from our experiments suggests that SolMover substantially enhances performance compared to gpt-3.5-turbo-1106, and achieves superior results over competitors such as Palm2 and Mixtral-8x7B-Instruct. Additionally, our analysis highlights the efficacy of our bug mitigation strategy in elevating code quality across all models, even outside the SolMover framework.
An Empirical Study of AI-based Smart Contract Creation
Aug 19, 2023



The introduction of large language models (LLMs) like ChatGPT and Google Palm2 for smart contract generation seems to be the first well-established instance of an AI pair programmer. LLMs have access to a large number of open-source smart contracts, enabling them to utilize more extensive code in Solidity than other code generation tools. Although the initial and informal assessments of LLMs for smart contract generation are promising, a systematic evaluation is needed to explore the limits and benefits of these models. The main objective of this study is to assess the quality of generated code provided by LLMs for smart contracts. We also aim to evaluate the impact of the quality and variety of input parameters fed to LLMs. To achieve this aim, we created an experimental setup for evaluating the generated code in terms of validity, correctness, and efficiency. Our study finds crucial evidence of security bugs getting introduced in the generated smart contracts as well as the overall quality and correctness of the code getting impacted. However, we also identified the areas where it can be improved. The paper also proposes several potential research directions to improve the process, quality and safety of generated smart contract codes.