 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGovernance Challenges in Reinforcement Learning from Human Feedback: Evaluator Rationality and Reinforcement Stability
Apr 17, 2025


Reinforcement Learning from Human Feedback (RLHF) is central in aligning large language models (LLMs) with human values and expectations. However, the process remains susceptible to governance challenges, including evaluator bias, inconsistency, and the unreliability of feedback. This study examines how the cognitive capacity of evaluators, specifically their level of rationality, affects the stability of reinforcement signals. A controlled experiment comparing high-rationality and low-rationality participants reveals that evaluators with higher rationality scores produce significantly more consistent and expert-aligned feedback. In contrast, lower-rationality participants demonstrate considerable variability in their reinforcement decisions ($p < 0.01$). To address these challenges and improve RLHF governance, we recommend implementing evaluator pre-screening, systematic auditing of feedback consistency, and reliability-weighted reinforcement aggregation. These measures enhance the fairness, transparency, and robustness of AI alignment pipelines.
LogBabylon: A Unified Framework for Cross-Log File Integration and Analysis
Dec 16, 2024Logs are critical resources that record events, activities, or messages produced by software applications, operating systems, servers, and network devices. However, consolidating the heterogeneous logs and cross-referencing them is challenging and complicated. Manually analyzing the log data is time-consuming and prone to errors. LogBabylon is a centralized log data consolidating solution that leverages Large Language Models (LLMs) integrated with Retrieval-Augmented Generation (RAG) technology. LogBabylon interprets the log data in a human-readable way and adds insight analysis of the system performance and anomaly alerts. It provides a paramount view of the system landscape, enabling proactive management and rapid incident response. LogBabylon consolidates diverse log sources and enhances the extracted information's accuracy and relevancy. This facilitates a deeper understanding of log data, supporting more effective decision-making and operational efficiency. Furthermore, LogBabylon streamlines the log analysis process, significantly reducing the time and effort required to interpret complex datasets. Its capabilities extend to generating context-aware insights, offering an invaluable tool for continuous monitoring, performance optimization, and security assurance in dynamic computing environments.
Detecting Conspiracy Theory Against COVID-19 Vaccines
Nov 20, 2022



Since the beginning of the vaccination trial, social media has been flooded with anti-vaccination comments and conspiracy beliefs. As the day passes, the number of COVID- 19 cases increases, and online platforms and a few news portals entertain sharing different conspiracy theories. The most popular conspiracy belief was the link between the 5G network spreading COVID-19 and the Chinese government spreading the virus as a bioweapon, which initially created racial hatred. Although some disbelief has less impact on society, others create massive destruction. For example, the 5G conspiracy led to the burn of the 5G Tower, and belief in the Chinese bioweapon story promoted an attack on the Asian-Americans. Another popular conspiracy belief was that Bill Gates spread this Coronavirus disease (COVID-19) by launching a mass vaccination program to track everyone. This Conspiracy belief creates distrust issues among laypeople and creates vaccine hesitancy. This study aims to discover the conspiracy theory against the vaccine on social platforms. We performed a sentiment analysis on the 598 unique sample comments related to COVID-19 vaccines. We used two different models, BERT and Perspective API, to find out the sentiment and toxicity of the sentence toward the COVID-19 vaccine.
Counter Hate Speech in Social Media: A Survey
Feb 21, 2022With the high prevalence of offensive language against minorities in social media, counter-hate speeches (CHS) generation is considered an automatic way of tackling this challenge. The CHS is supposed to appear as a third voice to educate people and keep the social [red lines bold] without limiting the principles of freedom of speech. In this paper, we review the most important research in the past and present with a main focus on methodologies, collected datasets and statistical analysis CHS's impact on social media. The CHS generation is based on the optimistic assumption that any attempt to intervene the hate speech in social media can play a positive role in this context. Beyond that, previous works ignored the investigation of the sequence of comments before and after the CHS. However, the positive impact is not guaranteed, as shown in some previous works. To the best of our knowledge, no attempt has been made to survey the related work to compare the past research in terms of CHS's impact on social media. We take the first step in this direction by providing a comprehensive review on related works and categorizing them based on different factors including impact, methodology, data source, etc.
Hate Speech Detection in Clubhouse
Jul 11, 2021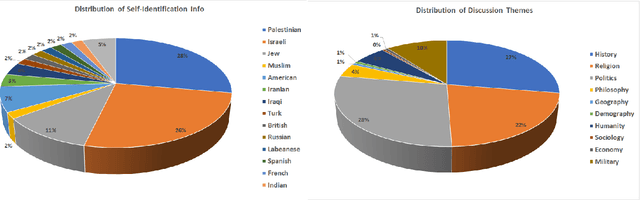

