 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAN-Based Object Removal in High-Resolution Satellite Images
Jan 24, 2023Satellite images often contain a significant level of sensitive data compared to ground-view images. That is why satellite images are more likely to be intentionally manipulated to hide specific objects and structures. GAN-based approaches have been employed to create forged images with two major problems: (i) adding a new object to the scene to hide a specific object or region may create unrealistic merging with surrounding areas; and (ii) using masks on color feature images has proven to be unsuccessful in GAN-based object removal. In this paper, we tackle the problem of object removal in high-resolution satellite images given a limited number of training data. Furthermore, we take advantage of conditional GANs (CGANs) to collect perhaps the first GAN-based forged satellite image data set. All forged instances were manipulated via CGANs trained by Canny Feature Images for object removal. As part of our experiments, we demonstrate that distinguishing the collected forged images from authentic (original) images is highly challenging for fake image detector models.
Detecting Conspiracy Theory Against COVID-19 Vaccines
Nov 20, 2022



Since the beginning of the vaccination trial, social media has been flooded with anti-vaccination comments and conspiracy beliefs. As the day passes, the number of COVID- 19 cases increases, and online platforms and a few news portals entertain sharing different conspiracy theories. The most popular conspiracy belief was the link between the 5G network spreading COVID-19 and the Chinese government spreading the virus as a bioweapon, which initially created racial hatred. Although some disbelief has less impact on society, others create massive destruction. For example, the 5G conspiracy led to the burn of the 5G Tower, and belief in the Chinese bioweapon story promoted an attack on the Asian-Americans. Another popular conspiracy belief was that Bill Gates spread this Coronavirus disease (COVID-19) by launching a mass vaccination program to track everyone. This Conspiracy belief creates distrust issues among laypeople and creates vaccine hesitancy. This study aims to discover the conspiracy theory against the vaccine on social platforms. We performed a sentiment analysis on the 598 unique sample comments related to COVID-19 vaccines. We used two different models, BERT and Perspective API, to find out the sentiment and toxicity of the sentence toward the COVID-19 vaccine.
RAF: Recursive Adversarial Attacks on Face Recognition Using Extremely Limited Queries
Jul 04, 2022
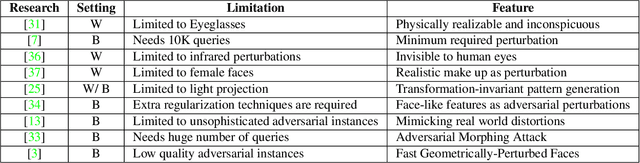


Recent successful adversarial attacks on face recognition show that, despite the remarkable progress of face recognition models, they are still far behind the human intelligence for perception and recognition. It reveals the vulnerability of deep convolutional neural networks (CNNs) as state-of-the-art building block for face recognition models against adversarial examples, which can cause certain consequences for secure systems. Gradient-based adversarial attacks are widely studied before and proved to be successful against face recognition models. However, finding the optimized perturbation per each face needs to submitting the significant number of queries to the target model. In this paper, we propose recursive adversarial attack on face recognition using automatic face warping which needs extremely limited number of queries to fool the target model. Instead of a random face warping procedure, the warping functions are applied on specific detected regions of face like eyebrows, nose, lips, etc. We evaluate the robustness of proposed method in the decision-based black-box attack setting, where the attackers have no access to the model parameters and gradients, but hard-label predictions and confidence scores are provided by the target model.
Counter Hate Speech in Social Media: A Survey
Feb 21, 2022With the high prevalence of offensive language against minorities in social media, counter-hate speeches (CHS) generation is considered an automatic way of tackling this challenge. The CHS is supposed to appear as a third voice to educate people and keep the social [red lines bold] without limiting the principles of freedom of speech. In this paper, we review the most important research in the past and present with a main focus on methodologies, collected datasets and statistical analysis CHS's impact on social media. The CHS generation is based on the optimistic assumption that any attempt to intervene the hate speech in social media can play a positive role in this context. Beyond that, previous works ignored the investigation of the sequence of comments before and after the CHS. However, the positive impact is not guaranteed, as shown in some previous works. To the best of our knowledge, no attempt has been made to survey the related work to compare the past research in terms of CHS's impact on social media. We take the first step in this direction by providing a comprehensive review on related works and categorizing them based on different factors including impact, methodology, data source, etc.
