 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionMamba: Efficient Image Fusion with State Space Model
Paper and Code
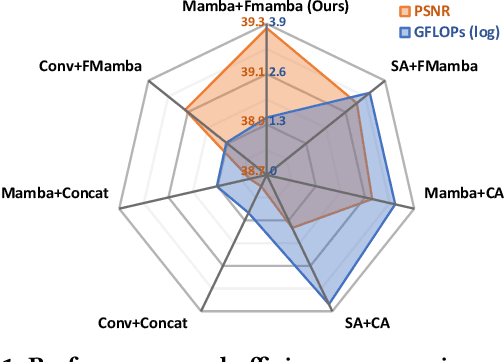
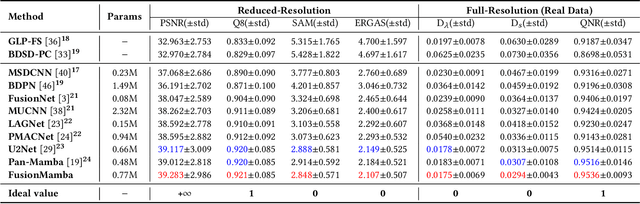
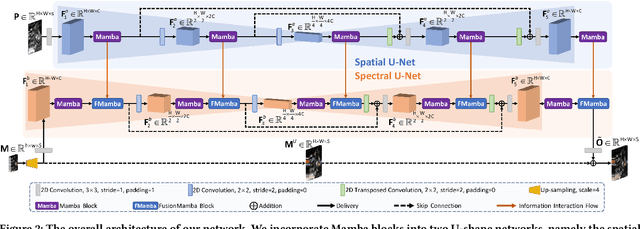
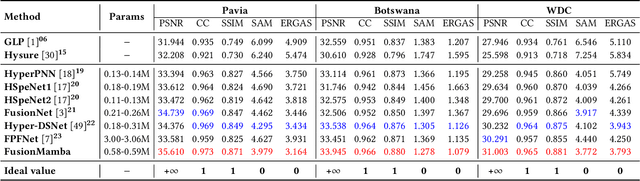
Image fusion aims to generate a high-resolution multi/hyper-spectral image by combining a high-resolution image with limited spectral information and a low-resolution image with abundant spectral data. Current deep learning (DL)-based methods for image fusion primarily rely on CNNs or Transformers to extract features and merge different types of data. While CNNs are efficient, their receptive fields are limited, restricting their capacity to capture global context. Conversely, Transformers excel at learning global information but are hindered by their quadratic complexity. Fortunately, recent advancements in the State Space Model (SSM), particularly Mamba, offer a promising solution to this issue by enabling global awareness with linear complexity. However, there have been few attempts to explore the potential of SSM in information fusion, which is a crucial ability in domains like image fusion. Therefore, we propose FusionMamba, an innovative method for efficient image fusion. Our contributions mainly focus on two aspects. Firstly, recognizing that images from different sources possess distinct properties, we incorporate Mamba blocks into two U-shaped networks, presenting a novel architecture that extracts spatial and spectral features in an efficient, independent, and hierarchical manner. Secondly, to effectively combine spatial and spectral information, we extend the Mamba block to accommodate dual inputs. This expansion leads to the creation of a new module called the FusionMamba block, which outperforms existing fusion techniques such as concatenation and cross-attention. To validate FusionMamba's effectiveness, we conduct a series of experiments on five datasets related to three image fusion tasks. The quantitative and qualitative evaluation results demonstrate that our method achieves state-of-the-art (SOTA) performance, underscoring the superiority of FusionMamba.