With the rise of voice chat rooms, a gigantic resource of data can be exposed to the research community for natural language processing tasks. Moderators in voice chat rooms actively monitor the discussions and remove the participants with offensive language. However, it makes the hate speech detection even more difficult since some participants try to find creative ways to articulate hate speech. This makes the hate speech detection challenging in new social media like Clubhouse. To the best of our knowledge all the hate speech datasets have been collected from text resources like Twitter. In this paper, we take the first step to collect a significant dataset from Clubhouse as the rising star in social media industry. We analyze the collected instances from statistical point of view using the Google Perspective Scores. Our experiments show that, the Perspective Scores can outperform Bag of Words and Word2Vec as high level text features.
Statistical Analysis of Perspective Scores on Hate Speech Detection
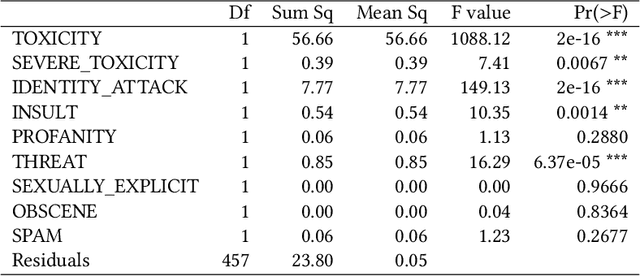
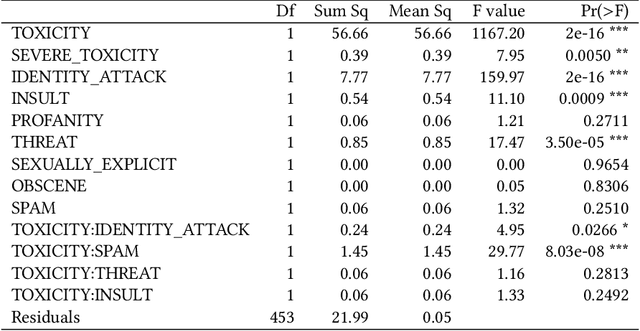
Jun 22, 2021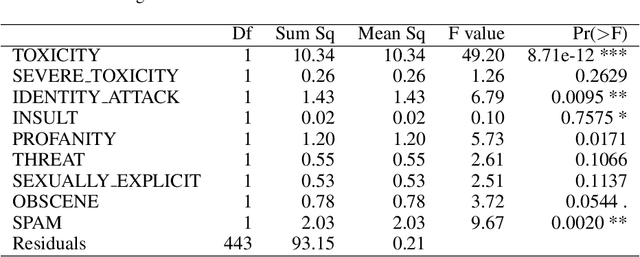
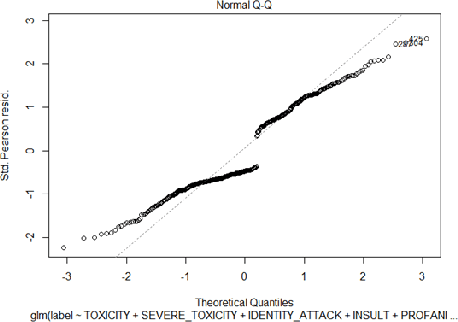
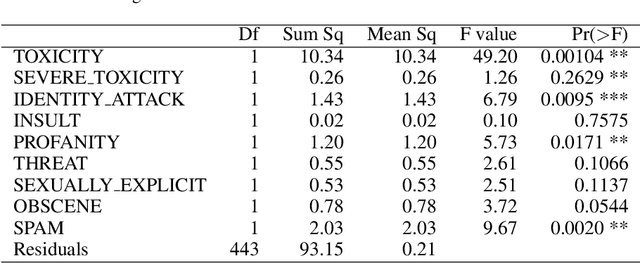
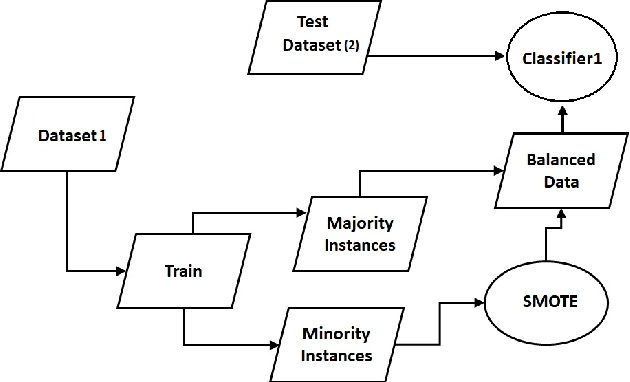
Hate speech detection has become a hot topic in recent years due to the exponential growth of offensive language in social media. It has proven that, state-of-the-art hate speech classifiers are efficient only when tested on the data with the same feature distribution as training data. As a consequence, model architecture plays the second role to improve the current results. In such a diverse data distribution relying on low level features is the main cause of deficiency due to natural bias in data. That's why we need to use high level features to avoid a biased judgement. In this paper, we statistically analyze the Perspective Scores and their impact on hate speech detection. We show that, different hate speech datasets are very similar when it comes to extract their Perspective Scores. Eventually, we prove that, over-sampling the Perspective Scores of a hate speech dataset can significantly improve the generalization performance when it comes to be tested on other hate speech datasets.