Hate Speech Detection in Clubhouse
Jul 11, 2021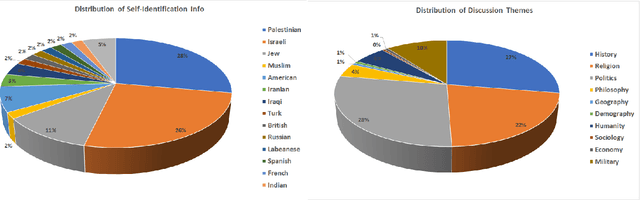

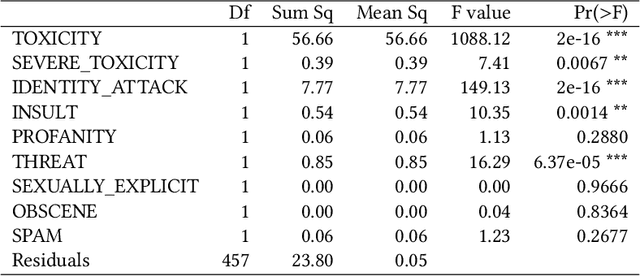
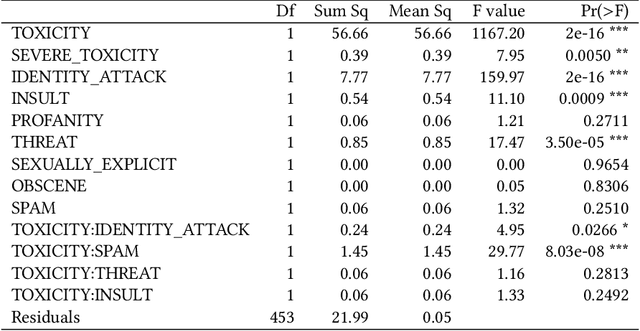
With the rise of voice chat rooms, a gigantic resource of data can be exposed to the research community for natural language processing tasks. Moderators in voice chat rooms actively monitor the discussions and remove the participants with offensive language. However, it makes the hate speech detection even more difficult since some participants try to find creative ways to articulate hate speech. This makes the hate speech detection challenging in new social media like Clubhouse. To the best of our knowledge all the hate speech datasets have been collected from text resources like Twitter. In this paper, we take the first step to collect a significant dataset from Clubhouse as the rising star in social media industry. We analyze the collected instances from statistical point of view using the Google Perspective Scores. Our experiments show that, the Perspective Scores can outperform Bag of Words and Word2Vec as high level text features.
