 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Analysis of Perspective Scores on Hate Speech Detection
Paper and Code
Jun 22, 2021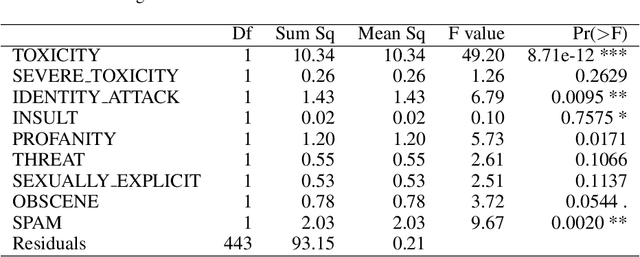
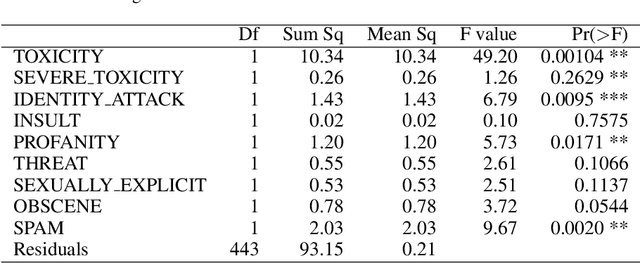
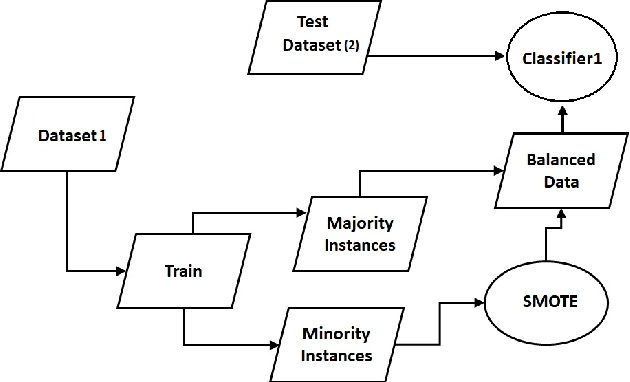
Hate speech detection has become a hot topic in recent years due to the exponential growth of offensive language in social media. It has proven that, state-of-the-art hate speech classifiers are efficient only when tested on the data with the same feature distribution as training data. As a consequence, model architecture plays the second role to improve the current results. In such a diverse data distribution relying on low level features is the main cause of deficiency due to natural bias in data. That's why we need to use high level features to avoid a biased judgement. In this paper, we statistically analyze the Perspective Scores and their impact on hate speech detection. We show that, different hate speech datasets are very similar when it comes to extract their Perspective Scores. Eventually, we prove that, over-sampling the Perspective Scores of a hate speech dataset can significantly improve the generalization performance when it comes to be tested on other hate speech datasets.