Statistical Analysis of Perspective Scores on Hate Speech Detection
Jun 22, 2021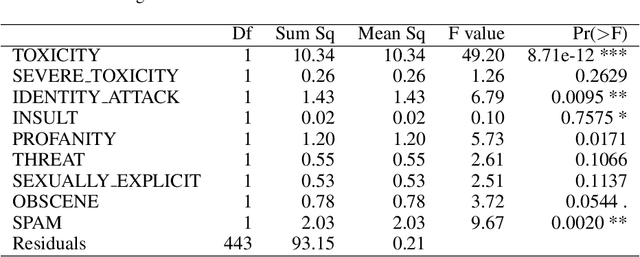
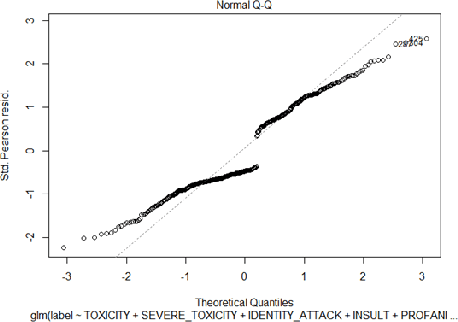
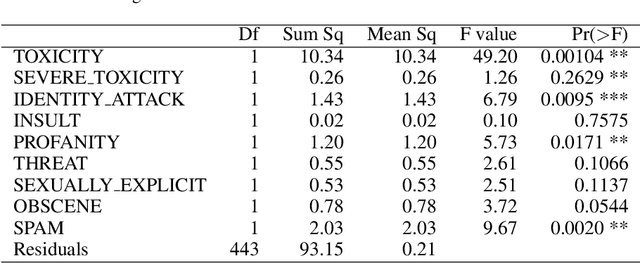
Hate speech detection has become a hot topic in recent years due to the exponential growth of offensive language in social media. It has proven that, state-of-the-art hate speech classifiers are efficient only when tested on the data with the same feature distribution as training data. As a consequence, model architecture plays the second role to improve the current results. In such a diverse data distribution relying on low level features is the main cause of deficiency due to natural bias in data. That's why we need to use high level features to avoid a biased judgement. In this paper, we statistically analyze the Perspective Scores and their impact on hate speech detection. We show that, different hate speech datasets are very similar when it comes to extract their Perspective Scores. Eventually, we prove that, over-sampling the Perspective Scores of a hate speech dataset can significantly improve the generalization performance when it comes to be tested on other hate speech datasets.
Towards Stable Imbalanced Data Classification via Virtual Big Data Projection
Aug 23, 2020



Virtual Big Data (VBD) proved to be effective to alleviate mode collapse and vanishing generator gradient as two major problems of Generative Adversarial Neural Networks (GANs) very recently. In this paper, we investigate the capability of VBD to address two other major challenges in Machine Learning including deep autoencoder training and imbalanced data classification. First, we prove that, VBD can significantly decrease the validation loss of autoencoders via providing them a huge diversified training data which is the key to reach better generalization to minimize the over-fitting problem. Second, we use the VBD to propose the first projection-based method called cross-concatenation to balance the skewed class distributions without over-sampling. We prove that, cross-concatenation can solve uncertainty problem of data driven methods for imbalanced classification.
Vulnerability of Face Recognition Systems Against Composite Face Reconstruction Attack
Aug 23, 2020


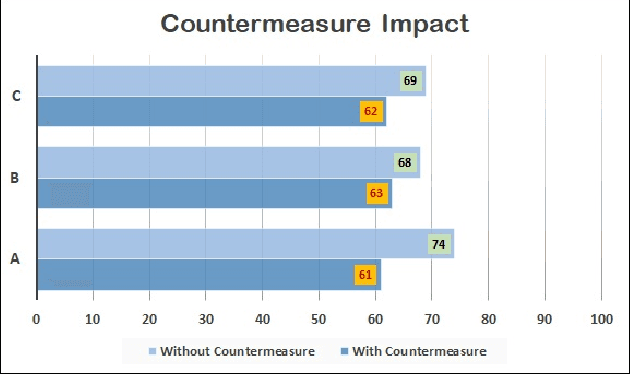
Rounding confidence score is considered trivial but a simple and effective countermeasure to stop gradient descent based image reconstruction attacks. However, its capability in the face of more sophisticated reconstruction attacks is an uninvestigated research area. In this paper, we prove that, the face reconstruction attacks based on composite faces can reveal the inefficiency of rounding policy as countermeasure. We assume that, the attacker takes advantage of face composite parts which helps the attacker to get access to the most important features of the face or decompose it to the independent segments. Afterwards, decomposed segments are exploited as search parameters to create a search path to reconstruct optimal face. Face composition parts enable the attacker to violate the privacy of face recognition models even with a blind search. However, we assume that, the attacker may take advantage of random search to reconstruct the target face faster. The algorithm is started with random composition of face parts as initial face and confidence score is considered as fitness value. Our experiments show that, since the rounding policy as countermeasure can't stop the random search process, current face recognition systems are extremely vulnerable against such sophisticated attacks. To address this problem, we successfully test Face Detection Score Filtering (FDSF) as a countermeasure to protect the privacy of training data against proposed attack.
One-Shot GAN Generated Fake Face Detection
Mar 27, 2020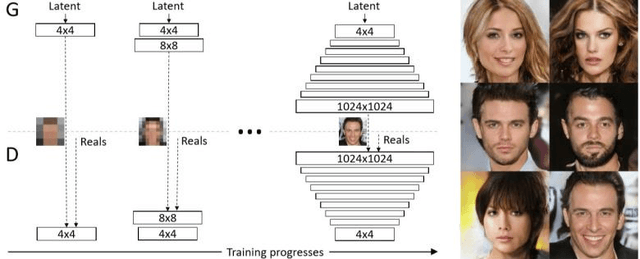
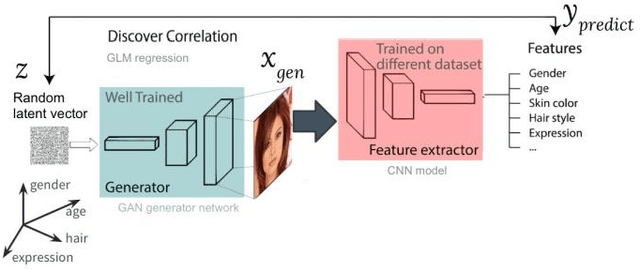


Fake face detection is a significant challenge for intelligent systems as generative models become more powerful every single day. As the quality of fake faces increases, the trained models become more and more inefficient to detect the novel fake faces, since the corresponding training data is considered outdated. In this case, robust One-Shot learning methods is more compatible with the requirements of changeable training data. In this paper, we propose a universal One-Shot GAN generated fake face detection method which can be used in significantly different areas of anomaly detection. The proposed method is based on extracting out-of-context objects from faces via scene understanding models. To do so, we use state of the art scene understanding and object detection methods as a pre-processing tool to detect the weird objects in the face. Second, we create a bag of words given all the detected out-of-context objects per all training data. This way, we transform each image into a sparse vector where each feature represents the confidence score related to each detected object in the image. Our experiments show that, we can discriminate fake faces from real ones in terms of out-of-context features. It means that, different sets of objects are detected in fake faces comparing to real ones when we analyze them with scene understanding and object detection models. We prove that, the proposed method can outperform previous methods based on our experiments on Style-GAN generated fake faces.
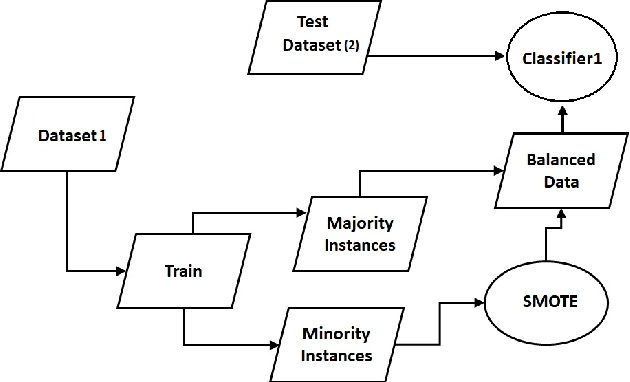
Deep Synthetic Minority Over-Sampling Technique
Mar 22, 2020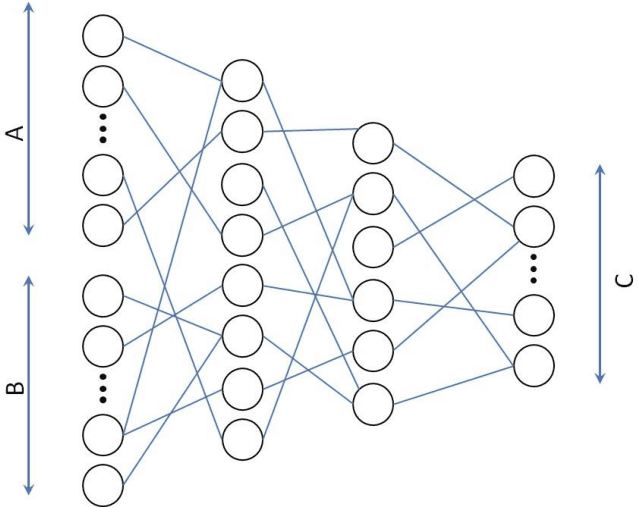
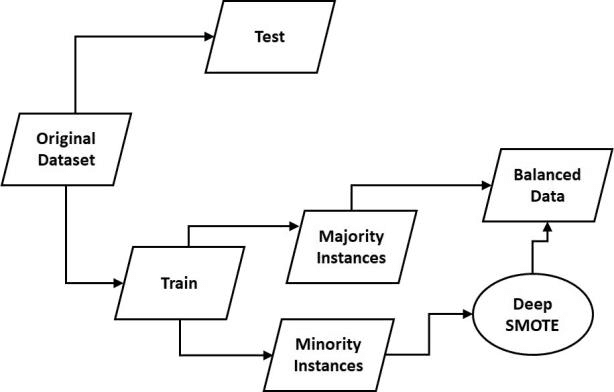
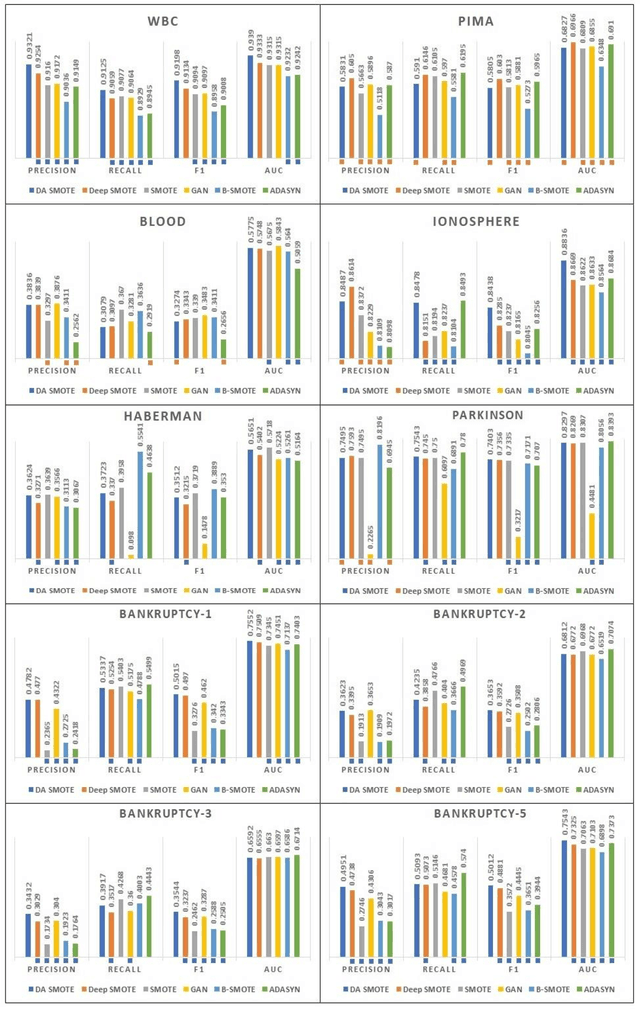
Synthetic Minority Over-sampling Technique (SMOTE) is the most popular over-sampling method. However, its random nature makes the synthesized data and even imbalanced classification results unstable. It means that in case of running SMOTE n different times, n different synthesized in-stances are obtained with n different classification results. To address this problem, we adapt the SMOTE idea in deep learning architecture. In this method, a deep neural network regression model is used to train the inputs and outputs of traditional SMOTE. Inputs of the proposed deep regression model are two randomly chosen data points which are concatenated to form a double size vector. The outputs of this model are corresponding randomly interpolated data points between two randomly chosen vectors with original dimension. The experimental results show that, Deep SMOTE can outperform traditional SMOTE in terms of precision, F1 score and Area Under Curve (AUC) in majority of test cases.